Artificial Intelligence
Translate, redact, and analyze text using SQL functions with Amazon Redshift, Amazon Translate, and Amazon Comprehend
You may have tables in your Amazon Redshift data warehouse or in your Amazon Simple Storage Service (Amazon S3) data lake full of records containing customer case notes, product reviews, and social media messages, in many languages. Your task is to identify the products that people are talking about, determine if they’re expressing happy thoughts or sad thoughts, translate their comments into a single common language, and create copies of the data for your business analysts with this new information added to each record. Additionally, you need to remove any personally identifiable information (PII), such as names, addresses, and credit card numbers.
You already know how to use Amazon Redshift to transform data using simple SQL commands and built-in functions. Now you can also use Amazon Redshift to translate, analyze, and redact text fields, thanks to Amazon Translate, Amazon Comprehend, and the power of Amazon Redshift supported AWS Lambda user-defined functions (UDFs).

With Amazon Redshift, you can query and combine structured and semi-structured data across your data warehouse, operational database, and data lake using standard SQL. Amazon Comprehend is a natural language processing (NLP) service that makes it easy to uncover insights from text. Amazon Translate is a neural machine translation service that delivers fast, high-quality, affordable, and customizable language translation. In this post, I show you how you can now use them together to perform the following actions:
- Detect and redact PII
- Detect and redact entities (such as items, places, or quantities)
- Detect the dominant language of a text field
- Detect the prevailing sentiment expressed—positive, negative, neither, or both
- Translate text from one language to another
This post accomplishes the following goals:
- Show you how to quickly set up the Amazon Redshift text analytics functions in your own AWS account (it’s fast and easy!)
- Briefly explain how the functions work
- Discuss performance and cost
- Provide a tutorial where we do some text analytics on Amazon product reviews
- Describe all the available functions
We include a list of all the available functions at the end of the post; the following code shows a few example queries and results:
Prerequisites
If you’re new to Amazon Redshift, review the Getting Started guide to set up your cluster and SQL client.
Install the text analytics UDF
An Amazon Redshift UDF uses Lambda to implement the function capability. I discuss more details later in this post, but you don’t need to understand the inner workings to use the text analytics UDF, so let’s get started.
Install the prebuilt Lambda function with the following steps:
- Navigate to the RedshiftTextAnalyticsUDF application in the AWS Serverless Application Repository.
- In the Application settings section, keep the settings at their defaults.
- Select I acknowledge that this app creates custom IAM roles.
- Choose Deploy.

- When the application has deployed, choose the application Deployments tab and then CloudFormation stack.

- Choose the stack Outputs tab.

- Select the ARN that is shown as the value of the output labeled
RedshiftLambdaInvokeRoleand copy to the clipboard. - On the Amazon Redshift console, in the navigation menu, choose CLUSTERS, then choose the name of the cluster that you want to update.
- For Actions, choose Manage IAM roles.
- Choose Enter ARN and enter the ARN for the role that you copied earlier.
- Choose Associate IAM role to add it to the list of Attached IAM roles.
- Choose Save changes to associate the IAM role with the cluster.
- Select the SQL code that is shown as the value of the output labeled
SQLScriptExternalFunctionand copy to the clipboard.

- Paste this SQL into your SQL client, and run it on your Amazon Redshift database as an admin user.

