AWS DevOps & Developer Productivity Blog
Best Practices for Writing Step Functions Terraform Projects
Terraform by HashiCorp is one of the most popular infrastructure-as-code (IaC) platforms. AWS Step Functions is a visual workflow service that helps developers use AWS services to build distributed applications, automate processes, orchestrate microservices, and create data and machine learning (ML) pipelines. In this blog, we showcase best practices for users leveraging Terraform to deploy workflows, also known as Step Functions state machines. We will create a state machine using Workflow Studio for AWS Step Functions, deploy the state machine with Terraform, and introduce best operating practices on topics such as project structure, modules, parameter substitution, and remote state.
We recommend that you have a working understanding of both Terraform and Step Functions before going through this blog. If you are brand new to Step Functions and/or Terraform, please visit the Introduction to Terraform on AWS Workshop and the Terraform option in the Managing State Machines with Infrastructure as Code section of The AWS Step Functions Workshop to learn more.
Step Functions and Terraform Project Structure
One of the most important parts of any software project is its structure. It must be clear and well-organized for yourself or any member of your team to pick up and start coding efficiently. A Step Functions project using Terraform can potentially have many moving parts and components, so it is especially important to modularize and label wherever possible. Let’s take a look at a project structure that will allow for modularization, re-usability, and extensibility:
mkdir sfn-tf-example
cd sfn-tf-example
mkdir -p -- statemachine modules functions/first-function/src
touch main.tf outputs.tf variables.tf .gitignore functions/first-function/src/lambda.py
treeBefore moving forward, let’s analyze the directory, subdirectories, and files created above:
/statemachinewill hold our Amazon States Language (ASL) JSON code describing the Step Functions state machine definition. This is where the orchestration logic will reside, so it is prudent to keep it separated from the infrastructure code. If you are deploying multiple state machines in your project, each definition will have its own JSON file. If you prefer, you can specify separate folders for each state machine to further modularize and isolate the logic./functionssubdirectory includes the actual code for AWS Lambda functions used in our state machine. Keeping this code here will be much easier to read than writing it inline in ourmain.tffile.- The last subdirectory we have is
/modules. Terraform modules are higher level abstracts explaining new concepts in your architecture. However, do not fall into the trap of making a custom module for everything. Doing so will make your code harder to maintain, and AWS provider resources will often suffice. There are also very popular modules that you can use from the Terraform Registry, such as Terraform AWS modules. Whenever possible, one should re-use modules to avoid code duplication in your project. - The remaining files in the root of the project are common to all Terraform projects. There are going to be hidden files created by your Terraform project after running
terraform init, so we will include a.gitignore. What you include in.gitignoreis largely dependent on your codebase and what your tools silently create in the background. In a later section, we will explicitly call out*.tfstatefiles in our.gitignore, and go over best practices for managing Terraform state securely and remotely.
Initial Code and Project Setup
We are going to create a simple Step Functions state machine that will only execute a single Lambda function. However, we will need to create the Lambda function that the state machine will reference. We first need to create our Lambda function code and save it in the following the directory structure and file mentioned above: functions/first-function/src/lambda.py.
import boto3
def lambda_handler(event, context):
# Minimal function for demo purposes
return TrueIn Terraform, the main configuration file is named main.tf. This is the file that the Terraform CLI will look for in the local directory. Although you can break down your template into multiple .tf files, main.tf must be one of them. In this file, we will define the required providers and their minimum version, along with the resource definition of our template. In the example below, we define the minimum resources needed for a simple state machine that only executes a Lambda function. We define the two AWS Identity and Access Management (IAM) roles that our Lambda function and state machine will use, respectively. We define a data resource that zips the Lambda function code, which is then used in the Lambda function definition. Also notice that we use the aws_iam_policy_document data source throughout. Using the official IAM policy document means both your integrated development environment (IDE) and Terraform can see if your policy is malformed before running terraform apply. Finally, we define an Amazon CloudWatch Log group that will be used by the Lambda function to store its execution logs.
Terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~>4.0"
}
}
}
provider "aws" {}
provider "random" {}
data "aws_caller_identity" "current_account" {}
data "aws_region" "current_region" {}
resource "random_string" "random" {
length = 4
special = false
}
data "aws_iam_policy_document" "lambda_assume_role_policy" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
actions = [
"sts:AssumeRole",
]
}
}
resource "aws_iam_role" "function_role" {
assume_role_policy = data.aws_iam_policy_document.lambda_assume_role_policy.json
managed_policy_arns = ["arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"]
}
# Create the function
data "archive_file" "lambda" {
type = "zip"
source_file = "functions/first-function/src/lambda.py"
output_path = "functions/first-function/src/lambda.zip"
}
resource "aws_kms_key" "log_group_key" {}
resource "aws_kms_key_policy" "log_group_key_policy" {
key_id = aws_kms_key.log_group_key.id
policy = jsonencode({
Id = "log_group_key_policy"
Statement = [
{
Action = "kms:*"
Effect = "Allow"
Principal = {
AWS = "arn:aws:iam::${data.aws_caller_identity.current_account.account_id}:root"
}
Resource = "*"
Sid = "Enable IAM User Permissions"
},
{
Effect = "Allow",
Principal = {
Service : "logs.${data.aws_region.current_region.name}.amazonaws.com"
},
Action = [
"kms:Encrypt*",
"kms:Decrypt*",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:Describe*"
],
Resource = "*"
}
]
Version = "2012-10-17"
})
}
resource "aws_lambda_function" "test_lambda" {
function_name = "HelloFunction-${random_string.random.id}"
role = aws_iam_role.function_role.arn
handler = "lambda.lambda_handler"
runtime = "python3.9"
filename = "functions/first-function/src/lambda.zip"
source_code_hash = data.archive_file.lambda.output_base64sha256
}
# Explicitly create the function’s log group to set retention and allow auto-cleanup
resource "aws_cloudwatch_log_group" "lambda_function_log" {
retention_in_days = 1
name = "/aws/lambda/${aws_lambda_function.test_lambda.function_name}"
kms_key_id = aws_kms_key.log_group_key.arn
}
# Create an IAM role for the Step Functions state machine
data "aws_iam_policy_document" "state_machine_assume_role_policy" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["states.amazonaws.com"]
}
actions = [
"sts:AssumeRole",
]
}
}
resource "aws_iam_role" "StateMachineRole" {
name = "StepFunctions-Terraform-Role-${random_string.random.id}"
assume_role_policy = data.aws_iam_policy_document.state_machine_assume_role_policy.json
}
data "aws_iam_policy_document" "state_machine_role_policy" {
statement {
effect = "Allow"
actions = [
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogGroups"
]
resources = ["${aws_cloudwatch_log_group.MySFNLogGroup.arn}:*"]
}
statement {
effect = "Allow"
actions = [
"cloudwatch:PutMetricData",
"logs:CreateLogDelivery",
"logs:GetLogDelivery",
"logs:UpdateLogDelivery",
"logs:DeleteLogDelivery",
"logs:ListLogDeliveries",
"logs:PutResourcePolicy",
"logs:DescribeResourcePolicies",
]
resources = ["*"]
}
statement {
effect = "Allow"
actions = [
"lambda:InvokeFunction"
]
resources = ["${aws_lambda_function.test_lambda.arn}"]
}
}
# Create an IAM policy for the Step Functions state machine
resource "aws_iam_role_policy" "StateMachinePolicy" {
role = aws_iam_role.StateMachineRole.id
policy = data.aws_iam_policy_document.state_machine_role_policy.json
}
# Create a Log group for the state machine
resource "aws_cloudwatch_log_group" "MySFNLogGroup" {
name_prefix = "/aws/vendedlogs/states/MyStateMachine-"
retention_in_days = 1
kms_key_id = aws_kms_key.log_group_key.arn
}Workflow Studio and Terraform Integration
It is important to understand the recommended steps given the different tools we have available for creating Step Functions state machines. You should use a combination of Workflow Studio and local development with Terraform. This workflow assumes you will define all resources for your application within the same Terraform project, and that you will be leveraging Terraform for managing your AWS resources.

Figure 1 – Workflow for creating Step Functions state machine via Terraform
- You will write the Terraform definition for any resources you intend to call with your state machine, such as Lambda functions, Amazon Simple Storage Service (Amazon S3) buckets, or Amazon DynamoDB tables, and deploy them using the
terraform applycommand. Doing this prior to using Workflow Studio will be useful in designing the first version of the state machine. You can define additional resources after importing the state machine into your local Terraform project. - You can use Workflow Studio to visually design the first version of the state machine. Given that you should have created the necessary resources already, you can drag and drop all of the actions and states, link them, and see how they look. Finally, you can execute the state machine for testing purposes.
