AWS HPC Blog
Scaling life sciences research by deploying AWS ParallelCluster and AWS DataSync
In life sciences research, managing large-scale computational resources and data efficiently is important for success. However, traditional on-premises environments often struggle to meet these requirements effectively. This post demonstrates how JSR Corporation transformed their research infrastructure using AWS ParallelCluster and AWS DataSync, achieving a 33% reduction in CPU usage and 85% in storage requirements. JSR’s research teams now spend more time on genomics and medical research. In this blog post, Yoshimasa Aoto from the JSR-Keio University Medical and Chemical Innovation Center (JKiC) shares their challenges and the benefits of adopting AWS.
JSR’s life sciences business initiatives
JSR’s academic-industrial research facility aims to expand drug discovery and development support services through medical and biological research using novel modalities. Their bioinformatics and medical informatics research require significant computational resources, which they previously managed through an on-premises data center.
Challenges with on-premises high performance computing
As JSR’s on-premises servers aged and approached their refresh cycle, several challenges emerged that prompted the company to seriously consider AWS adoption:
Bottlenecks from Sporadic Large-Scale Computations: Daily analytical workloads, such as genomic sequence alignment, protein structure prediction, and medical image analysis, typically consumed only 25-50% of the existing server’s CPU resources. However, each research project generated additional sporadic large-scale computations every few weeks to months. These experiments produced 10GB to 15TB of data per batch, creating consistent bottlenecks in CPU, memory, or storage resources.
Growing Data Management Complexity: Life sciences research facilities commonly face challenges managing large experimental datasets. JSR’s laboratory deals with many precious data samples that are difficult to recollect, and since some experiments cost up to $50,000, the data needs to be stored safely for long periods of time. Previously, researchers manually uploaded data from experimental equipment to servers and created separate physical storage backups, a process that became increasingly cumbersome as research data volume grew.
GPU Procurement Challenges: JSR also struggled with GPU resources for machine learning workloads. Traditional hardware procurement cycles required annual budgeting and planning, making it difficult to keep pace with rapid AI technology advances. While they used Amazon Elastic Compute Cloud (Amazon EC2) on-demand instances as a stopgap solution, managing the startup/shutdown cycles and associated costs created psychological barriers for users.
Implementing a hybrid cloud HPC architecture
To address these challenges, JSR implemented AWS services, creating a hybrid cloud system that balanced flexibility with control.
Flexible compute with AWS ParallelCluster
AWS ParallelCluster is an open-source high-performance computing (HPC) tool that deploys and manages HPC clusters on AWS. Customers often use it for flexible resource management of sporadic computations and high-volume storage requirements. By customizing Slurm partitions (queues) in AWS ParallelCluster, JSR achieved an architecture where appropriate instance types and sizes automatically start based on computational demands and stop after job completion. They implemented both CPU and GPU-oriented partitions, creating a flexible and cost-optimized HPC configuration that easily adapts to changing requirements. JSR favors the G6e instance family for its excellent price-performance balance and is actively adopting it for computational workloads. They are also currently evaluating running their Nextflow genomics analysis pipeline on AWS Batch.
Automated data management with AWS DataSync
Additionally, JSR implemented automated data transfer and backup using AWS DataSync. AWS DataSync is an online data movement service that simplifies and accelerates data migrations to and from AWS. It automatically transfers experimental data to both analysis environments and backup storage. The solution leverages AWS DataSync’s built-in scheduling capabilities for daily transfers during off-peak hours, automatic retry mechanism for failed transfers, and task-level monitoring with Amazon CloudWatch for ensuring data transfer reliability.
Furthermore, JSR optimized costs by leveraging different Amazon Simple Storage Service (Amazon S3) storage classes – using Amazon S3 Glacier Deep Archive for backup data and Amazon S3 Intelligent-Tiering for analysis data.
Complete integration with a hybrid HPC architecture
Figure 1 illustrates JSR’s hybrid architecture and shows how experimental data flows from on-premises resources through automated DataSync transfers to AWS storage, while compute workloads dynamically scale using AWS ParallelCluster.
