AWS for Industries
Unlocking the value of unstructured data with Amazon Bedrock Data Automation
Organizations across various industries are struggling with the exponential growth of unstructured data—images, text documents, PDFs, audio and video files, and specialized formats such as genomic sequences. Unlike structured data with clear organization, unstructured data typically lacks standardized organization, making it challenging to discover, access, and derive insights from these valuable assets.
At Amazon Web Services (AWS), we’ve observed similar challenges across research institutions and healthcare organizations seeking better ways to catalog, search, and extract insights from their unstructured data repositories.
We will explore how a solution, utilizing Amazon Bedrock Data Automation, which is a feature of Amazon Bedrock can provide:
- A comprehensive solution for unstructured data management
- Automated cataloging
- Improve data quality
- Governance policies enforcement
- Quick access to valuable data products
We will also illuminate how AWS and AWS Partner solutions help address deidentification of unstructured data by deidentifying and obfuscating unstructured text, PDF files, images and other documents. Deidentification is sometimes required for AI model development, research, public policy and other use cases.
The challenge of unstructured data management
Customers across industries share similar fundamental challenges around data organization, integration, and accessibility. We’ve identified several common challenges organizations face with unstructured data:
- Fragmented storage: Data scattered across storage buckets, local workspaces, file systems, and various storage solutions.
- Limited discoverability: Without proper metadata, extraction and cataloging of valuable unstructured data, assets can remain hidden and underutilized.
- Integration complexity: Difficulty connecting related information across multimodal data types.
- Governance concerns: As data volumes grow, maintaining proper data lineage, access controls, and governance becomes increasingly difficult.
- Data deidentification: Balancing the need for data-driven insights while adhering to stringent privacy and compliance requirements presents significant challenges across multiple industries, particularly when needing to meet regulatory grade accuracy.
Amazon Bedrock Data Automation for unstructured data cataloging
Amazon Bedrock Data Automation is a powerful feature, of Amazon Bedrock, for automatically classifying, searching, and extracting insights from unstructured multimodal content such as documents, images, audio, and video for your data assets using AI. Let’s examine how it addresses key concerns.
Bedrock Data Automation streamlines the process of extracting valuable insights from unstructured data types such as medical images, electronic health record (EHR) reports (PDFs and images), and audio and video files. The service extracts your business and technical metadata through custom blueprints, making your unstructured data discoverable through comprehensive search capabilities. For research healthcare organizations this means images, scans, and other research data can be automatically cataloged and made searchable without manual tagging.
When integrated with other AWS services (such as AWS Glue and Amazon SageMaker Unified Studio), Bedrock Data Automation facilitates the creation of a solution to gain comprehensive insights through integrated views of previously siloed data assets.
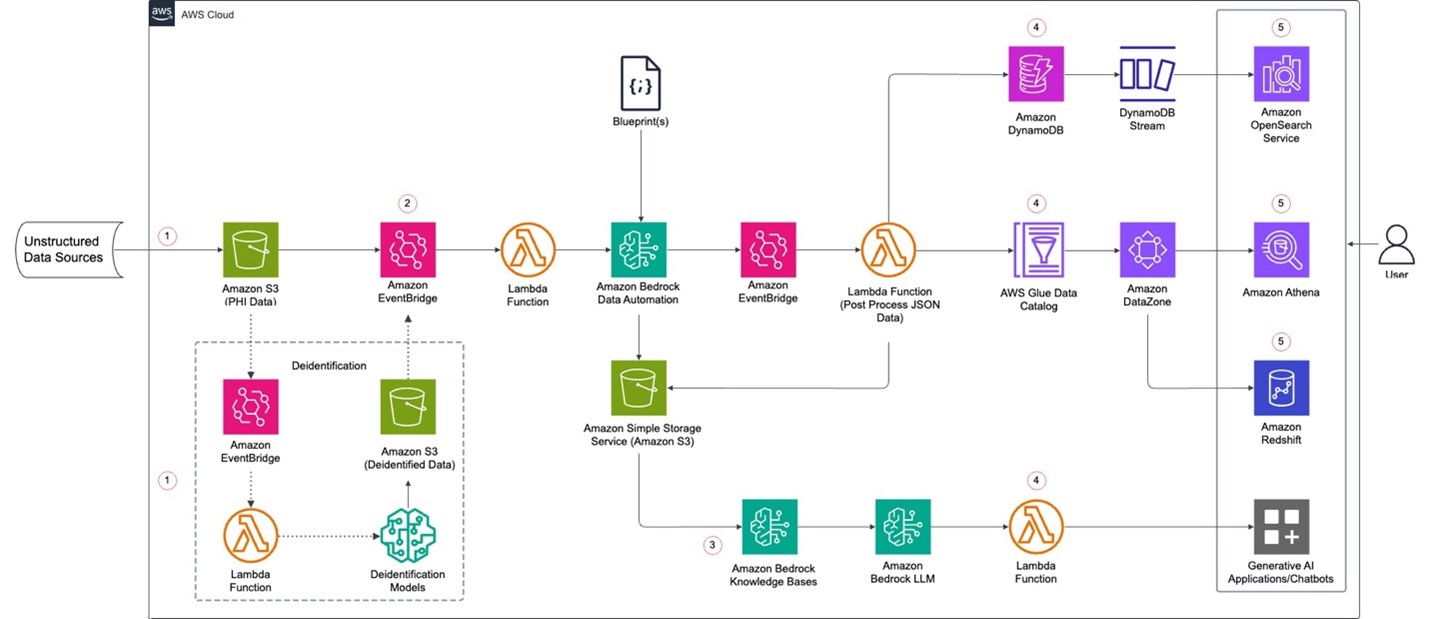
Figure 1 – High-level unstructured data catalog solution architecture
Unstructured data catalog solution: How it works
The solution implements a multi-stage architecture. Following is an explanation of the flow that is illustrated in Figure 1.
