Artificial Intelligence
Author: Praveen Chamarthi
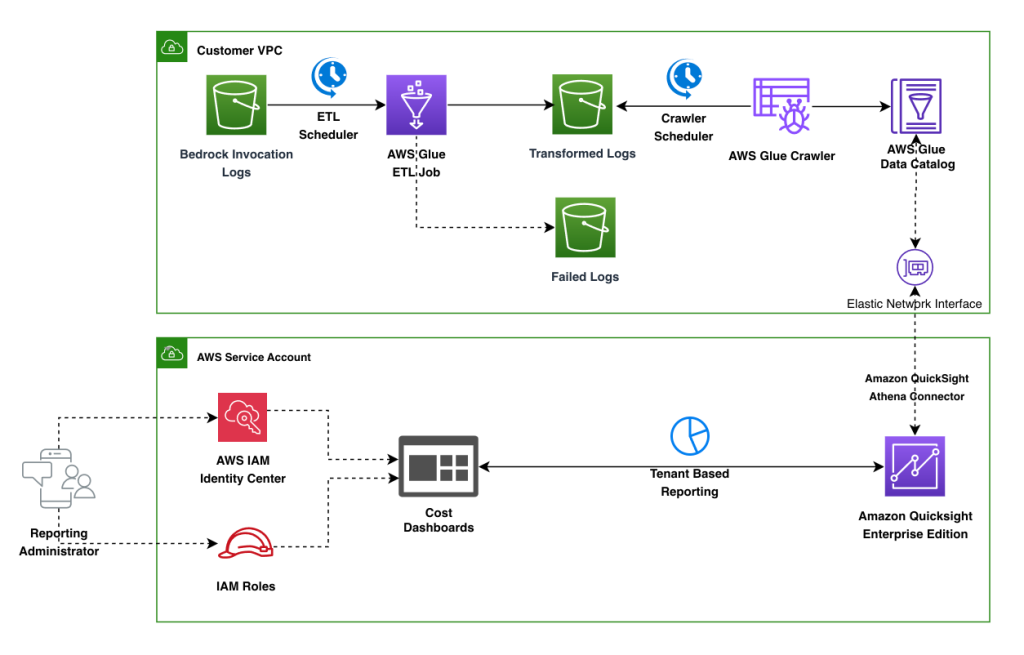
Cost tracking multi-tenant model inference on Amazon Bedrock
In this post, we demonstrate how to track and analyze multi-tenant model inference costs on Amazon Bedrock using the Converse API’s requestMetadata parameter. The solution includes an ETL pipeline using AWS Glue and Amazon QuickSight dashboards to visualize usage patterns, token consumption, and cost allocation across different tenants and departments.

Protect sensitive data in RAG applications with Amazon Bedrock
In this post, we explore two approaches for securing sensitive data in RAG applications using Amazon Bedrock. The first approach focused on identifying and redacting sensitive data before ingestion into an Amazon Bedrock knowledge base, and the second demonstrated a fine-grained RBAC pattern for managing access to sensitive information during retrieval. These solutions represent just two possible approaches among many for securing sensitive data in generative AI applications.

Improve the productivity of your customer support and project management teams using Amazon Q Business and Atlassian Jira
Effective customer support and project management are critical aspects of providing effective customer relationship management. Atlassian Jira, a platform for issue tracking and project management functions for software projects, has become an indispensable part of many organizations’ workflows to ensure success of the customer and the product. However, extracting valuable insights from the vast amount […]

Build and deploy ML inference applications from scratch using Amazon SageMaker
As machine learning (ML) goes mainstream and gains wider adoption, ML-powered inference applications are becoming increasingly common to solve a range of complex business problems. The solution to these complex business problems often requires using multiple ML models and steps. This post shows you how to build and host an ML application with custom containers […]

Deploy Amazon SageMaker Autopilot models to serverless inference endpoints
Amazon SageMaker Autopilot automatically builds, trains, and tunes the best machine learning (ML) models based on your data, while allowing you to maintain full control and visibility. Autopilot can also deploy trained models to real-time inference endpoints automatically. If you have workloads with spiky or unpredictable traffic patterns that can tolerate cold starts, then deploying […]