And that’s it! Now you have a suite of new Lambda backed text analytics functions. You’re ready to try some text analytics queries in Amazon Redshift.
If you prefer to build and deploy from the source code instead, see the directions in the GitHub repository README.
Run your first text analytics query
Enter the following query into the SQL editor:
You get a simple POSITIVE result. Now try again, varying the input text—try something less positive to see how the returned sentiment value changes.
To get the sentiment along with confidence scores for each potential sentiment value, use the following query instead:
Now you get a JSON string containing the sentiment and all the sentiment scores:
You can use the built-in support in Amazon Redshift for semi-structured data on this result to extract the fields for further analysis. For more information, see Ingesting and querying semistructured data in Amazon Redshift. I show you examples later in this post.
How the UDF works
For more information about the Amazon Redshift UDF framework, see Creating a scalar Lambda UDF.
The Java class TextAnalyticsUDFHandler implements the core logic for each of our UDF Lambda function handlers. Each text analytics function has a corresponding public method in this class.
Amazon Redshift invokes our UDF Lambda function with batches of input records. The TextAnalyticsUDFHandler subdivides these batches into smaller batches of up to 25 rows to take advantage of the Amazon Comprehend synchronous multi-document batch APIs where they are available (for example, for detecting language, entities, and sentiment). When no synchronous multi-document API is available (such as for DetectPiiEntity and TranslateText), we use the single-document API instead.
Amazon Comprehend API service quotas provide guardrails to limit your cost exposure from unintentional high usage (we discuss this more in the following section). By default, the multi-document batch APIs process up to 250 records per second, and the single-document APIs process up to 20 records per second. Our UDFs use exponential backoff and retry to throttle the request rate to stay within these limits. You can request increases to the transactions per second quota for APIs using the Quota Request Template on the AWS Management Console.
Amazon Comprehend and Amazon Translate each enforce a maximum input string length of 5,000 utf-8 bytes. Text fields that are longer than 5,000 utf-8 bytes are truncated to 5,000 bytes for language and sentiment detection, and split on sentence boundaries into multiple text blocks of under 5,000 bytes for translation and entity or PII detection and redaction. The results are then combined.
Optimize cost
In addition to Amazon Redshift costs, the text analytics UDFs incur usage costs from Lambda, Amazon Comprehend, and Amazon Translate. The amount you pay is a factor of the total number of records and characters that you process with the UDFs. For more information, see AWS Lambda pricing, Amazon Comprehend pricing, and Amazon Translate pricing.
To minimize the costs, I recommend that you avoid processing the same records multiple times. Instead, materialize the results of the text analytics UDF in a table that you can then cost-effectively query as often as needed without incurring additional UDF charges. Process newly arriving records incrementally using INSERT INTO…SELECT queries to analyze and enrich only the new records and add them to the target table.
Avoid calling the text analytics functions needlessly on records that you will subsequently discard. Write your queries to filter the dataset first using temporary tables, views, or nested queries, and then apply the text analytics functions to the resulting filtered records.
Always assess the potential cost before you run text analytics queries on tables with vary large numbers of records.
In this section, we provide two example cost assessments.
Example 1: Analyze the language and sentiment of tweets
Let’s assume you have 10,000 tweet records, with average length 100 characters per tweet. Your SQL query detects the dominant language and sentiment for each tweet. You’re in your second year of service (the Free Tier no longer applies). The cost details are as follows:
- Size of each tweet = 100 characters
- Number of units (100 character) per record (minimum is 3 units) = 3
- Total units = 10,000 (records) x 3 (units per record) x 2 (Amazon Comprehend requests per record) = 60,000
- Price per unit = $0.0001
- Total cost for Amazon Comprehend = [number of units] x [cost per unit] = 60,000 x $0.0001 = $6.00
Example 2: Translate tweets
Let’s assume that 2,000 of your tweets aren’t in your local language, so you run a second SQL query to translate them. The cost details are as follows:
- Size of each tweet = 100 characters
- Total characters = 2,000 (records) * 100 (characters per record) x 1 (Translate requests per record) = 200,000
- Price per character = $0.000015
- Total cost for Amazon Translate = [number of characters] x [cost per character] = 200,000 x $0.000015 = $3.00
Analyze insights from customer reviews
It’s time to put our new text analytics queries to use.
For a tutorial on using Amazon Comprehend to get actionable insights from customer reviews, see Tutorial: Analyzing Insights from Customer Reviews with Amazon Comprehend. In this post, I provide an alternate approach using SQL queries powered by Amazon Redshift and Amazon Comprehend.
The tutorial takes approximately 15 minutes to complete, and costs up to $1.40 for Amazon Comprehend and Amazon Translate—there is no cost if you’re eligible for the Free Tier.
Configure Amazon Redshift Spectrum and create external schema
In this section, you create an AWS Identity and Access Management (IAM) role, associate the role with your cluster, and create an external schema. Skip this section if you have previously configured Amazon Redshift Spectrum on your Amazon Redshift cluster.
- On the IAM console, in the navigation pane, choose Roles.
- Choose Create role.
- Choose AWS service, then choose Redshift.
- Under Select your use case, choose Redshift – Customizable, then choose Next: Permissions.
- On the Attach permissions policy page, choose the policies
AmazonS3ReadOnlyAccess,AWSGlueConsoleFullAccess, andAmazonAthenaFullAccess. - Choose Next: Review.
- For Role name, enter a name for your role, for example
mySpectrumRole. - Review the information, then choose Create role.
- In the navigation pane, choose Roles.
- Choose the name of your new role to view the summary, then copy the Role ARN to your clipboard.
This value is the Amazon Resource Name (ARN) for the role that you just created. You use that value when you create external tables to reference your data files on Amazon S3.
- On the Amazon Redshift console, in the navigation menu, choose CLUSTERS, then choose the name of the cluster that you want to update.
- For Actions, choose Manage IAM roles.
The IAM roles page appears.
- Choose Enter ARN and enter the ARN for the role that you copied earlier.
- Choose Add IAM role to add it to the list of Attached IAM roles.
- Choose Done to associate the IAM role with the cluster.
The cluster is modified to complete the change.
- To create an external schema called spectrum, replace the IAM role ARN in the following command with the role ARN you created. Then run the following SQL statement on your Amazon Redshift cluster using your SQL client:
Configure Redshift Spectrum access to the Amazon product reviews dataset
We use the Amazon Customer Reviews Dataset. This sample data set is no longer available, but you can use your own data sets to run the solution.
- Create an external table by running the following SQL statement on your Amazon Redshift cluster:
- Load a table partition for one
product_category:
- In your Amazon Redshift SQL client, run the following query to copy video and DVD reviews from the UK in the year 2000 (628 reviews) to an Amazon Redshift internal table:
- Run the following query to assess the average review length:
The average review length is around 627 characters. This equates to 7 Amazon Comprehend units per record (1 unit = 100 characters).
Detect the language for each review
To detect the language of each review, run the following query in the Amazon Redshift query editor—it takes about 10 seconds to run and costs $0.40:
The first query creates a new column, language. The second query populates it with the results of the new UDF, f_detect_dominant_language().
Cost is calculated as: 628 (records) x 7 (units per record) x 1 (requests per record) x $0.0001 (Amazon Comprehend price per unit) = $0.44.
Run the following query to see the detected language codes, with the corresponding count of reviews for each language:
Seven of the reviews have been written in German (de).
Translate all reviews into one language
Our analysis will be easier if the reviews are all normalized into a common language. Run the following SQL to create and populate a new column with the English version of all reviews. It takes around 7 seconds to run, and costs $0.07.
The first statement creates a new column, review_body_en. The second statement populates it with the results of the new UDF, f_translate_text().
Cost is calculated as: 7 (non-English records) x 627 (characters per record) x 1 (requests per record) x $0.000015 (Amazon Translate price per character) = $0.07.
Run the following query to see a few of the reviews translated from the original language to English:

Detect sentiment and entities for each review
To detect sentiment, run the following SQL statements—they use two text analytics functions, take around 25 seconds to run, and cost $0.88:
We add two additional columns, sentiment and entities, each using the Amazon Redshift semi-structured data type SUPER. For more information, see Ingesting and querying semistructured data in Amazon Redshift.
The UPDATE query passes the English translation of each review to the new UDF functions f_detect_sentiment_all() and f_detect_entities_all(). These functions return JSON strings, which the query parses and stores in the new columns.
Cost is calculated as: 628 (records) x 7 (units per record) x 2 (requests per record) x $0.0001 (Amazon Comprehend price per unit) = $0.88.
Inspect some of the values for the new sentiment and entities columns:
As expected, they contain nested structures and fields containing the results from Amazon Comprehend.

Next, let’s use the support in Amazon Redshift for semi-structured data to prepare these columns for analysis.
Prepare sentiment for analysis
Run the following SQL query to create a new table containing sentiment and sentiment scores expanded into separate columns:
Preview the new sentiment_results_final table. Does the sentiment generally align with the text of the review_body field? How does it correlate with the star_rating? If you spot any dubious sentiment assignments, check the confidence scores to see if the sentiment was assigned with a low confidence.
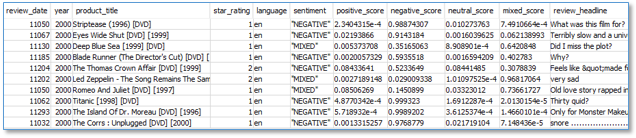

Prepare entities for analysis
Run the following Amazon Redshift SQL query to create a new table containing detected entities unnested into separate rows, with each field in a separate column:
Preview the contents of the new table, entities_results_final:

Visualize in Amazon QuickSight (optional)
As an optional step, you can visualize your results with Amazon QuickSight. For instructions, see Step 5: Visualizing Amazon Comprehend Output in Amazon QuickSight.
You can use the new word cloud visual type for entities, instead of tree map. In the word cloud chart menu, select Hide “other” categories.
You now have a dashboard with sentiment and entities visualizations that looks similar to the following screenshot.

