Artificial Intelligence
Build multi-class classification models with Amazon Redshift ML
July 2024: This post was reviewed and updated for accuracy.
Amazon Redshift ML simplifies the use of machine learning (ML) by using simple SQL statements to create and train ML models from data in Amazon Redshift. You can use Amazon Redshift ML to solve binary classification, multi-class classification, and regression problems and can use either AutoML or XGBoost directly.
This post is part of a series that describes the use of Amazon Redshift ML. For more information about building regression using Amazon Redshift ML, see Build regression models with Amazon Redshift ML.
You can use Amazon Redshift ML to automate data preparation, pre-processing, and selection of problem type as depicted in this blog post. We assume that you have a good understanding of your data and what problem type is most applicable for your use case. This post specifically focuses on creating models in Amazon Redshift using the multi-class classification problem type, which consists on classifying instances into one of three or more classes. For example, you can predict whether a transaction is fraudulent, failed or successful, whether a customer will remain active for 3 months, six months, nine months, 12 months, or whether a news is tagged as sports, world news, business.
| Want to learn more about Amazon Redshift ML? These posts might interest you: |
Prerequisites
To get started, we need an Amazon Redshift cluster or an Amazon Redshift Serverless endpoint and an AWS Identity and Access Management (IAM) role attached that provides access to SageMaker and permissions to an Amazon Simple Storage Service (Amazon S3) bucket.
For an introduction to Redshift ML and instructions on setting it up, see Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML.
To create a simple cluster with a default IAM role, see Use the default IAM role in Amazon Redshift to simplify accessing other AWS services.
Use case
For our use case, we want to target our most active customers for a special customer loyalty program. We use Amazon Redshift ML and multi-class classification to predict how many months a customer will be active over a 13-month period. This translates into up to 13 possible classes, which makes this a better fit for multi-class classification. Customers with predicted activity of 7 months or greater are targeted for a special customer loyalty program.
Input raw data
To prepare the raw data for this model, we populated the table ecommerce_sales in Amazon Redshift using the public data set E-Commerce Sales Forecast, which includes sales data of an online UK retailer.
Enter the following statements to load the data to Amazon Redshift:
Alternately we have provided a notebook you may use to execute all the sql commands that can be downloaded here. You will find instructions in this blog on how to import and use notebooks.
Data preparation for the ML model
Now that our data set is loaded, we can optionally split the data into three sets for training (80%), validation (10%), and prediction (10%). Note that Amazon Redshift ML Autopilot will automatically split the data into training and validation, but by splitting it here, you will be able to verify the accuracy of your model. Additionally, we calculate the number of months a customer has been active, as it will be the value we want our model to predict on new data. We use the random function in our SQL statements to split the data. See the following code:
Training Set
Validation Set
Prediction Set
Create the model in Amazon Redshift
Now that we created our training and validation data sets, we can use the create model statement in Amazon Redshift to create our ML model using Multiclass_Classification. We specify the problem type but we let AutoML take care of everything else. In this model, the target we want to predict is nbr_months_active. Amazon SageMaker creates the function predict_customer_activity, which we use to do inference in Amazon Redshift. See the following code:
Validate predictions
In this step, we evaluate the accuracy of our ML model against our validation data.
