Artificial Intelligence
Author: Veronika Megler

Gain customer insights using Amazon Aurora machine learning
In recent years, AWS customers have been running machine learning (ML) on an increasing variety of datasets and data sources. Because a large percentage of organizational data is stored in relational databases such as Amazon Aurora, there’s a common need to make this relational data available for training ML models, and to use ML models […]

Exploring images on social media using Amazon Rekognition and Amazon Athena
If you’re like most companies, you wish to better understand your customers and your brand image. You’d like to track the success of your marketing campaigns, and the topics of interest—or frustration—for your customers. Social media promises to be a rich source of this kind of information, and many companies are beginning to collect, aggregate, […]

Exploring data warehouse tables with machine learning and Amazon SageMaker notebooks
Are you a data scientist with data warehouse tables that you’d like to explore in your machine learning (ML) environment? If so, read on. In this post, I show you how to perform exploratory analysis on large datasets stored in your data warehouse and cataloged in your AWS Glue Data Catalog from your Amazon SageMaker […]
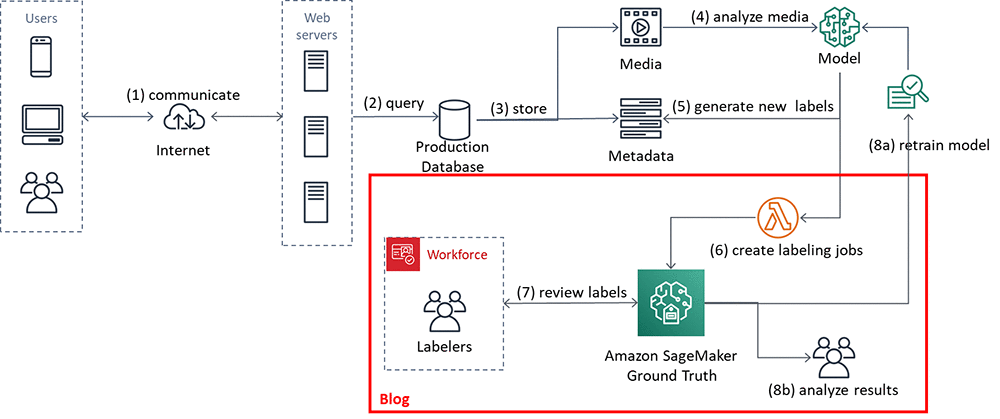
Easily perform bulk label quality assurance using Amazon SageMaker Ground Truth
In this blog post we’re going to walk you through an example situation where you’ve just built a machine learning system that labels your data at volume and you want to perform manual quality assurance (QA) on some of the labels. How can you do so without overwhelming your limited resources? We’ll show you how, […]
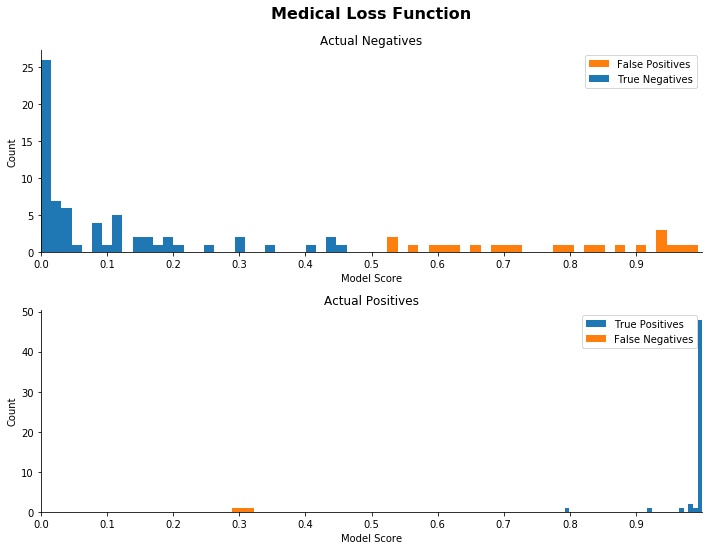
Training models with unequal economic error costs using Amazon SageMaker
Many companies are turning to machine learning (ML) to improve customer and business outcomes. They use the power of ML models built over “big data” to identify patterns and find correlations. Then they can identify appropriate approaches or predict likely outcomes based on data about new instances. However, as ML models are approximations of the […]

Access Amazon S3 data managed by AWS Glue Data Catalog from Amazon SageMaker notebooks
In this blog post, I’ll show you how to perform exploratory analysis on massive corporate data sets in Amazon SageMaker. From your Jupyter notebook running on Amazon SageMaker, you’ll identify and explore several corporate datasets in the corporate data lake that seem interesting to you. You’ll discover that each contains a subset of the information you need. You’ll join them to extract the interesting information, then continue analyzing and visualizing your data in your Amazon SageMaker notebook, in a seamless experience.