Troubleshooting
If your query fails, check the Amazon CloudWatch metrics and logs generated by the UDF Lambda function.
- On the Lambda console, find the desired
RedshiftTextAnalyticsUDFfunction. - Choose Monitoring.
You can view the CloudWatch metrics showing how often the function ran, how long it ran for, how often it failed, and more.
- Choose View logs in CloudWatch to open the function log streams for additional troubleshooting insights.
For more information about viewing CloudWatch metrics via Lambda, see Using the Lambda console.
Additional use cases
There are many use cases for Amazon Redshift SQL text analytics functions. In addition to the example shown in this post, consider the following:
- Prepare research-ready datasets by redacting PII from customer or patient interactions
- Simplify extract, transform, and load (ETL) pipelines by using incremental SQL queries to enrich text data with sentiment and entities, such as streaming social media streams ingested by Amazon Kinesis Data Firehose
- Use SQL queries to explore sentiment and entities in your customer support texts, emails, and support cases
- Standardize many languages to a single common language
You may have additional use cases for these functions, or additional capabilities you want to see added, such as the following:
- SQL functions to call custom entity recognition and custom classification models in Amazon Comprehend
- SQL functions for de-identification—extending the entity and PII redaction functions to replace entities with alternate unique identifiers
The implementation is open source, which means that you can clone the repo, modify and extend the functions as you see fit, and (hopefully) send us pull requests so we can merge your improvements back into the project and make it better for everyone.
Clean up
After you complete this tutorial, you might want to clean up any AWS resources you no longer want to use. Active AWS resources can continue to incur charges in your account.
- On the Amazon Redshift console, run the following statements to drop the database and all the tables:
- On the AWS CloudFormation console, delete the stack
serverlessrepo-RedshiftTextAnalyticsUDF. - Cancel your QuickSight subscription.
Conclusion
I have shown you how to install the sample text analytics UDF Lambda function for Amazon Redshift, so that you can use simple SQL queries to translate text using Amazon Translate, generate insights from text using Amazon Comprehend, and redact sensitive information. I hope you find this useful, and share examples of how you can use it to simplify your architectures and implement new capabilities for your business.
The SQL functions described here are also available for Amazon Athena. For more information, see Translate, redact, and analyze text using SQL functions with Amazon Athena, Amazon Translate, and Amazon Comprehend.
Please share your thoughts with us in the comments section, or in the issues section of the project’s GitHub repository.
Appendix: Available function reference
This section summarizes the functions currently provided. The README file provides additional details.
Detect language
This function uses the Amazon Comprehend BatchDetectDominantLanguage API to identify the dominant language based on the first 5,000 bytes of input text.
The following code returns a language code, such as fr for French or en for English:
The following code returns a JSON formatted array of language codes and corresponding confidence scores:
Detect sentiment
This function uses the Amazon Comprehend BatchDetectSentiment API to identify the sentiment based on the first 5,000 bytes of input text.
The following code returns a sentiment as POSITIVE, NEGATIVE, NEUTRAL, or MIXED:
The following code returns a JSON formatted object containing detected sentiment and confidence scores for each sentiment value:
Detect entities
This function uses the Amazon Comprehend DetectEntities API to identify PII. Input text longer than 5,000 bytes results in multiple Amazon Comprehend API calls.
The following code returns a JSON formatted object containing an array of entity types and values:
The following code returns a JSON formatted object containing an array of PII entity types, with their values, scores, and character offsets:
Redact entities
This function replaces entity values for the specified entity types with “[ENTITY_TYPE]”. Input text longer than 5,000 bytes results in multiple Amazon Comprehend API calls. See the following code:
The command returns a redacted version on the input string. Specify one or more entity types to redact by providing a comma-separated list of valid types in the types string parameter, or ALL to redact all types.
Detect PII
This function uses the DetectPiiEntities API to identify PII. Input text longer than 5,000 bytes results in multiple Amazon Comprehend API calls.
The following code returns a JSON formatted object containing an array of PII entity types and values:
The following code returns a JSON formatted object containing an array of PII entity types, with their scores and character offsets:
Redact PII
This function replaces the PII values for the specified PII entity types with “[PII_ENTITY_TYPE]”. Input text longer than 5,000 bytes results in multiple Amazon Comprehend API calls. See the following code:
The function returns a redacted version on the input string. Specify one or more PII entity types to redact by providing a comma-separated list of valid types in the type string parameter, or ALL to redact all type.
Translate text
This function translates text from the source language to the target language. Input text longer than 5,000 bytes results in multiple Amazon Translate API calls. See the following code:
The function returns the translated string. Optionally, auto-detect the source language (use ‘auto‘ as the language code, which uses Amazon Comprehend), and optionally specify a custom terminology (otherwise use ‘null‘ for customTerminologyName).
About the Author
 Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.