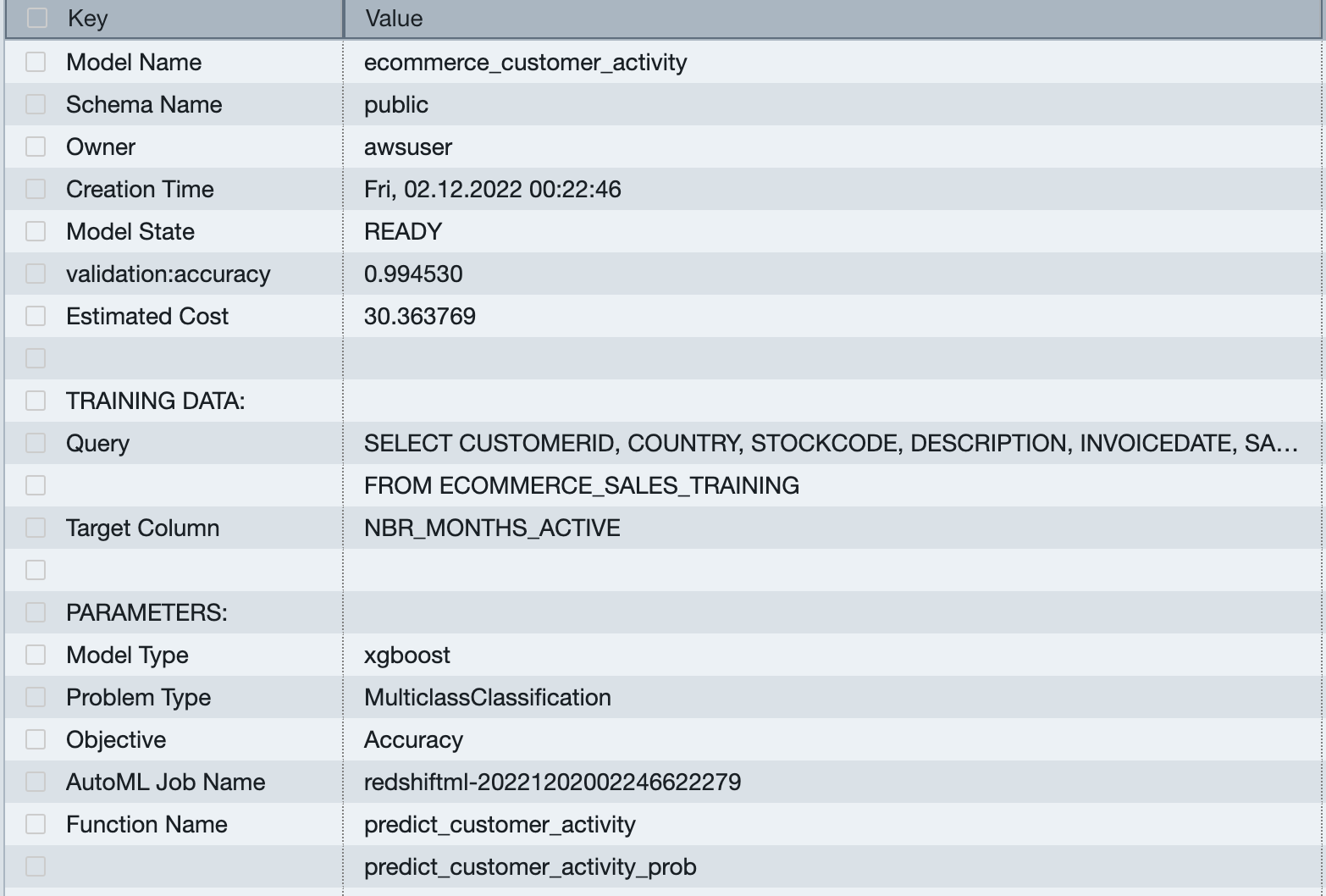
While creating the model, Amazon SageMaker Autopilot automatically splits the input data into train and validation sets, and selects the model with the best objective metric, which is deployed in the Amazon Redshift cluster. You can use the show model statement in your cluster to view various metrics, including the accuracy score. If you don’t specify explicitly, SageMaker automatically uses accuracy for the objective type. See the following code:
As shown in following output, our model has an accuracy score of 0.994530.
Let’s run inference queries against our validation data using the following SQL code against the validation data:
We can see that we predicted correctly on nearly 80% on our validation data set.
| predicted_matches | predicted_non_matches | total_predictions | pct_accuracy |
| 35249.00 | 8603.00 | 43852.00 | 0.80381738 |
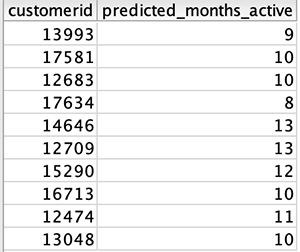
Now let’s run a query to see which customers qualify for our customer loyalty program by being active for at least 7 months:
The following table shows our output.
Redshift ML now supports Prediction Probabilities for classification models. For classification problem in machine learning, for a given record, each label can be associated with a probability that indicates how likely this record really belongs to the label. With option to have probabilities along with the label, customers could use the classification results when confidence based on chosen label is higher than a certain threshold value returned by the model.
Prediction probabilities are calculated by default for classification models and an additional function is created while creating model without impacting performance of the ML model.
Now let’s run the query to use the prediction probabilities function by using the new function – predict_customer_activity_prod. Prediction probabilities provides label prediction based on the value which helps understand probability of the prediction.
Run the following query for one customer to see the probability output:
This query results shows prediction probabilities for all 13 labels (or classes) for these two accounts in the multi-classification model. We have multiple rows since a given customer may have multiple purchases.

