Artificial Intelligence
Bring Your Amazon SageMaker model into Amazon Redshift for remote inference
July 2024: This post was reviewed and updated for accuracy.
Amazon Redshift, a fast, fully managed, widely used cloud data warehouse, natively integrates with Amazon SageMaker for machine learning (ML). Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Data analysts and database developers want to use this data to train ML models, which can then be used to generate insights for use cases such as forecasting revenue, predicting customer churn, and detecting anomalies.
Amazon Redshift ML makes it easy for SQL users to create, train, and deploy ML models using familiar SQL commands. In a previous post, we covered how Amazon Redshift ML allows you to use your data in Amazon Redshift with SageMaker, a fully managed ML service, without requiring you to become an expert in ML. We also discussed how Amazon Redshift ML enables ML experts to create XGBoost or MLP models in an earlier post. Additionally, Amazon Redshift ML allows data scientists to either import existing SageMaker models into Amazon Redshift for in-database inference or remotely invoke a SageMaker endpoint.
This post shows how you can enable your data warehouse users to use SQL to invoke a remote SageMaker endpoint for prediction. We first train and deploy a Random Cut Forest model in SageMaker, and demonstrate how you can create a model with SQL to invoke that SageMaker predictions remotely. Then, we show how end users can invoke the model.
Prerequisites
To get started, we need an Amazon Redshift cluster with the Amazon Redshift ML feature enabled. For an introduction to Amazon Redshift ML and instructions on setting it up, see Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML.
You also have to make sure that the SageMaker model is deployed and you have the endpoint. You can use the following AWS CloudFormation template to provision all the required resources in your AWS accounts automatically.
Solution overview
Amazon Redshift ML supports text and CSV inference formats. For more information about various SageMaker algorithms and their inference formats, see Random Cut Forest (RCF) Algorithm.
Amazon SageMaker Random Cut Forest (RCF) is an algorithm designed to detect anomalous data points within a dataset. Examples of anomalies that are important to detect include when website activity uncharacteristically spikes, when temperature data diverges from a periodic behavior, or when changes to public transit ridership reflect the occurrence of a special event.
In this post, we use the SageMaker RCF algorithm to train an RCF model using the Notebook generated by the CloudFormation template on the Numenta Anomaly Benchmark (NAB) NYC Taxi dataset.
We downloaded the data and stored it in an Amazon Simple Storage Service (Amazon S3) bucket. The data consists of the number of New York City taxi passengers over the course of 6 months aggregated into 30-minute buckets. We naturally expect to find anomalous events occurring during the NYC marathon, Thanksgiving, Christmas, New Year’s Day, and on the day of a snowstorm.
We then use this model to predict anomalous events by generating an anomaly score for each data point.
The following figure illustrates how we use Amazon Redshift ML to create a model using the SageMaker endpoint.
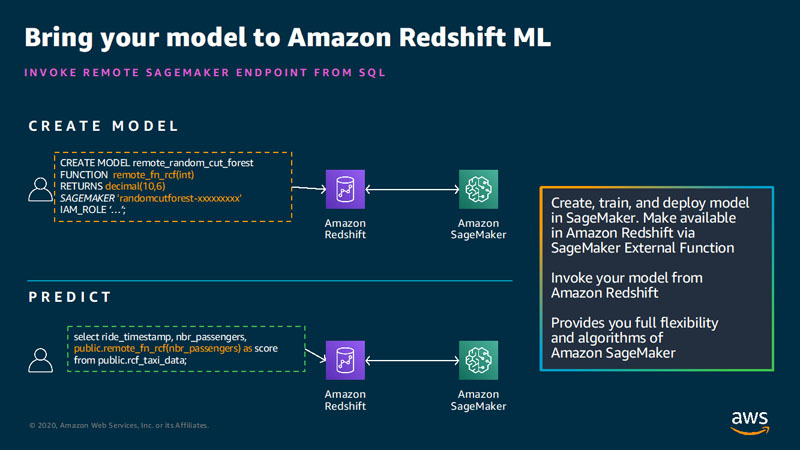
Deploy the model
To deploy the model, go to the SageMaker console and open the notebook that was created by the CloudFormation template.

Then choose bring-your-own-model-remote-inference.ipynb.

Set up parameters as shown in the following screenshot and then run all cells.

