Artificial Intelligence
Category: Amazon SageMaker HyperPod

Scaling seismic foundation models on AWS: Distributed training with Amazon SageMaker HyperPod and expanding context windows
This post describes how TGS achieved near-linear scaling for distributed training and expanded context windows for their Vision Transformer-based SFM using Amazon SageMaker HyperPod. This joint solution cut training time from 6 months to just 5 days while enabling analysis of seismic volumes larger than previously possible.

Introducing Disaggregated Inference on AWS powered by llm-d
In this blog post, we introduce the concepts behind next-generation inference capabilities, including disaggregated serving, intelligent request scheduling, and expert parallelism. We discuss their benefits and walk through how you can implement them on Amazon SageMaker HyperPod EKS to achieve significant improvements in inference performance, resource utilization, and operational efficiency.

Accelerating AI model production at Hexagon with Amazon SageMaker HyperPod
In this blog post, we demonstrate how Hexagon collaborated with Amazon Web Services to scale their AI model production by pretraining state-of-the-art segmentation models, using the model training infrastructure of Amazon SageMaker HyperPod.

Scale LLM fine-tuning with Hugging Face and Amazon SageMaker AI
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.

Manage Amazon SageMaker HyperPod clusters using the HyperPod CLI and SDK
In this post, we demonstrate how to use the CLI and the SDK to create and manage SageMaker HyperPod clusters in your AWS account. We walk through a practical example and dive deeper into the user workflow and parameter choices.

