AWS HPC Blog
Cost-effective and scalable Oxford Nanopore Technologies primary analysis with Nextflow and Amazon EC2 G Instances
This post was contributed by Stefan Dittforth and Michael Mueller
Introduction
Oxford Nanopore Technologies (ONT) sequencing enhances genome analysis in research and healthcare with its ability to produce long-read sequencing data in real-time. Long reads improve our ability to detect structural variation, resolve repetitive regions, perform haplotype phasing and analyze full-length transcripts, providing a more complete picture of genetic variation and gene expression. Basecalling or primary analysis of ONT data, the process of converting raw electrical signals into DNA sequences, is a machine learning inference task that is computationally intense and requires GPU-accelerated compute.
This blog post demonstrates how horizontal scaling of Amazon EC2 GPU compute using Nextflow on AWS Batch can reduce ONT basecalling costs by up to 64% while maintaining equivalent throughput compared to traditional vertical scaling approaches. Building on our previously published benchmarking study, we show how distributing basecalling workloads across multiple smaller GPU instances enables both superior price-performance and flexible capacity adjustment to meet varying turnaround time requirements.
For this analysis, we used the publicly available nanopore sequencing data set for the genome in a bottle (GIAB) sample GM12878 (HG001). ONT’s file format for storing raw nanopore sequencing data is POD5. POD5 files of flow cell PAW79146 were downloaded from the Registry of Open Data on AWS. We performed basecalling using Dorado version 1.3.0 with the model dna_r10.4.1_e8.2_400bps_hac@v5.2.0. All cost calculations are based on current Amazon EC2 pricing in the US East (Northern Virginia) Region.
The advantages of ONT basecalling in the cloud
Managing and analyzing large-scale sequencing data presents significant challenges: datasets can reach terabytes in size, requiring substantial storage infrastructure, while the need to retain historic raw data for reprocessing as algorithms improve adds further complexity. Cloud-based solutions for ONT basecalling directly address these common problems while offering several additional advantages that enhance the efficiency, robustness and scalability of the process:
- secure, durable and highly available storage for raw and basecalled sequencing data – eliminating concerns about local storage capacity limits and data backup
- flexibility in reprocessing historic raw data as basecalling algorithms and models evolve and improve – without maintaining expensive on-premises archives
- scalable and elastic compute resources dynamically allocated to meet varying demands, optimizing cost and processing times – avoiding the need to provision for peak capacity
- access to the latest generation of GPUs as available instance types are continuously updated and expanded
Choosing the right instance type for the task
Our previous benchmarking study compared the performance and cost of ONT basecalling across 20 different Amazon EC2 GPU instance types. We demonstrated that both Amazon EC2 P- and G-family instances are well-suited for ONT basecalling, with smaller G5 instances (g5.xlarge) delivering the best price-performance.
Amazon EC2 instances of the P-family offer the highest GPU performance and are in high demand for deep learning and HPC workloads that require large GPU memory and high networking bandwidth for inter-process communication. Amazon EC2 G-family instances are optimized for machine learning inference and provide an optimal balance of performance and cost-effectiveness with wide availability across AWS Regions.
ONT basecalling is an inference task that can be easily parallelized through batch processing across many compute instances, an approach also referred to as horizontal scaling. The wide availability and price-performance of G instances together with the ability to horizontally scale GPU compute makes this instance family an ideal choice for ONT basecalling tasks.
Horizontal scaling of GPU compute
Vertical scaling involves increasing the capacity of individual instances by adding more or more powerful CPU, memory, or storage resources to make them more performant. Horizontal scaling, on the other hand, distributes workload across multiple instances, adding more copies of the same type of resource. Figure 1 illustrates how ONT basecalling is parallelized using vertical scaling of GPU compute resources on a single P instance versus horizontal scaling across multiple G instances.