Let’s run below query to get label and prediction probabilities values of the first label for these two customers. As you can see label denotes nbr_of_months and probabilities column values show confidence of label value.

Now you can run a query to get prediction probability to two decimal places which could be useful when using this value for setting the threshold and using it to decide if label should be used.

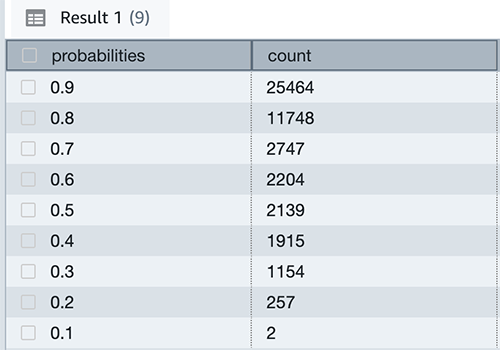
It is important to validate the model using prediction probabilities by running on whole inference data set and see the percentile. This helps in determining thresholds when to use predicted label with higher degree of confidence. You can run below query to calculate probabilities with total counts on whole inference data set to understand how many customers the active months label lies in probabilities percentile.
Redshift ML is able to identify the right combination of features to come up with a usable prediction model with Model Explainability. It helps explain how these models make predictions using a feature attribution approach which in turn helps improve your ML models. We can check impact of each attribute and its contribution and weightage in the model selection using the following command:
The following output is from the above command, where each attribute weightage is representative of its role in the model decision-making.
Troubleshooting
Although the Create Model statement in Amazon Redshift automatically takes care of initiating the SageMaker Autopilot process to build, train, and tune the best ML model and deploy that model in Amazon Redshift, you can view the intermediate steps performed in this process, which may also help you with troubleshooting if something goes wrong. You can also retrieve the AutoML Job Name from the output of the show model command.
While creating the model, you need to mention an Amazon Simple Storage Service (Amazon S3) bucket name as the value for parameter, s3_bucket. You use this bucket to share training data and artifacts between Amazon Redshift and SageMaker. Amazon Redshift creates a subfolder in this bucket prior to unload of the training data. When training is complete, it deletes the subfolder and its contents unless you set the parameter s3_garbage_collect to off, which you can use for troubleshooting purposes. For more information, see CREATE MODEL.
For information about using the SageMaker console and Amazon SageMaker Studio, see Build regression models with Amazon Redshift ML.
Conclusion
Amazon Redshift ML provides the right platform for database users to create, train, and tune models using a SQL interface. In this post, we walked you through how to create a multi-class classification model. We hope you can take advantage of Amazon Redshift ML to help gain valuable insights.
For more information about building different models with Amazon Redshift ML, see Build regression models with Amazon Redshift ML and read the Amazon Redshift ML documentation.
Acknowledgments
Per the UCI Machine Learning Repository, this data was made available by Dr Daqing Chen, Director: Public Analytics group. chend ‘@’ lsbu.ac.uk, School of Engineering, London South Bank University, London SE1 0AA, UK.
Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
About the Authors
 Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS with over 25 years of data warehouse experience.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS with over 25 years of data warehouse experience.
 Debu Panda, a principal product manager at AWS, is an industry leader in analytics, application platform, and database technologies and has more than 25 years of experience in the IT world.
Debu Panda, a principal product manager at AWS, is an industry leader in analytics, application platform, and database technologies and has more than 25 years of experience in the IT world.
 Nikos Koulouris is a Software Development Engineer at AWS. He received his PhD from University of California, San Diego and he has been working in the areas of databases and analytics.
Nikos Koulouris is a Software Development Engineer at AWS. He received his PhD from University of California, San Diego and he has been working in the areas of databases and analytics.
 Enrico Sartorello is a Sr. Software Development Engineer at Amazon Web Services. He helps customers adopt machine learning solutions that fit their needs by developing new functionalities for Amazon SageMaker. In his spare time, he passionately follows his soccer team and likes to improve his cooking skills.
Enrico Sartorello is a Sr. Software Development Engineer at Amazon Web Services. He helps customers adopt machine learning solutions that fit their needs by developing new functionalities for Amazon SageMaker. In his spare time, he passionately follows his soccer team and likes to improve his cooking skills.
 Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build next-generation analytics solutions using other AWS Analytics services.
Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build next-generation analytics solutions using other AWS Analytics services.