Checkpointless training on Amazon SageMaker HyperPod: Production-scale training with faster fault recovery
In this post, we introduce checkpointless training on Amazon SageMaker HyperPod, a paradigm shift in model training that reduces the need for traditional checkpointing by enabling peer-to-peer state recovery. Results from production-scale validation show 80–93% reduction in recovery time (from 15–30 minutes or more to under 2 minutes) and enables up to 95% training goodput on cluster sizes with thousands of AI accelerators.
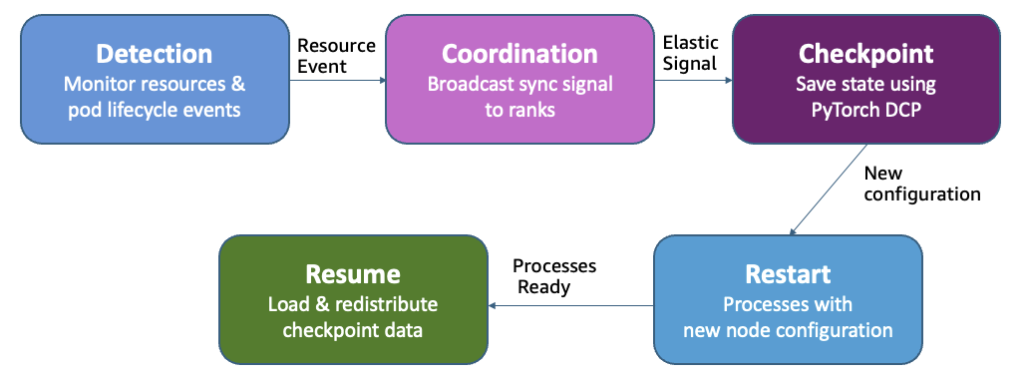
Adaptive infrastructure for foundation model training with elastic training on SageMaker HyperPod
Amazon SageMaker HyperPod now supports elastic training, enabling your machine learning (ML) workloads to automatically scale based on resource availability. In this post, we demonstrate how elastic training helps you maximize GPU utilization, reduce costs, and accelerate model development through dynamic resource adaptation, while maintain training quality and minimizing manual intervention.
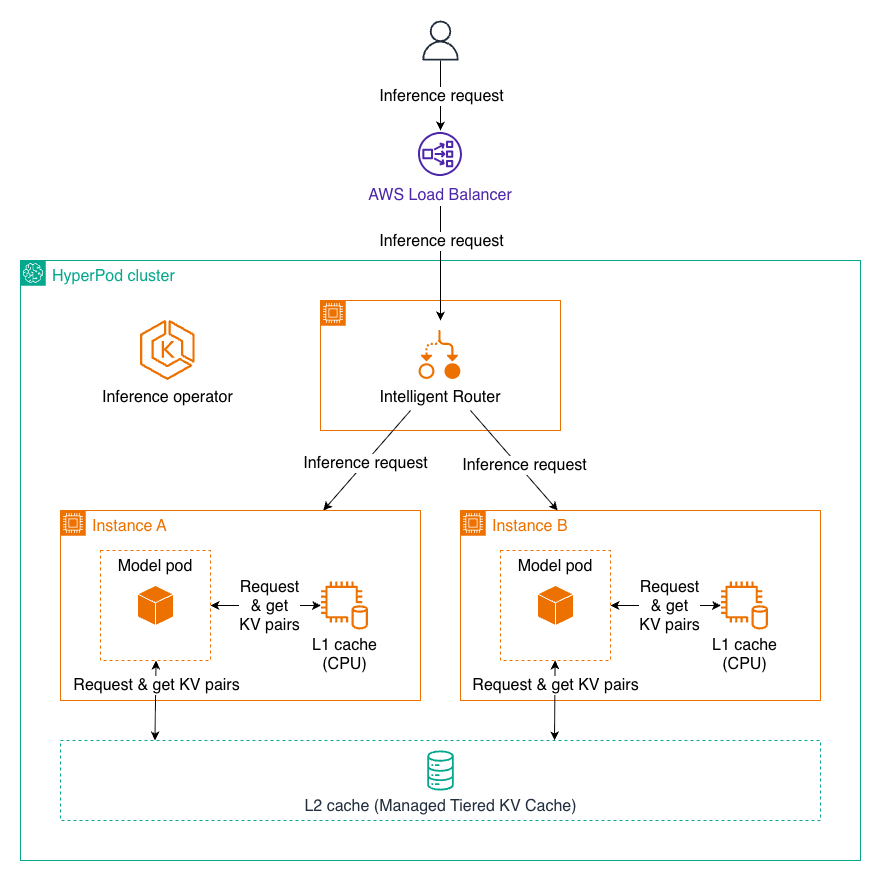
Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod
In this post, we introduce Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod, new capabilities that can reduce time to first token by up to 40% and lower compute costs by up to 25% for long context prompts and multi-turn conversations. These features automatically manage distributed KV caching infrastructure and intelligent request routing, making it easier to deploy production-scale LLM inference workloads with enterprise-grade performance while significantly reducing operational overhead.
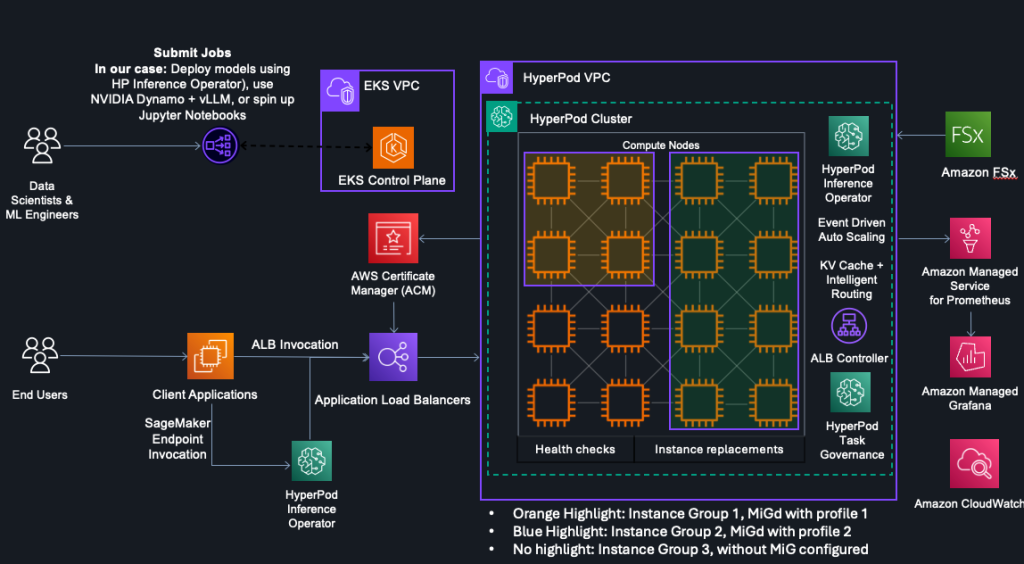
HyperPod now supports Multi-Instance GPU to maximize GPU utilization for generative AI tasks
In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks.

Power up your ML workflows with interactive IDEs on SageMaker HyperPod
Amazon SageMaker HyperPod clusters with Amazon Elastic Kubernetes Service (EKS) orchestration now support creating and managing interactive development environments such as JupyterLab and open source Visual Studio Code, streamlining the ML development lifecycle by providing managed environments for familiar tools to data scientists. This post shows how HyperPod administrators can configure Spaces for their clusters, and how data scientists can create and connect to these Spaces.