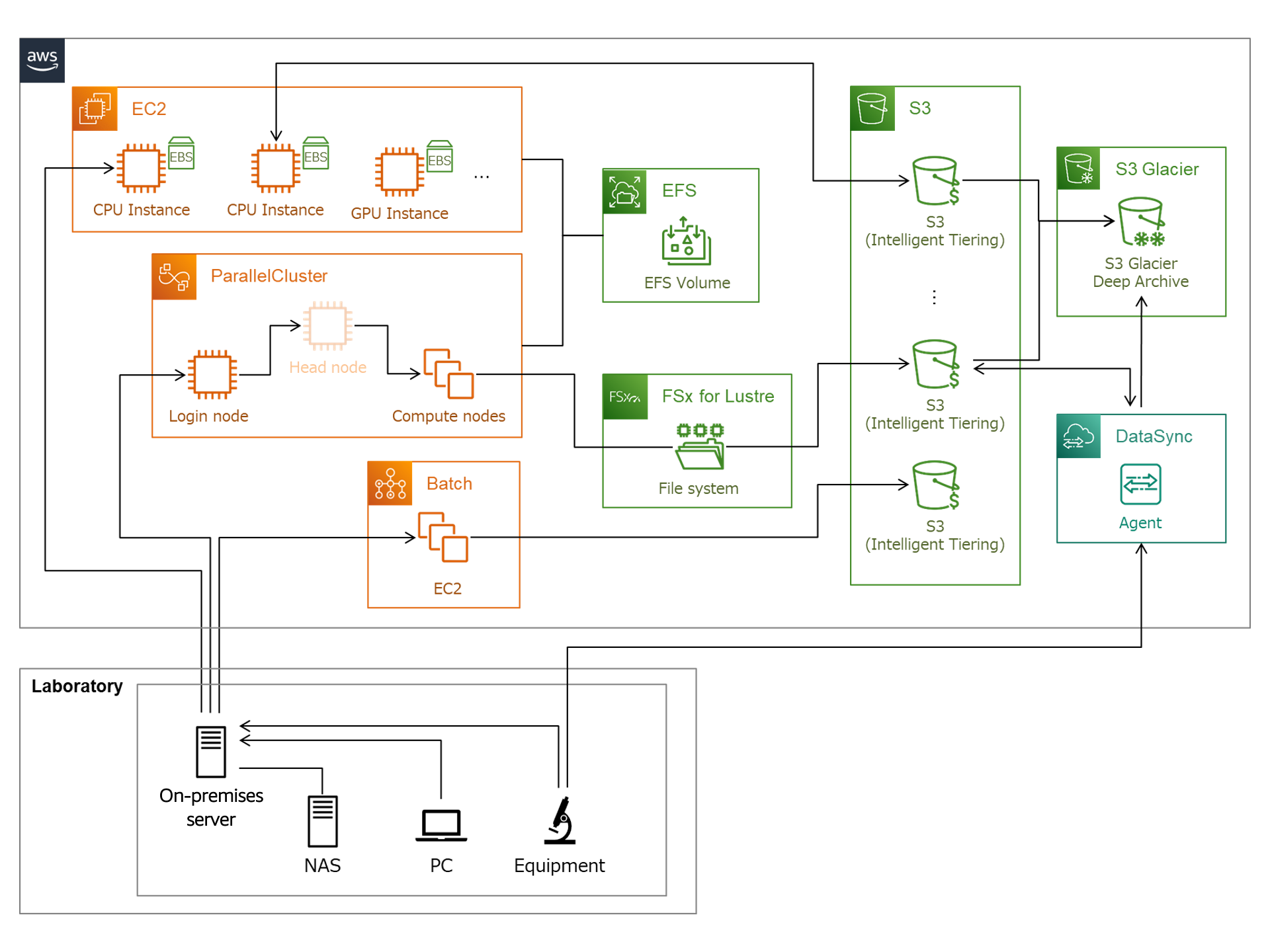
Figure 1: JSR’s Large-Scale Computing Environment for Life Sciences Research
The architecture supports the following workflow:
- Researchers generate experimental data on-premises
- DataSync automatically transfers data to S3 during off-peak hours
- AWS ParallelCluster provisions compute resources based on job requirements
- Analysis results are stored in S3 Intelligent-Tiering
- Backup data moves to Glacier Deep Archive for long-term retention
Benefits
The implementation of AWS managed services delivered measurable benefits to JSR’s life sciences research:
Downsized On-Premises Infrastructure: By offloading sporadic large-scale computations to AWS, JSR eliminated the need for excess on-premises resources, reducing their server CPU count by 33% and storage capacity by 85%.
Automated CPU and GPU Resource Management: GPU resource procurement, which previously took about one year, now takes just minutes, eliminating research bottlenecks. Managed services also simplified cost management.
Reduced Infrastructure Deployment Risk: The solution eliminated approximately six months of administrative overhead related to cost estimation, budget approval, procurement, installation, and configuration. It also removed the risk of stranded assets due to changing requirements.
Automated Data Management: Previously, data collection from measurement devices and transfer to analysis servers and backup storage could delay research by up to a week. Automation has eliminated these delays, significantly improving research efficiency.
Conclusion
JSR’s journey demonstrates how life sciences organizations can transform their research capabilities by modernizing their HPC infrastructure with AWS. Their success shows that the right cloud strategy can not only reduce operational overhead but also accelerate scientific discovery. Before AWS adoption, JSR faced these key challenges with their on-premises data center HPC environment:
- Bottlenecks from sporadic large-scale computations
- Growing data management complexity
- GPU procurement difficulties
The implementation of AWS ParallelCluster and AWS DataSync delivered substantial improvements: on-premises infrastructure needs dropped by 33% for CPU and 85% for storage; GPU procurement that once took a year now happens in minutes; six months of planning overhead disappeared; and researchers gained an additional week of productive time per experiment that was previously lost to data management tasks. To learn more about implementing similar solutions, see the AWS ParallelCluster documentation and AWS DataSync Getting Started Guide.
About JSR Corporation

JSR Corporation operates under the corporate philosophy of “Materials Innovation – Creating Value through Materials, Contributing to Society (People, Society, and the Environment).” The company strives to provide irreplaceable materials to society while earning public trust through its contributions. In the life sciences sector, JSR delivers CDMO/CRO services for drug discovery support.