Artificial Intelligence
Author: Bruno Klein
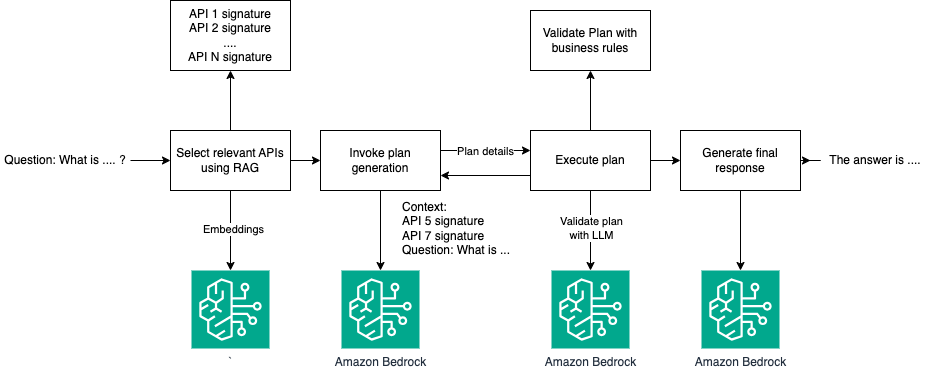
Using Large Language Models on Amazon Bedrock for multi-step task execution
This post explores the application of LLMs in executing complex analytical queries through an API, with specific focus on Amazon Bedrock. To demonstrate this process, we present a use case where the system identifies the patient with the least number of vaccines by retrieving, grouping, and sorting data, and ultimately presenting the final result.

Techniques and approaches for monitoring large language models on AWS
Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP), improving tasks such as language translation, text summarization, and sentiment analysis. However, as these models continue to grow in size and complexity, monitoring their performance and behavior has become increasingly challenging. Monitoring the performance and behavior of LLMs is a critical task […]

Best practices for viewing and querying Amazon SageMaker service quota usage
Amazon SageMaker customers can view and manage their quota limits through Service Quotas. In addition, they can view near real-time utilization metrics and create Amazon CloudWatch metrics to view and programmatically query SageMaker quotas. SageMaker helps you build, train, and deploy machine learning (ML) models with ease. To learn more, refer to Getting started with […]

Improve your data science workflow with a multi-branch training MLOps pipeline using AWS
In this post, you will learn how to create a multi-branch training MLOps continuous integration and continuous delivery (CI/CD) pipeline using AWS CodePipeline and AWS CodeCommit, in addition to Jenkins and GitHub. I discuss the concept of experiment branches, where data scientists can work in parallel and eventually merge their experiment back into the main […]