Artificial Intelligence
Build a corporate credit ratings classifier using graph machine learning in Amazon SageMaker JumpStart
Today, we’re releasing a new solution for financial graph machine learning (ML) in Amazon SageMaker JumpStart. JumpStart helps you quickly get started with ML and provides a set of solutions for the most common use cases that can be trained and deployed with just a few clicks.
The new JumpStart solution (Graph-Based Credit Scoring) demonstrates how to construct a corporate network from SEC filings (long-form text data), combine this with financial ratios (tabular data), and use graph neural networks (GNNs) to build credit rating prediction models. In this post, we explain how you can use this fully customizable solution for credit scoring, so you can accelerate your graph ML journey. Graph ML is becoming a fruitful area for financial ML because it enables the use of network data in conjunction with traditional tabular datasets. For more information, see Amazon at WSDM: The future of graph neural networks.
Solution overview
You can improve credit scoring by exploiting data on business linkages, for which you may construct a graph, denoted as CorpNet (short for corporate network) in this solution. You can then apply graph ML classification using GNNs on this graph and a tabular feature set for the nodes, to see if you can build a better ML model by further exploiting the information in network relationships. Therefore, this solution offers a template for business models that exploit network data, such as using supply chain relationship graphs, social network graphs, and more.
The solution develops several new artifacts by constructing a corporate network and generating synthetic financial data, and combines both forms of data to create models using graph ML.
The solution shows how to construct a network of connected companies using the MD&A section from SEC 10-K/Q filings. Companies with similar forward-looking statements are likely to be connected for credit events. These connections are represented in a graph. For graph node features, the solution uses the variables in the Altman Z-score model and the industry category of each firm. These are provided in a synthetic dataset made available for demonstration purposes. The graph data and tabular data are used to fit a rating classifier using GNNs. For illustrative purposes, we compare the performance of models with and without the graph information.
Use the Graph-Based Credit Scoring solution
To start using JumpStart, see Getting started with Amazon SageMaker. The JumpStart card for the Graph-Based Credit Scoring solution is available through Amazon SageMaker Studio.

- Choose the model card, then choose Launch to initiate the solution.

The solution generates a model for inference and an endpoint to use with a notebook.
- Wait until they’re ready and the status shows as
Complete. - Choose Open Notebook to open the first notebook, which is for training and endpoint deployment.

You can work through this notebook to learn how to use this solution and then modify it for other applications on your own data. The solution comes with synthetic data and uses a subset of it to exemplify the steps needed to train the model, deploy it to an endpoint, and then invoke the endpoint for inference. The notebook also contains code to deploy an endpoint of your own.
- To open the second notebook (used for inference), choose Use Endpoint in Notebook next to the endpoint artifact.
In this notebook, you can see how to prepare the data to invoke the example endpoint to perform inference on a batch of examples.
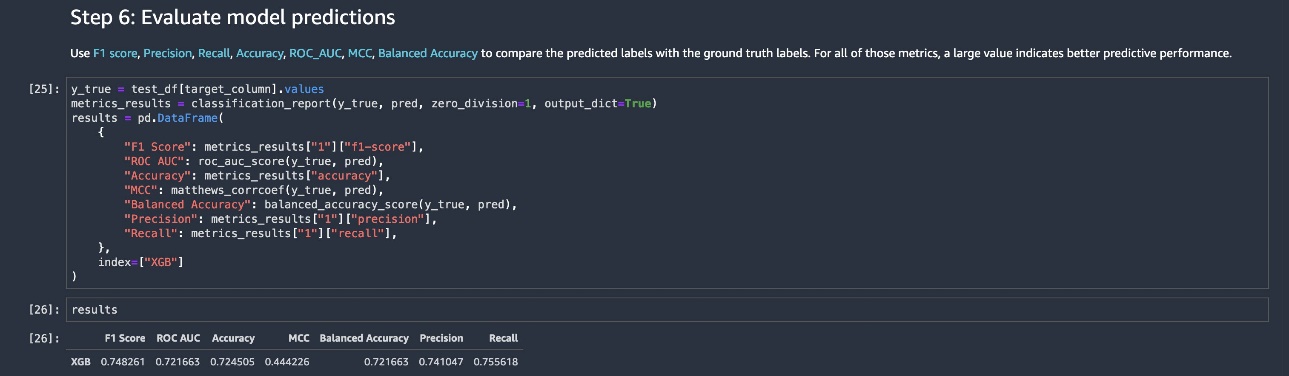
The endpoint returns predicted ratings, which are used to assess model performance, as shown in the following screenshot of the last code block of the inference notebook.
