AWS for Industries
Process Mining (Deloitte Process Bionics) on AWS – Achieving Operational Excellence
Co-authored by Dr Yiming Sun Ex-Deloitte employee in the Financial Advisory Analytics (Center for Process Bionic).
—
Process Mining Overview
Process mining provides valuable, detailed insights into a company’s business processes and identifies ways of improving them. This blog post provides an overview of utilizing process mining as an analytical discipline for discovering, mapping, and visualizing an organization’s as-is process, based on the “digital footprints” (i.e., data indicating which activity is started when and by whom) from organization’s enterprise systems.
Process mining is a collection of techniques from the fields of business process management, data analysis, and machine learning to support the analysis and optimization of operational processes based on business event logs. Process mining combines the core functions of data analytics (namely ingestion, processing, and cataloging) with machine learning to help organizations discover the digital footprints of the current process and the variants that usually introduce inefficiencies and costs.
According to the Everest Group, process mining grew around 140–160% from 2018 to 2019 to reach $230–$250 million. Manufacturing, banking, financial services and insurance, and the telecom industries are among the leading adopters of process mining solutions.
Deloitte Center for Process Bionics (CPB) provides a completely new and innovative solution built on AWS that uses data to understand processes and how systems interact with these processes. The solution utilizes the state-of-the-art process mining technology to capture end-to-end business processes. Supported by operational and transactional data, process mining provides valuable, detailed insights into a company’s business processes and points out ways of improving them. The Process Bionics concept extends process mining to a holistic digital management approach. This visionary model follows the paradigm of natural processes, such as neural networking, AI, adaptation, automation, and evolution, aiming for a dynamic, continuous operation optimization measures across the whole company.
Deloitte Process Bionics Platform and the Deloitte process mining framework on AWS provides Deloitte’s customers with a truly global solution where the infrastructure is able to scale on demand.
Process Mining and Deloitte Center for Process Bionics
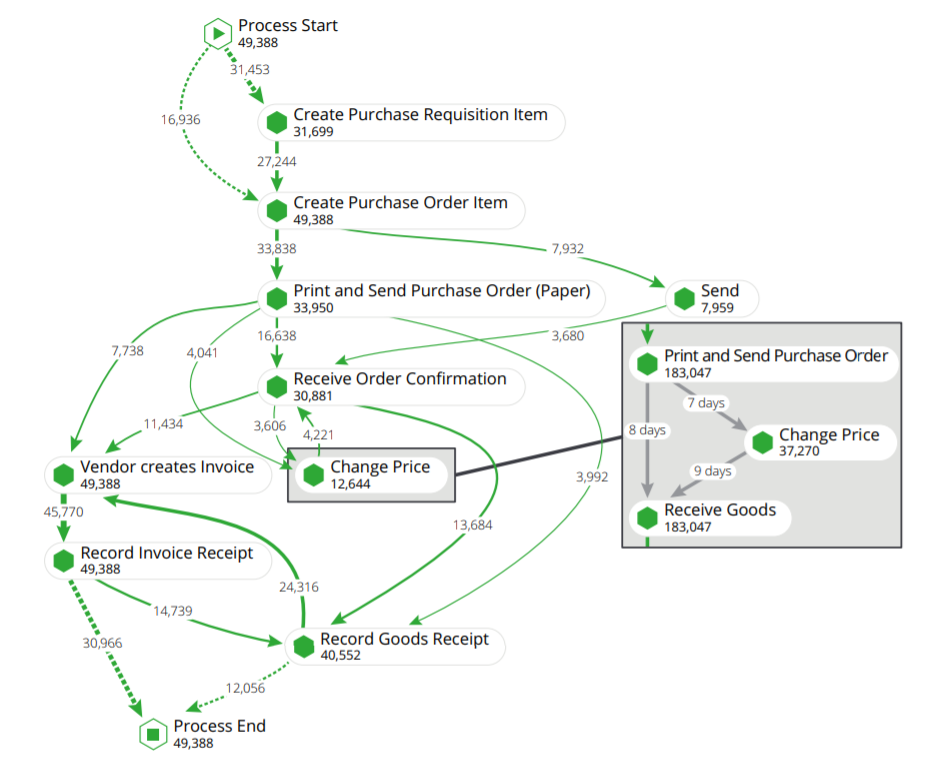 Figure 1. Illustration of process mining
Figure 1. Illustration of process mining
Process mining makes transparency, real-time control, and adherence checks against defined targets possible. Specific decision-making processes that take place in the company become visible and coherent. The underlying causes of the process inefficiencies also become visible. Process inefficiencies discovered from process mining can be addressed through one-off measures, organizational changes, or intelligent digital tools such as robotic process automation or automated system integration.