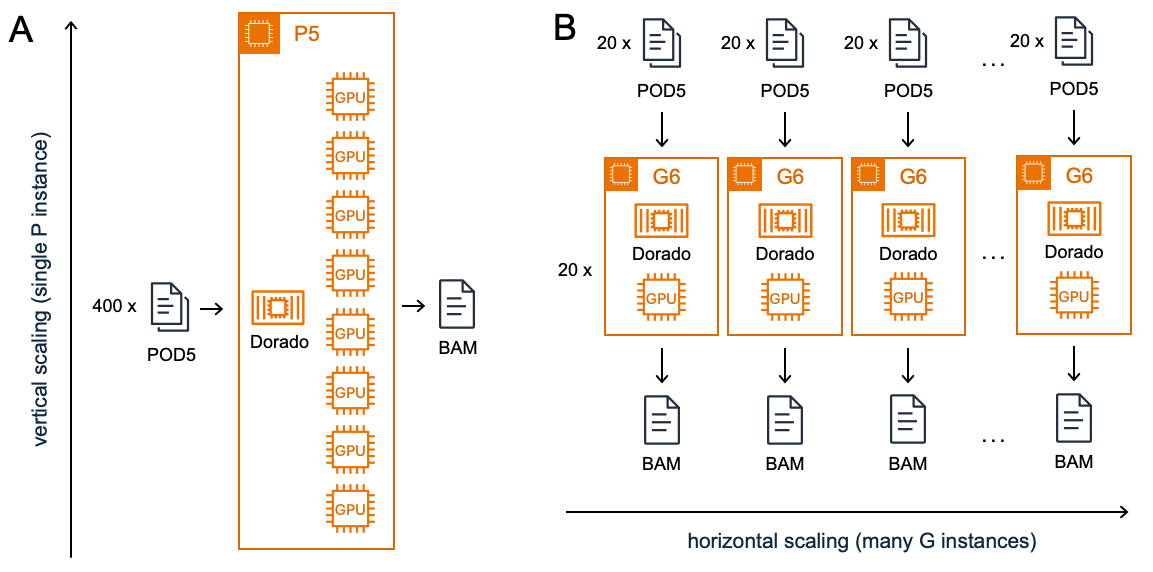
Figure 1: Vertical vs. horizontal scaling of GPU compute for ONT basecalling.
A) Vertical scaling involves increasing the power of a single machine by adding more or more powerful CPU, GPU, RAM, or storage to handle heavier workloads.
B) Horizontal scaling distributes the computational load across multiple machines. This hypothetical example compares processing 400 POD5 files on a single p5.48xlarge instance versus distributing them in batches of 20 files across 20 g6e.xlarge instances.
One of the key advantages of cloud computing is the ability to easily scale compute horizontally. Amazon EC2 instances use a per-second billing model (with a one-minute minimum), which means that for a given instance type, running one instance for 60 minutes costs the same as running 60 instances for 1 minute – the total compute time and cost remain equivalent. This billing model combined with the on-demand provisioning of compute resources, enables dynamic resource allocation and scaling without incurring additional costs.
Horizontal Scaling made easy with AWS Batch and Nextflow
AWS Batch is a fully managed batch computing service that dynamically provisions and allocates optimal compute resources based on workload requirements. Nextflow, an open-source workflow management solution developed by AWS Partner Seqera, integrates seamlessly with AWS Batch. Together, AWS Batch and Nextflow enable efficient execution of basecalling tasks by automating task parallelization and resource management.
We can leverage Nextflow’s channel buffering to control horizontal scaling of ONT basecalling tasks on AWS GPU compute and easily adapt it to throughput requirements as shown in this example workflow snippet:
workflow ONTBASECALLING {
ch_input_pod5 = channel.fromPath("$params.input_dir/*.pod5")
DORADO_BASECALLING(
ch_input_pod5.buffer(
size: params.batch_size,
remainder: true)
)
}
With the buffer size parameter, we specify how many POD5 files are processed per batch and GPU instance. Smaller batch sizes will result in a higher parallelization across more instances and shorter overall runtimes of the basecalling workflow. As discussed above the cost for basecalling compute stays the same because it is independent of the allocation of compute time to compute instances.