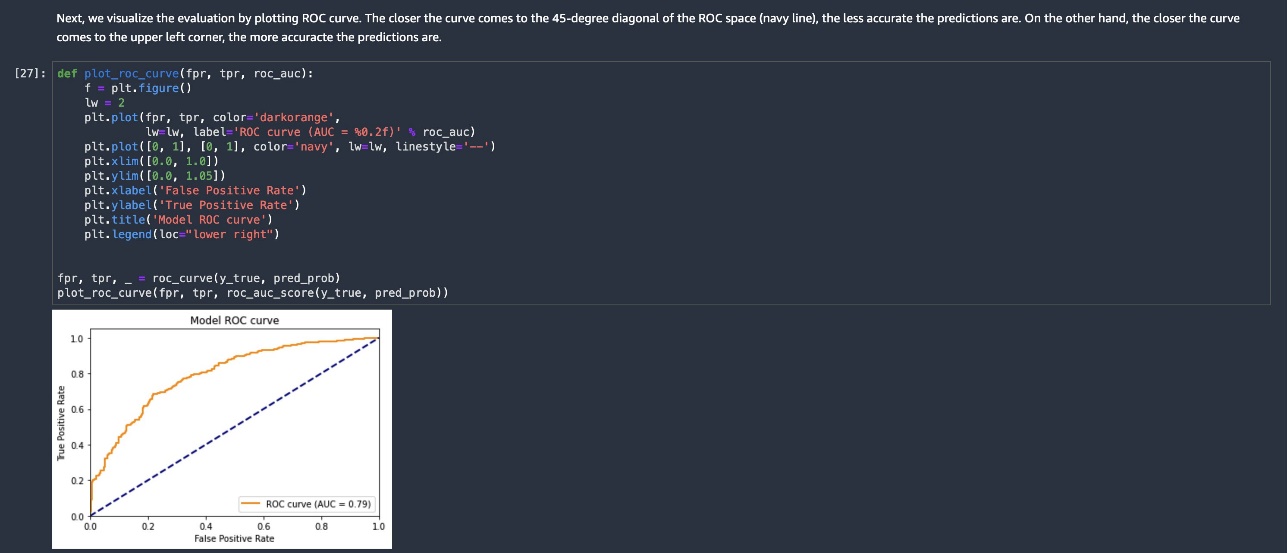
You can use this solution as a template for a graph-enhanced credit rating model. You’re not restricted to the feature set in this example—you can change both the graph data and tabular data for your own use case. The extent of code changes required is minimal. We recommend working through our template example to understand the structure of the solution, and then modify it as needed.
This solution is for demonstrative purposes only. It is not financial advice and should not be relied on as financial or investment advice. The associated notebooks, including the trained model, use synthetic data, and are not intended for production use. Although text from SEC filings is used, the financial data is synthetically and randomly generated and has no relation to any company’s true financials. Therefore, the synthetically generated ratings also don’t have any relation to any real company’s true rating.
Data used in the solution
The dataset has synthetic tabular data such as various accounting ratios (numerical) and industry codes (categorical). The dataset has ?=3286 rows. Rating labels are also added. These are the node features to be used with graph ML.
The dataset also contains a corporate graph, which is undirected and unweighted. This solution allows you to adjust the structure of the graph by varying the way in which links are included. Each company in the tabular dataset is represented by a node in the corporate graph. The function construct_network_data() helps construct the graph, which comprises lists of source nodes and destination nodes.
Rating labels are used for classification using GNNs, which can be multi-category for all ratings or binary, divided between investment grade (AAA, AA, A, BBB) and non-investment grade (BB, B, CCC, CC, C, D). D here stands for defaulted.
The complete code to read in the data and run the solution is provided in the solution notebook. The following screenshot shows the structure of the synthetic tabular data.

The graph information is passed in to the Deep Graph Library and combined with the tabular data to undertake graph ML. If you bring your own graph, simply supply it as a set of source nodes and destination nodes.
Model training
For comparison, we first train a model only on tabular data using AutoGluon, mimicking the traditional approach to credit rating of companies. We then add in the graph data and use GNNs for training. Full details are provided in the notebook, and a brief overview is offered in this post. The notebook also offers a quick overview of graph ML with selected references.
Training the GNN is undertaken as follows. We use an adaptation of the GraphSAGE model implemented in the Deep Graph Library.
- Read in graph data from Amazon Simple Storage Service (Amazon S3) and create the source and destination node lists for CorpNet.