One example of leveraging process mining to help clients achieve cost savings in one engagement at a top global oil and gas client. It was originally looking to initiate a digital transformation to improve its customer payment experience globally. It was widely viewed by their customers that the client was not easy to do business with. The company’s biggest challenge was around invoicing, billing, and payments processes – for example late or incorrect invoices severely impacted working capital. Deloitte was brought in to help with the digital transformation of the customer’s payment experience across a $150 billion business line – however, the payment experience issue was only the symptom. The root cause was due to the breakdown of numerous underlying processes. And that’s where the CPB team came in – helping address the core process problems that exhibited themselves in the various client experience issues. The CPB team deployed process mining to map the processes, detect discrepancies, and identify their impacts. Through this methodology, they were able to identify several different process inefficiencies. For instance, the client invoiced customers, on average, two days after their customers received a product – that’s basically free money being lent out – and hundreds of millions of dollars of working capital lost. Another side effect was that the invoices did not match with the pick-up date and caused significant challenges to their customer’s payable and reconciliation processes. And when customers finally received the invoice, they would oftentimes pay them late (9.5% of invoices were paid on average 14 days late). By focusing on that specific process breakdown, CPB was able to reduce the delays by 0.81 days, resulting in a $20 million working capital capture for this customer.
Another example is a process mining engagement with a financial services customer in Europe. To help the client improve the company’s loan application process, the approach was to start with one of the retail lending products. The first step was to gain an overall process understanding based on the client’s standard operating procedure (SOP). A comprehensive process analysis was conducted with the focus on four main areas: rework, authorization, cycle time, and compliance. Various process bottlenecks were discovered and corresponding root causes were identified. This resulted in the average time for loan authorization being reduced by 12 days for the original worst-performing branches. Other value-add impact from this project was that the client took measures to address the issues related to rework by introducing a Robotic Process Automation (RPA) solution to fully automate their data entry and customer verification process and ensure necessary process enhancement to reduce time for application submission, post sanction document quality checks, and other field verification activities.
Deloitte Process Mining Framework
In process mining, the event log table is usually the starting point for any purposeful process mining exercise. Sourcing, cleansing, and preparing data for process mining is one of the most challenging and time-consuming parts in a process mining implementation.
Deloitte CPB has developed a unique framework, Deloitte Process Mining Framework, to help clients with all the steps from data scoping, data extraction, and data standardization until the final creation of the event log table and the process mining data model. The methodology of this framework has been coded into scripts (available in environments including but not limited to Microsoft SQL, Oracle SQL, PostgreSQL, SAP HANA DB, HDFS, etc.), and capsuled into different modules (as shown in Figure 2). With the Deloitte Process Mining Framework, clients are able to easily process data from different data sources and create the end-to-end data model in a very flexible and scalable way.
 Figure 2. Modules in the Deloitte Process Mining Framework
Figure 2. Modules in the Deloitte Process Mining Framework
The entire framework works as follows:
- Pre-processing: For all process mining engagements, the step involves support to help clients define the process scope, identify the relevant systems/tables/columns to be extracted, provide advice on data extraction (or extract the data on behalf of clients), store the data properly in a central data repository where the subsequent steps can access, and apply automatic data quality checks to confirm we have the data requested.
- Staging: After the data is properly stored and verified, staging scripts are used to identify the desired process object types (for instance, in an account payable process; vendor invoice and outgoing payment), assign unique document IDs to these process objects, and create artificial objects (i.e., for each process object, creating a central object with all the information needed), for the subsequent steps.
- Mapping: In the mapping module, business logic is applied and connections between different process objects are established. For example, in a typical Order to Cash (O2C) process, the connections between quotations, sales orders, delivery document, invoices, etc. will be established in this module. The corresponding mapping results will be used as the foundation to create the case table (i.e. a table consisting of the unique identifiers of the leading objects of all process cases) in the process mining data model.
- Pruning: A graph traversal algorithm is implemented in the pruning module to traverse through all objects and connections from the mapping result, and create a comprehensive graph representing all the object relationships of the dataset. Each subset of this graph is considered as a separate case, and the ID of the corresponding leading document is also used as the case ID (identifier of the case).