- Once your initial design is ready, you will export the ASL file and save it in your Terraform project. You can use the Terraform resource type
aws_sfn_state_machineand reference the saved ASL file in thedefinitionfield. - You will then need to parametrize the ASL file given that Terraform will dynamically name the resources, and the Amazon Resource Name (ARN) may eventually change. You do not want to hardcode an ARN in your ASL file, as this will make updating and refactoring your code more difficult.
- Finally, you deploy the state machine via Terraform by running
terraform apply.
Simple changes should be made directly in the parametrized ASL file in your Terraform project instead of going back to Workflow Studio. Having the ASL file versioned as part of your project ensures that no manual changes break the state machine. Even if there is a breaking change, you can easily roll back to a previous version. One caveat to this is if you are making major changes to the state machine. In this case, taking advantage of Workflow Studio in the console is preferable.
However, you will most likely want to continue seeing a visual representation of the state machine while developing locally. The good news is that you have another option directly integrated into Visual Studio Code (VS Code) that visually renders the state machine, similar to Workflow Studio. This functionality is part of the AWS Toolkit for VS Code. You can learn more about the state machine integration with the AWS Toolkit for VS Code here. Below is an example of a parametrized ASL file and its rendered visualization in VS Code.
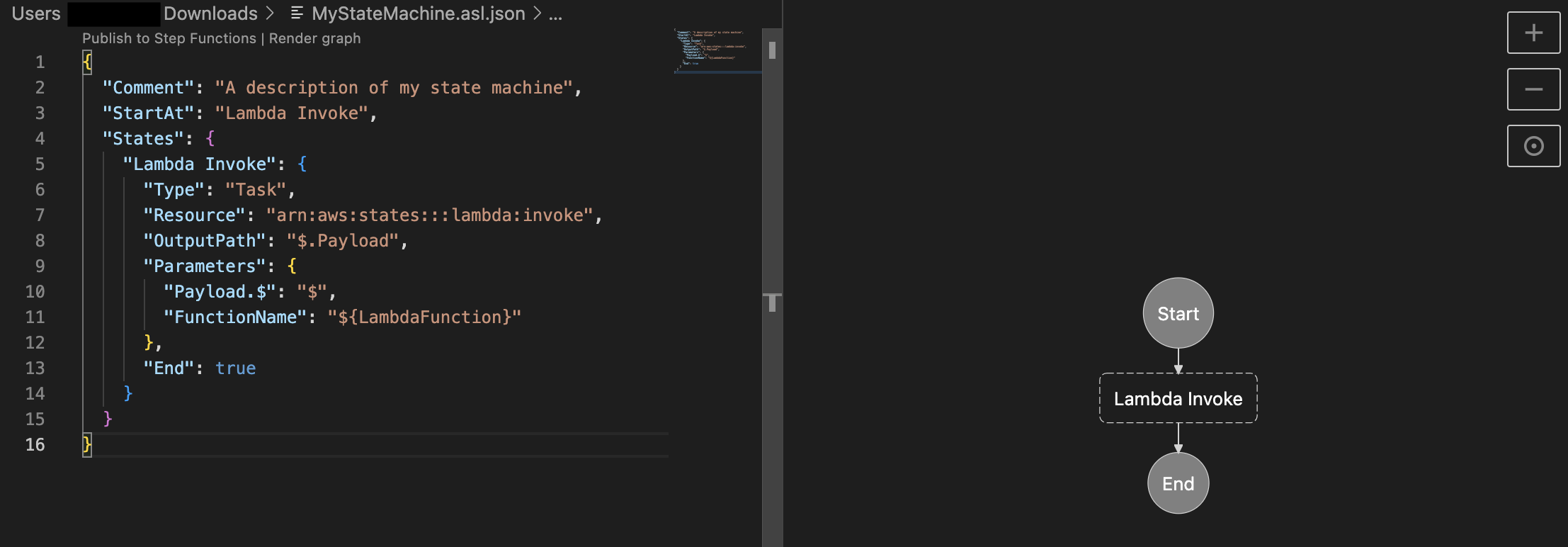
Figure 2 – Step Functions state machine displayed visually in VS Code
Parameter Substitution
In the Terraform template, when you define the Step Functions state machine, you can either include the definition in the template or in an external file. Leaving the definition in the template can cause the template to be less readable and difficult to manage. As a best practice, it is recommended to keep the definition of the state machine in a separate file. This raises the question of how to pass parameters to the state machine. In order to do this, you can use the templatefile function of Terraform. The templatefile function reads a file and renders its content with the supplied set of variables. As shown in the code snippet below, we will use the templatefile function to render the state machine definition file with the Lambda function ARN and any other parameters to pass to the state machine.