Optimizing task parallelization and workload distribution
Smaller input files of similar size are preferable. Many small input files give us more granular control over horizontal scaling by allowing us to scale out compute tasks across more, smaller instance types. Fewer, large input files on the other hand can limit the number of instances we can scale out to. The GIAB test data set we used here has 73 POD5 files which would be the maximum number of instances we can parallelize compute tasks across.
Furthermore, a uniform distribution of file sizes makes the creation of similar sized batches and therefore workload distribution easier, avoiding that the largest input files become the bottleneck. In case of the GIAB test data set file sizes range from 731.7MB to 31.6GB which makes even distribution of processing across instances using channel buffering challenging.
Finally, processing smaller chunks of data per processing job makes our workflow more robust to interruption. By breaking down the workload into smaller units, we reduce the compute that is required when a task needs to be re-run. This enhanced resilience to interruption is particularly valuable when leveraging Amazon EC2 Spot Instances which offer spare compute capacity at up to 90% discount compared to on-demand prices but can be reclaimed by AWS with up to two minutes notice. We will discuss cost-optimization with Spot Instances in more detail below.
Optimizing data staging
When working with the community edition of Nextflow on AWS, it is important to consider data access patterns. By default, Nextflow stages input data from Amazon S3 to the instance storage or the Amazon EBS volume attached to the EC2 instance running the task.
To optimize Amazon S3 download performance and minimize compute time for staging, we want to maximize parallelization of Amazon S3 access. Issuing multiple concurrent requests to Amazon S3 and spreading these over separate connections maximizes the accessible bandwidth from Amazon S3 and optimizes the data staging and un-staging processes (see also Performance guidelines for Amazon S3).
Utilizing Nextflow’s built-in support for Amazon S3 facilitates management of data transfers between Amazon S3 and Amazon EC2 instances including retries and transfer parallelization. CPU and memory utilization increases with the number of parallel transfers. Therefore, it is important to balance parallelization with available system resources especially when transferring large volumes of data to avoid jobs running out of memory. Transfer parallelization can be adjusted with the aws.batch.maxParralelTransfers Nextflow configuration option. Increasing the number of transfer-retries with aws.batch.maxTransferAttempts helps to avoid jobs failing because of Amazon S3 API request limits.
Amazon EC2 GPU instances feature instance store volumes provided by high-performance NVMe storage that is physically attached to the host computer. Instance storage is included in the instance price and ideal for storage of temporary data and applications requiring maximum I/O performance. To configure instance storage for use with your Nextflow process format and mount to storage volume in the User Data of your Amazon EC2 launch template. The following is a User Data example for an instance with a single NVMe volume like for example a g6e.xlarge:
#!/bin/bash
mkfs -t xfs /dev/nvme1n1
mount /dev/nvme1n1 /tmp
chmod 777 /tmp
Putting it all together
Figure 2 summarizes how to leverage Nextflow, AWS Batch and Amazon EC2 G Instances to horizontally scale ONT basecalling:
- Build a Docker container image with the desired Dorado basecaller version and basecalling models and store it in a repository on Amazon ECR, a fully managed container registry that makes is easy to store, share, and deploy container images
- Set up an AWS Batch compute environment configured with the appropriate G instance type for basecalling
- Associate an Amazon EC2 launch template with your compute environment to configure instance storage as temporary storage for input and output data
- Implement a Nextflow workflow that leverages Nextflow channel buffering to split up your input data into batches and parallelize basecalling tasks
- Run your Nextflow pipeline with the AWS Batch executor which will take care of running your basecalling tasks on AWS Batch using the containerized Dorado basecaller, staging input data from Amazon S3 and uploading outputs to Amazon S3
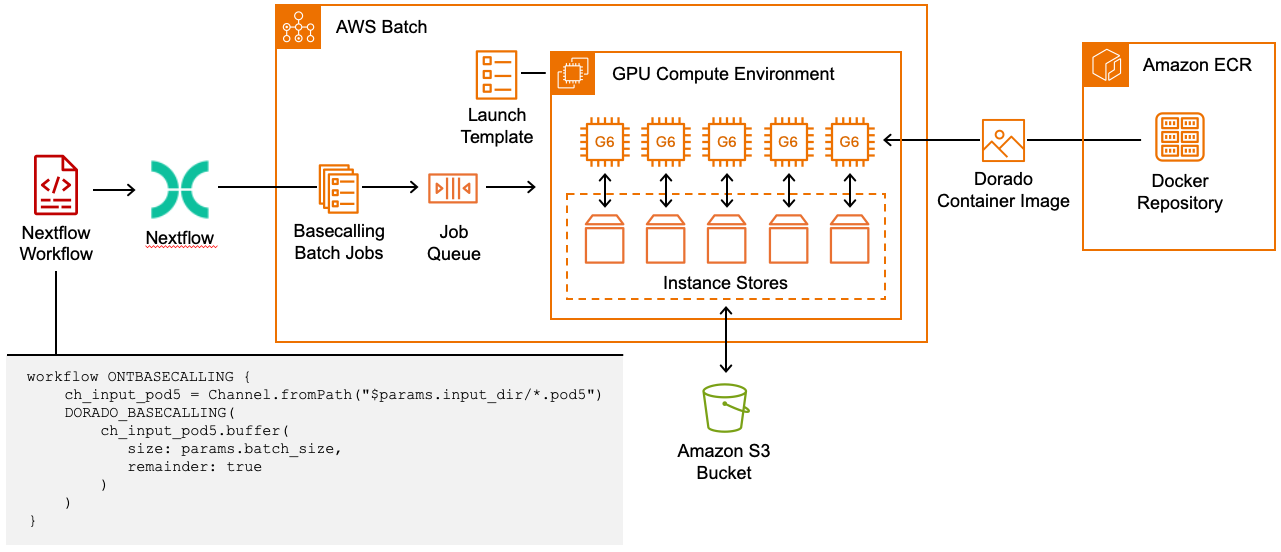
Figure 2: ONT basecalling with Nextflow on AWS Batch. Nextflow automates POD5 input file batching and parallelization of ONT basecalling tasks. AWS Batch distributes basecalling tasks across multiple G6 instances. By utilizing Amazon EC2 Instance Storage, we achieve both reduced storage costs and enhanced I/O performance.
Horizontal scaling delivers shorter runtime and lower cost
To demonstrate the benefits of horizontal scaling, we compared basecalling runtimes between vertically scaled GPU compute on a P5 instance and horizontally scaled GPU compute on G6e instances. Amazon EC2 G6e instances are powered by NVIDIA L40S Tensor Core GPUs and deliver up to 2.5x better performance compared to G5 instances.
In our benchmarking g6e.xlarge instances achieved a throughput of ~105.4M samples/s. To match the p5.48xlarge basecalling throughput of ~1.14B samples/s, we ran 11 g6e.xlarge instances in parallel (11 × 105.4M ≈ 1.16B samples/s). We also tested with 22 g6e.xlarge instances to demonstrate how Amazon EC2’s billing enables further scaling and reduction of runtime without increasing costs.
To optimize workload distribution across these instances, the original 73 POD5 files were resized into 743 uniformly sized 1.5GB files, enabling even distribution of data. The data resizing performed for this benchmark was done to demonstrate the advantages of smaller, uniformly sized input files. In production environments, configure the ONT software to generate smaller POD5 files directly during sequencing. This eliminates the need for retrospective file resizing and avoids the associated processing time and costs.
As shown in Figure 3, horizontal scaling of basecalling across 11 G6e instances achieves a comparable overall runtime (determined by the longest-running parallel task) to the single P5 instance (28 minutes and 47 seconds vs. 29 minutes and 16 seconds).