- Event: Based on the case table, one could explore the entire dataset to extract all the activities (events) on each individual process objects of the cases. All the required information, including but not limited to the description of the activities, timestamps when the activities happened, and users who conducted the activities, is consolidated into one central event log table, which will be loaded to the process mining tools.
- Post-processing: After all the essential tables are created from preceding modules, sometimes it is also necessary to create additional auxiliary tables, such as business intelligence tables for individual process objects. This is done in the post-processing module.
Compared with the other existing solutions, Deloitte Process Mining Framework has the following benefits:
- Flexible: Firstly, scripts of the entire framework have been coded into different modules as listed previously. All the modules could be started either together or individually to generate the results required. Secondly, there are a number of configuration tables and files, which allow the users to put the process and infrastructure-specific information as configuration variables in the framework. Nothing is hardcoded in the scripts. Users have a high degree of flexibility to use the framework to deal with various customization settings and it is also easy to migrate or duplicate the solution from one place to another.
- Scalable: This entire framework is designed to handle more than one data source, and it has been proven to be effective via various large-scale client engagements. When working with multiple data sources, each data source is identified by a set of configuration parameters, and a large part of the framework scripts could be shared and reused among the sources. Only system-specific customization needs to be added. This approach really reduces the development and maintenance effort of handling multiple data sources, and makes the whole process mining solution more scalable.
- Efficient: For big companies, especially the ones in the retail or manufacturing sectors, it is common to process millions, if not billions of transactional records and bring all of them into one data model. To deal with such computationally heavy scenarios, there are many performance-boost measures integrated in the framework, for instance, parallel computing, partitioning of the mapping group, etc.
Deloitte Process Bionics Platform on AWS
Using the foundation of the Deloitte Process Mining Framework on AWS, Deloitte has developed the Deloitte Process Bionics Platform, to provide flexible and robust process mining services to clients around the world.
 Figure 3. The Deloitte Process Bionics Platform architecture on AWS
Figure 3. The Deloitte Process Bionics Platform architecture on AWS
AWS services implemented as part of the Deloitte Process Bionics platform include:
- Amazon EC2 for the hosting of different process mining tools
- Amazon S3 for the raw data storage
- AWS Lambda for serverless pipelines
- Amazon SES for notifications sent to the users
- AWS Glue for ETL jobs from Amazon S3 to Amazon RDS
- Amazon RDS for the hosting of the Deloitte Process Mining Framework and creation of the data model
- Amazon Cognito for the authentication and credential management
- AWS CodeBuild for the deployment pipeline
- AWS CodeCommit as a Git repository
- Amazon Application Load Balancer as load balancer for the application
- AWS Fargate for the hosting of frontend containers of the Process Bionics Platform
- Amazon ECR as container registry
- AWS Systems Manager to store secrets
- AWS Key Management Service for encryption and SSH key management
- Amazon Inspector for compliance monitoring of the platform
It is designed according to the AWS Well-Architected Framework and completely defined in Terraform using infrastructure as code (IaC). Once a new request is received, a new environment could be automatically deployed within half a day. After the environment is deployed, a new process mining implementation can be started by following this workflow:
- Upload raw data into Amazon S3 bucket that automatically replicates the data into MSSQL (hosted in Amazon RDS) via a customized glue job. The entire data upload pipeline is written serverless using AWS Glue and AWS Lambda.
- Finish data provisioning and transformation using the pre-deployed Deloitte Process Mining Framework, and create the process mining data model on the backend.
- Upload the data model to the selected process mining tool hosted on EC2. The application can be managed and used through a custom client facing frontend hosted on AWS Fargate.
 Figure 4. Deloitte Process Bionics Platform frontend screenshots
Figure 4. Deloitte Process Bionics Platform frontend screenshots
Summary
Thanks to the Deloitte Process Bionics Platform, which has been developed leveraging AWS, Deloitte are able to quickly deploy the process mining solutions in a scalable and flexible manner, and provide high quality services to their clients all over the world.
With Process Mining, companies are able to get an unbiased, “agnostic” view of uncomfortable truths in the business, and accordingly, they will have a tangible solution at their disposal that provides immediate cost benefits. But that is only the first stage of tomorrow’s process management. This approach is systematically expanded and extended at the Deloitte Center for Process Bionics – each company is understood as a growing, living organism, and the improvement process itself is also designed to be organic.
To learn more about Deloitte Process Bionics on AWS, please visit Deloitte Center for Process Bionics and learn more about Deloitte as an AWS Premier Consulting Partner on the AWS Partner page.