resource "aws_sfn_state_machine" "sfn_state_machine" {
name = "MyStateMachine-${random_string.random.id}"
role_arn = aws_iam_role.StateMachineRole.arn
definition = templatefile("${path.module}/statemachine/statemachine.asl.json", {
ProcessingLambda = aws_lambda_function.test_lambda.arn
}
)
logging_configuration {
log_destination = "${aws_cloudwatch_log_group.MySFNLogGroup.arn}:*"
include_execution_data = true
level = "ALL"
}
}Inside the state machine definition, you have to specify a string template using the interpolation sequences delimited with ${ … }. Similar to the code snippet below, you will define the state machine with the variable name that will be passed by the templatefile function.
"Lambda Invoke": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "${ProcessingLambda}"
},
"End": true
}After the templatefile function runs, it will replace the variable ${ProcessingLambda} with the actual Lambda function ARN generated when the template is deployed.
Remote Terraform State Management
Every time you run Terraform, it stores information about the managed infrastructure and configuration in a state file. By default, Terraform creates the state file called terraform.tfstate in the local directory. As mentioned earlier, you will want to include any .tfstate files in your .gitignore file. This will ensure you do not commit it to source control, which could potentially expose secrets and would most likely lead to errors in state. If you accidentally delete this local file, Terraform cannot track the infrastructure that was previously created. In that case, if you run terraform apply on an updated configuration, Terraform will create it from scratch, which will lead to conflicts. It is recommended that you store the Terraform state remotely in secure storage to enable versioning, encryption, and sharing. Terraform supports storing state in S3 buckets by using the backend configuration block. In order to configure Terraform to write the state file to an S3 bucket, you need to specify the bucket name, the region, and the key name.
It is also recommended that you enable versioning in the S3 bucket and MFA delete to protect the state file from accidental deletion. In addition, you need to make sure that Terraform has the right IAM permissions on the target S3 bucket. In case you have multiple developers working with the same infrastructure simultaneously, Terraform can also use state locking to prevent concurrent runs against the same state. You can use a DynamoDB table to control locking. The DynamoDB table you use must have a partition key named LockID with type String, and Terraform must have the right IAM permissions on the table.
terraform {
backend "s3" {
bucket = "mybucket"
key = "path/to/state/file"
region = "us-east-1"
attach_deny_insecure_transport_policy = true # only allow HTTPS connections
encrypt = true
dynamodb_table = "Table-Name"
}
}With this remote state configuration, you will maintain the state securely stored in S3. With every change you apply to your infrastructure, Terraform will automatically pull the latest state from the S3 bucket, lock it using the DynamoDB table, apply the changes, push the latest state again to the S3 bucket and then release the lock.
Cleanup
If you were following along and deployed resources such as the Lambda function, the Step Functions state machine, the S3 bucket for backend state storage, or any of the other associated resources by running terraform apply, to avoid incurring charges on your AWS account, please run terraform destroy to tear these resources down and clean up your environment.
Conclusion
In conclusion, this blog provides a comprehensive guide to leveraging Terraform for deploying AWS Step Functions state machines. We discussed the importance of a well-structured project, initial code setup, integration between Workflow Studio and Terraform, parameter substitution, and remote state management. By following these best practices, developers can create and manage their state machines more effectively while maintaining clean, modular, and reusable code. Embracing infrastructure-as-code and using the right tools, such as Workflow Studio, VS Code, and Terraform, will enable you to build scalable and maintainable distributed applications, automate processes, orchestrate microservices, and create data and ML pipelines with AWS Step Functions.
If you would like to learn more about using Step Functions with Terraform, please check out the following patterns and workflows on Serverless Land and view the Step Functions Developer Guide.