Artificial Intelligence
Category: Amazon Redshift

Build a semantic layer for agentic AI on AWS with Stardog and Amazon Bedrock AgentCore
In this post we show how to build a semantic layer on AWS using Stardog’s Semantic AI Application over Amazon Aurora and Amazon Redshift, and how to run a Strands Agents agent on Amazon Bedrock AgentCore that queries the layer to answer customer 360 questions across both sources without extract, transform, and load (ETL). The same Stardog deployment works behind AWS computes (Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), and AWS Lambda). We use AgentCore here because it bundles inbound auth, hosting, and tool credentials into one managed service.

Building agentic AI applications with a modern data mesh strategy on AWS
This post shows how to build a governed, serverless data mesh on AWS that provides the secure, scalable data foundation production agentic AI requires.

From data overload to actionable insights: How Verizon Connect scaled agentic AI to 100,000 users
In this post, we show you how Verizon Connect built and scaled an agentic AI solution to transform overwhelming fleet data into clear, actionable insights for 100,000 users daily. We walk you through the architectural decisions, implementation challenges, and measurable results that can guide your own data-to-insights transformation.

Building AI-ready data: Vanguard’s Virtual Analyst journey
In this post, you’ll learn how Vanguard built their Virtual Analyst solution by focusing on eight guiding principles of AI-ready data, the AWS services that powered their implementation, and the measurable business outcomes they achieved.

How Palo Alto Networks enhanced device security infra log analysis with Amazon Bedrock
Palo Alto Networks’ Device Security team wanted to detect early warning signs of potential production issues to provide more time to SMEs to react to these emerging problems. They partnered with the AWS Generative AI Innovation Center (GenAIIC) to develop an automated log classification pipeline powered by Amazon Bedrock. In this post, we discuss how Amazon Bedrock, through Anthropic’ s Claude Haiku model, and Amazon Titan Text Embeddings work together to automatically classify and analyze log data. We explore how this automated pipeline detects critical issues, examine the solution architecture, and share implementation insights that have delivered measurable operational improvements.

Build a conversational data assistant, Part 1: Text-to-SQL with Amazon Bedrock Agents
In this post, we focus on building a Text-to-SQL solution with Amazon Bedrock, a managed service for building generative AI applications. Specifically, we demonstrate the capabilities of Amazon Bedrock Agents. Part 2 explains how we extended the solution to provide business insights using Amazon Q in QuickSight, a business intelligence assistant that answers questions with auto-generated visualizations.

Choosing the right approach for generative AI-powered structured data retrieval
In this post, we explore five different patterns for implementing LLM-powered structured data query capabilities in AWS, including direct conversational interfaces, BI tool enhancements, and custom text-to-SQL solutions.

How Rocket Companies modernized their data science solution on AWS
In this post, we share how we modernized Rocket Companies’ data science solution on AWS to increase the speed to delivery from eight weeks to under one hour, improve operational stability and support by reducing incident tickets by over 99% in 18 months, power 10 million automated data science and AI decisions made daily, and provide a seamless data science development experience.
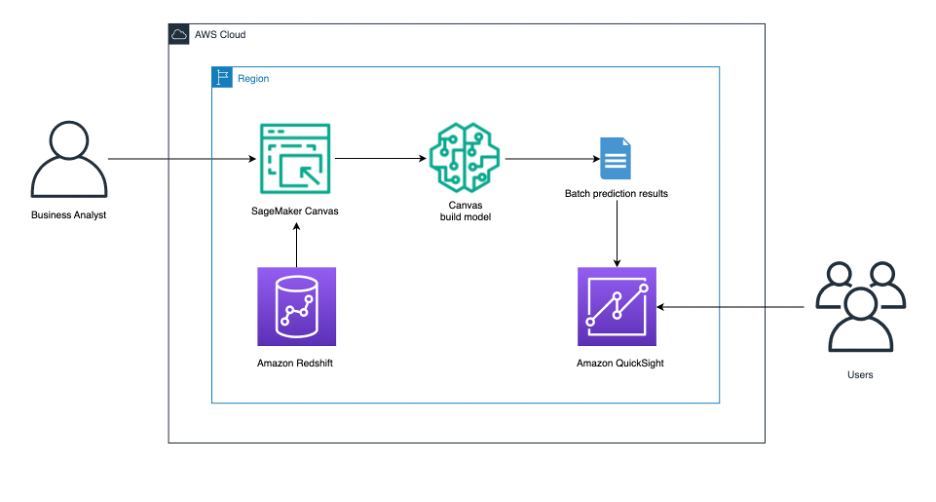
Enhance your Amazon Redshift cloud data warehouse with easier, simpler, and faster machine learning using Amazon SageMaker Canvas
In this post, we dive into a business use case for a banking institution. We will show you how a financial or business analyst at a bank can easily predict if a customer’s loan will be fully paid, charged off, or current using a machine learning model that is best for the business problem at hand.

Exploring data using AI chat at Domo with Amazon Bedrock
In this post, we share how Domo, a cloud-centered data experiences innovator is using Amazon Bedrock to provide a flexible and powerful AI solution.