1 – Initial data ingestion and deidentification process
Data from unstructured, multimodal data sources is transferred to Amazon Simple Storage Service (Amazon S3), which serves as the primary data ingestion point. AWS provides a portfolio of data transfer services that can be used to transfer data from various unstructured enterprise data sources to Amazon S3 and other AWS services.
For organizations that also need to have deidentified data for various use cases, an event-driven architecture with a combination of Amazon EventBridge and AWS Lambda functions can be used. They can invoke various AWS deidentification services and solutions available on the AWS Marketplace to deidentify the data.
Organizations can also choose to develop their own deidentification solutions on AWS using a combination of various AWS services. There are many that can help, such as Amazon Textract, Amazon Comprehend, AWS Glue, Amazon Rekognition, Amazon Bedrock and others. The deidentified data can then be stored in Amazon S3.
AWS Marketplace provides a curated digital catalog of third-party solutions proven to scale for deidentification use cases across various industries. For example, for the healthcare industry, AWS Marketplace offerings include Partner solutions for clinical text deidentification, PDF deidentification and DICOM image and metadata deidentification, amongst others. These are available for real-time, or batch, transform jobs through various deployment options on AWS.
2 – Data processing pipeline
Amazon S3 triggers events through Amazon EventBridge, which is the next phase of data processing. Amazon EventBridge manages event-driven workflows and automated processes. EventBridge invokes Lambda functions, which processes the deidentified data and invokes Bedrock Data Automation for processing unstructured documents, images, audio and video files.
Bedrock Data Automation provides AI capabilities through foundation models and data automation features. Bedrock Data Automation extracts default metadata and custom metadata using customer provided blueprints. Processed data is stored in an S3 bucket. Alternatively, Bedrock Data Automation invokes Amazon EventBridge for further downstream processing of extracted data and metadata.
3 – Knowledge management
Processed data from Amazon S3 flows into Amazon Bedrock Knowledge Bases. Generative AI applications and chatbots provide interfaces for natural language interaction and automated responses, making the data accessible and actionable for end users.
4 – Centralized data storage and distribution layer
We are using multiple storage layers to cater to various needs of our customers. For hosting generative AI applications and chatbots, we are storing the processed data from Amazon S3 into Amazon Bedrock Knowledge Bases. For building centralized metadata store, AWS Glue ETL jobs will process the incoming data from Bedrock Data Automation, extract the metadata and store it in an AWS Glue Catalog.
Amazon DataZone imports the metadata from the AWS Glue Catalog and provides a unified portal for users to discover, share, and govern data, regardless of its underlying storage location. It utilizes the data catalog to provide a central repository of metadata and business context about data assets. Users can discover and understand data assets across different sources. Optionally we are using Amazon DynamoDB as a storage layer for metadata, which can integrate with Amazon OpenSearch Service.
5 – Analytics layer
Once the assets are in an Amazon DataZone catalog, users can query and analyze this data using Amazon Athena or Amazon Redshift Query Editor. This enables complex analytics at scale and comprehensive business intelligence operations. The integration of Amazon OpenSearch Service with DynamoDB enables powerful search capabilities and near real-time analytics.
Security and compliance
This solution’s architecture ensures protected health information (PHI) data is properly deidentified before further processing. It uses separate storage for raw and deidentified data. Amazon DataZone handles data governance, access control, and classification to verify proper data management and compliance.
Next Steps
Transform your data management journey with the solution we’ve outlined that utilizes the Amazon Bedrock Data Automation feature.
We recommend before starting:
- Map your unstructured data landscape
- Define clear success criteria for your organization’s needs
- Start with a focused pilot on your most valuable data assets to prove immediate value
- Scale your implementation across your organization, building on your initial success
Visit the GitHub Repository: Guidance for Multimodal Data Processing to begin today.
Conclusion
As unstructured data continues to grow exponentially across all industries, organizations that implement effective cataloging and management solutions will gain significant competitive advantages. The feature of Amazon Bedrock, Amazon Bedrock Data Automation, provides a powerful, scalable approach to transform unstructured data from a management challenge into a strategic asset when implemented.
Whether you’re a research institution or healthcare organization, our Bedrock Data Automation solution helps you classify, search, and extract insights from complex unstructured data. Our solution maintains appropriate governance and access controls while unlocking the full potential of your data assets.
Contact an AWS Representative to know how we can help accelerate your business.