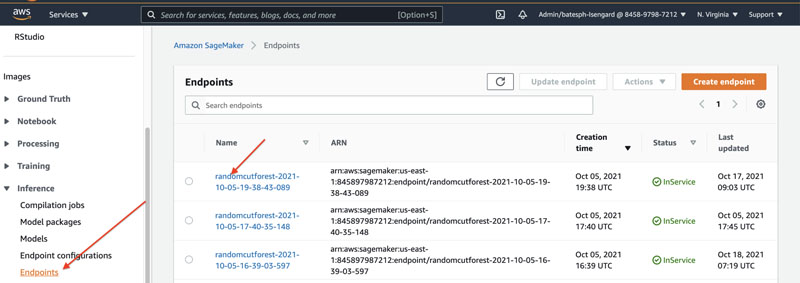
Get the SageMaker model endpoint
On the Amazon SageMaker console, under Inference in the navigation pane, choose Endpoints to find your model name. You use this when you create the remote inference model in Amazon Redshift.
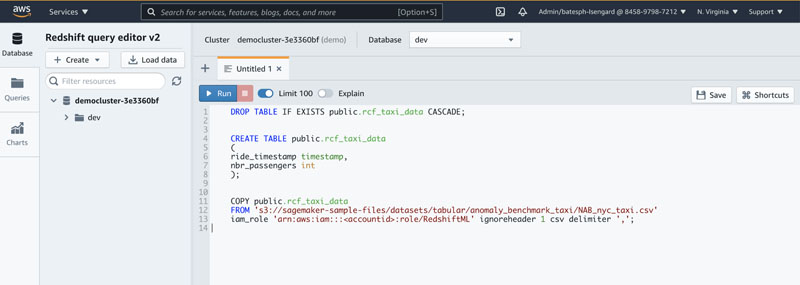
Prepare data to create a remote inference model using Amazon Redshift ML
Create the schema and load the data in Amazon Redshift using the following SQL:
Amazon Redshift now supports attaching the default IAM role. If you have enabled the default IAM role in your cluster, you can use the default IAM role as follows.
You can use the Amazon Redshift query editor v2 to run these commands.
Create a model
Create a model in Amazon Redshift ML using the SageMaker endpoint you previously captured:
Check model status
You can use the show model command to view the status of the model:
You get output like the following screenshot, which shows the endpoint and function name.

Compute anomaly scores across the entire taxi dataset
Now, run the inference query using the function name from the create model statement:
The following screenshot shows our results.

Now that we have our anomaly scores, we need to check for higher-than-normal anomalies.
Amazon Redshift ML has batching optimizations to minimize the communication cost with SageMaker and offers high-performance remote inference.
Check for high anomalies
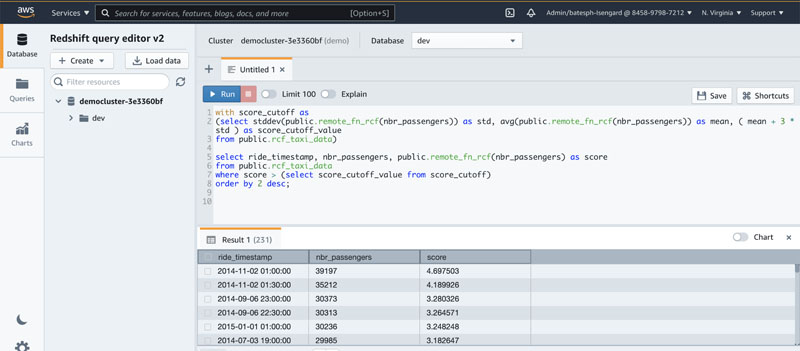
The following code runs a query for any data points with scores greater than three standard deviations (approximately 99.9th percentile) from the mean score:
The data in the following screenshot shows that the biggest spike in ridership occurs on November 2, 2014, which was the annual NYC marathon. We also see spikes on Labor Day weekend, New Year’s Day and the July 4th holiday weekend.
Conclusion
In this post, we used SageMaker Random Cut Forest to detect anomalous data points in a taxi ridership dataset. In this data, the anomalies occurred when ridership was uncharacteristically high or low. However, the RCF algorithm is also capable of detecting when, for example, data breaks periodicity or uncharacteristically changes global behavior.
We then used Amazon Redshift ML to demonstrate how you can make inferences on unsupervised algorithms (such as Random Cut Forest). This allows you to democratize ML by making predictions with Amazon Redshift SQL commands.
For more information about building different models with Amazon Redshift ML see the Amazon Redshift ML documentation.
About the Authors
 Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS with over 25 years of data warehouse experience.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS with over 25 years of data warehouse experience.
 Debu Panda, a principal product manager at AWS, is an industry leader in analytics, application platform, and database technologies and has more than 25 years of experience in the IT world.
Debu Panda, a principal product manager at AWS, is an industry leader in analytics, application platform, and database technologies and has more than 25 years of experience in the IT world.
 Nikos Koulouris is a Software Development Engineer at AWS. He received his PhD from University of California, San Diego and he has been working in the areas of databases and analytics.
Nikos Koulouris is a Software Development Engineer at AWS. He received his PhD from University of California, San Diego and he has been working in the areas of databases and analytics.
 Murali Narayanaswamy is a principal machine learning scientist in AWS. He received his PhD from Carnegie Mellon University and works at the intersection of ML, AI, optimization, learning and inference to combat uncertainty in real-world applications including personalization, forecasting, supply chains and large scale systems.
Murali Narayanaswamy is a principal machine learning scientist in AWS. He received his PhD from Carnegie Mellon University and works at the intersection of ML, AI, optimization, learning and inference to combat uncertainty in real-world applications including personalization, forecasting, supply chains and large scale systems.