- Read in the graph node feature sets (train and test). Normalize the data as required.
- Set tunable hyperparameters. Call the specialized graph ML container running PyTorch to fit the GNN without hyperparameter optimization (HPO).
- Repeat graph ML with HPO.
To make implementation straightforward and stable, we run model training in a container using the following code (the setup code prior to this training code is in the solution notebook):
The current training process is undertaken in a transductive setting, where the features of the test dataset (not including the target column) are used to construct the graph and therefore the test nodes are included in the training process. At the end of training, the predictions on the test dataset are generated and saved in output_location in the S3 bucket.
Even though the training is transductive, the labels of the test dataset aren’t used for training, and our exercise is aimed at predicting these labels using node embeddings for the test dataset nodes. An important feature of GraphSAGE is that inductive learning on new observations that aren’t part of the graph is also possible, though not exploited in this solution.
Hyperparameter optimization
This solution is further extended by conducting HPO on the GNN. This is done within SageMaker. See the following code:
We then set up the training objective, to maximize the F1 score in this case:
Establish the chosen environment and training resources on SageMaker:
Finally, run the training job with hyperparameter optimization:
Results
The inclusion of network data and hyperparameter optimization yields improved results. The performance metrics in the following table demonstrate the benefit of adding in CorpNet to standard tabular datasets used for credit scoring.
The results for AutoGluon don’t use the graph, only the tabular data. When we add in the graph data and use HPO, we get a material gain in performance.
| F1 Score | ROC AUC | Accuracy | MCC | Balanced Accuracy | Precision | Recall | |
| AutoGluon | 0.72 | 0.74323 | 0.68037 | 0.35233 | 0.67323 | 0.68528 | 0.75843 |
| GCN Without HPO | 0.64 | 0.84498 | 0.69406 | 0.45619 | 0.71154 | 0.88177 | 0.50281 |
| GCN With HPO | 0.81 | 0.87116 | 0.78082 | 0.563 | 0.77081 | 0.75119 | 0.89045 |
(Note: MCC is the Matthews Correlation Coefficient; https://en.wikipedia.org/wiki/Phi_coefficient.)
Clean up
After you’re done using this notebook, delete the model artifacts and other resources to avoid incurring further charges. You need to manually delete resources that you may have created while running the notebook, such as S3 buckets for model artifacts, training datasets, processing artifacts, and Amazon CloudWatch log groups.
Summary
In this post, we introduced a graph-based credit scoring solution in JumpStart to help you accelerate your graph ML journey. The notebook provides a pipeline that you can modify and exploit graphs with existing tabular models to obtain better performance.
To get started, you can find the Graph-Based Credit Scoring solution in JumpStart in SageMaker Studio.
About the Authors
 Dr. Sanjiv Das is an Amazon Scholar and the Terry Professor of Finance and Data Science at Santa Clara University. He holds post-graduate degrees in Finance (M.Phil and Ph.D. from New York University) and Computer Science (M.S. from UC Berkeley), and an MBA from the Indian Institute of Management, Ahmedabad. Prior to being an academic, he worked in the derivatives business in the Asia-Pacific region as a Vice President at Citibank. He works on multimodal machine learning in the area of financial applications.
Dr. Sanjiv Das is an Amazon Scholar and the Terry Professor of Finance and Data Science at Santa Clara University. He holds post-graduate degrees in Finance (M.Phil and Ph.D. from New York University) and Computer Science (M.S. from UC Berkeley), and an MBA from the Indian Institute of Management, Ahmedabad. Prior to being an academic, he worked in the derivatives business in the Asia-Pacific region as a Vice President at Citibank. He works on multimodal machine learning in the area of financial applications.
 Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the areas of natural language processing, deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the areas of natural language processing, deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
 Soji Adeshina is an Applied Scientist at AWS, where he develops graph neural network-based models for machine learning on graphs tasks with applications to fraud and abuse, knowledge graphs, recommender systems, and life sciences. In his spare time, he enjoys reading and cooking.
Soji Adeshina is an Applied Scientist at AWS, where he develops graph neural network-based models for machine learning on graphs tasks with applications to fraud and abuse, knowledge graphs, recommender systems, and life sciences. In his spare time, he enjoys reading and cooking.
 Patrick Yang is a Software Development Engineer at Amazon SageMaker. He focuses on building machine learning tools and products for customers.
Patrick Yang is a Software Development Engineer at Amazon SageMaker. He focuses on building machine learning tools and products for customers.