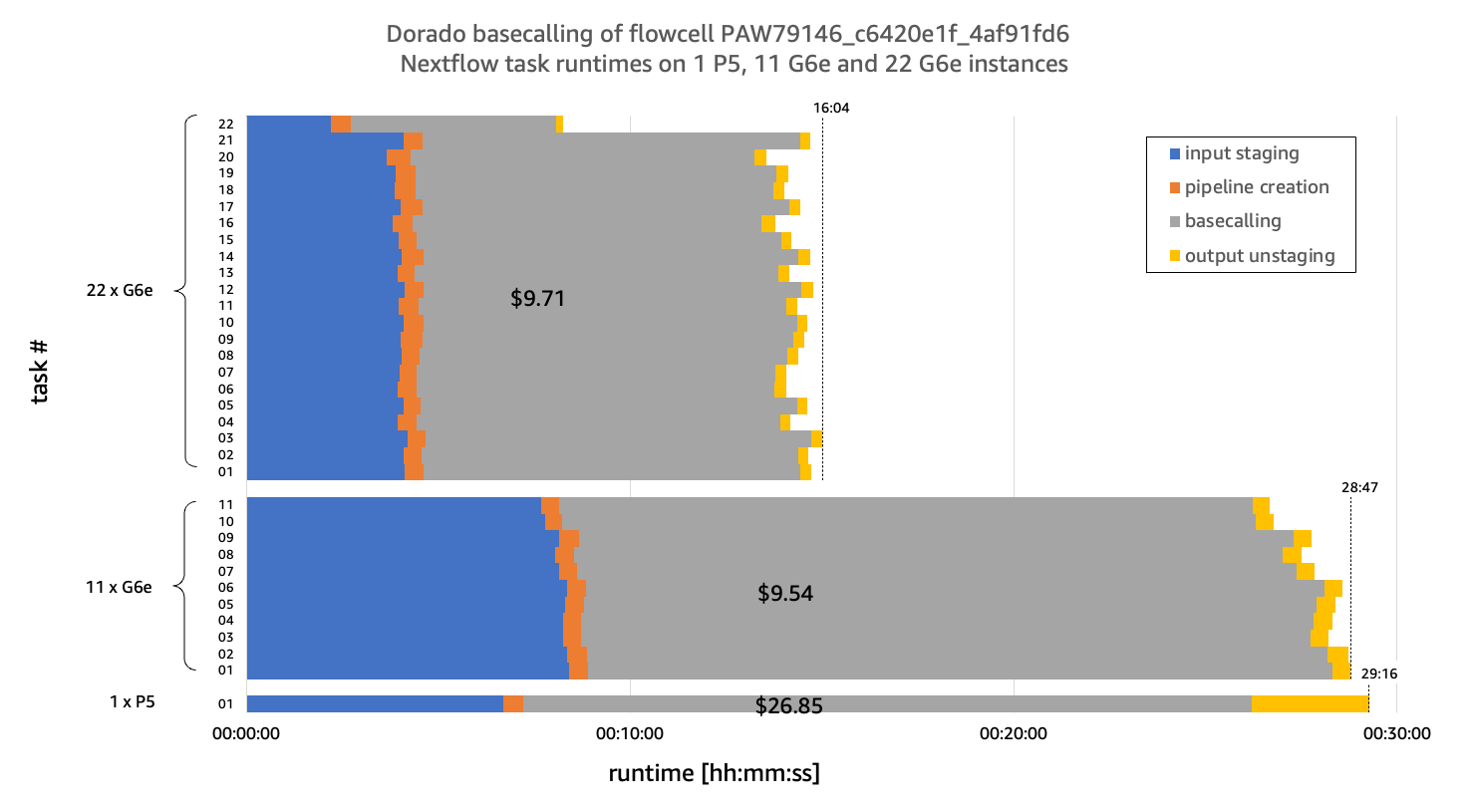
Figure 3: Performance and cost comparison of ONT basecalling with Dorado on a single P instance vs many G instances. Horizontal scaling across 11 g6e.xlarge instances achieves comparable runtime (determined by the longest-running parallel task) to a single p5.48xlarge instance (28 minutes and 47 seconds vs. 29 minutes and 16 seconds) while delivering 2.8x better price-performance ($9.54 vs. $26.85). Scaling to 22 g6e.xlarge instances further reduces runtime (16 minutes and 4 seconds) without impacting cost. Dorado version 1.3.0 and basecalling model dna_r10.4.1_e8.2_400bps_hac@v5.2.0 were used for benchmarking.
From a cost perspective, G6e instances deliver significantly better price-performance. The combined runtime of 11 g6e.xlarge instances of 5 hours, 7 minutes and 34 seconds results in a total workflow cost of $9.54, while the p5.48xlarge incurs $26.85 for 29 minutes and 16 seconds – nearly three times the cost. As detailed in Table 1, this cost advantage stems from two factors:
- basecalling computation: $6.40 (G6e) vs. $17.41 (P5) – 63% savings
- data staging/unstaging: $2.87 (G6e) vs. $8.96 (P5) – 68% savings.
Table 1: Composition of total workflow compute costs
|
Cost 1 x p5.48xlarge |
Cost 11 x g6e.xlarge |
|
| input staging | $ 6.15 | $ 2.78 |
| pipeline creation | $ 0.47 | $ 0.17 |
| basecalling | $17.41 | $ 6.42 |
| output unstaging | $ 2.81 | $ 0.16 |
| total | $26.85 | $ 9.54 |
As also shown in Figure 3, Amazon EC2’s per-second billing model enables cost-effective scaling beyond simple throughput parity. By doubling the instance count to 22 g6e.xlarge instances, we can reduce runtime by 44% (from 28 minutes 47 seconds to 16 minutes 4 seconds) without significantly impacting overall costs.
Overall, horizontal scaling with g6e.xlarge instances achieves approximately 64% cost savings at equivalent throughput compared to a single p5.48xlarge instance. Additionally, this approach provides flexible throughput scaling allowing you to dynamically adjust compute resources based on required turnaround times.
Optimizing compute costs further by leveraging EC2 spot Instances
Amazon EC2 Spot Instances let you take advantage of unused EC2 capacity in the AWS cloud and are available at up to a 90% discount compared to on-demand prices, offering substantial cost reductions for suitable workloads. At the time of writing, the average spot price for g6e.xlarge was $0.9573 per hour, reducing the total cost for the 11-instance basecalling run from $9.54 to $4.91 — a 49% savings over on-demand pricing.
As spot instances can be terminated short notice if demand increases, workloads need to be fault-tolerant by implementing robust retry and resume mechanisms. We can leverage Nextflow’s retry and resume functionality to make our workflow more resilient to EC2 spot interruptions. By configuring the aws.batch.maxSpotAttempts parameter in your Nextflow configuration, you can instruct Nextflow to automatically resubmit tasks that fail due to spot interruptions.
Combining Nextflow’s retry functionality with smaller POD5 file sizes and the ability to create smaller batch sizes makes the workflow even more resilient to spot interruptions. By processing smaller chunks of data per job the unit of work that needs to be recomputed upon interruption is significantly reduced.
Finally, Nextflow’s built-in resume functionality works in tandem with retries, enabling the workflow to efficiently restart from the last successfully completed task, further enhancing resilience in case of a workflow fails if the maximum number of retries for a task has been exceeded.
Conclusion
Cloud-based ONT basecalling on AWS with Nextflow and AWS Batch offers a powerful solution for scaling primary analysis of ONT sequencing data. By following these best practices, you can optimize your basecalling pipeline:
- Choose the right instance type: for batch inference tasks like ONT basecalling, G instances provide the ideal balance of performance and cost-effectiveness.
- Leverage horizontal scaling: utilize AWS Batch and Nextflow to distribute basecalling tasks across multiple GPU instances, maximizing throughput and efficiency.
- Optimize instance selection: opt for smaller instance types to gain finer control over capacity and improve parallelization of data staging processes.
- Optimize compute costs with spot instances: leverage Nextflow retry and resume functionality to make your workflow resilient to spot interruption
- Keep file sizes small and uniform: using smaller files of similar size provides greater flexibility for parallelization and simplifies workload distribution, while also enhancing resilience against spot interruption
By implementing these strategies, healthcare and life sciences organizations can create scalable, cost-effective ONT basecalling pipelines on AWS, accelerating long-read sequencing analysis and reducing the time and cost to gain insights from genomic data.
To start exploring horizontal scaling of ONT basecalling on AWS yourself, visit the AWS Samples GitHub repository where you will find the Nextflow workflow and infrastructure code to deploy the AWS Batch environment to run the workflow.