Artificial Intelligence
Category: Best Practices

Beyond the basics: A comprehensive foundation model selection framework for generative AI
As the model landscape expands, organizations face complex scenarios when selecting the right foundation model for their applications. In this blog post we present a systematic evaluation methodology for Amazon Bedrock users, combining theoretical frameworks with practical implementation strategies that empower data scientists and machine learning (ML) engineers to make optimal model selections.
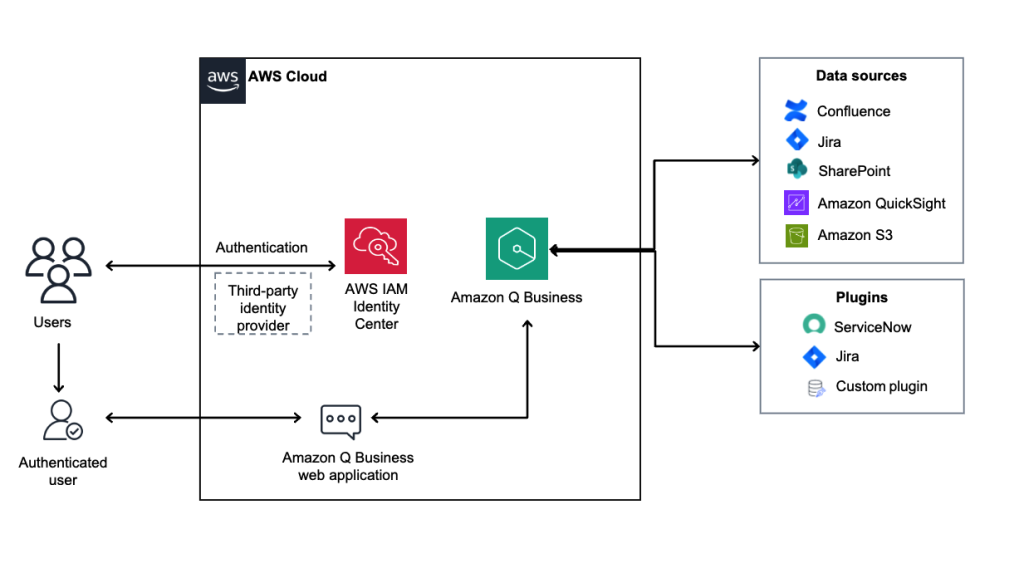
Accelerate enterprise AI implementations with Amazon Q Business
Amazon Q Business offers AWS customers a scalable and comprehensive solution for enhancing business processes across their organization. By carefully evaluating your use cases, following implementation best practices, and using the architectural guidance provided in this post, you can deploy Amazon Q Business to transform your enterprise productivity. The key to success lies in starting small, proving value quickly, and scaling systematically across your organization.
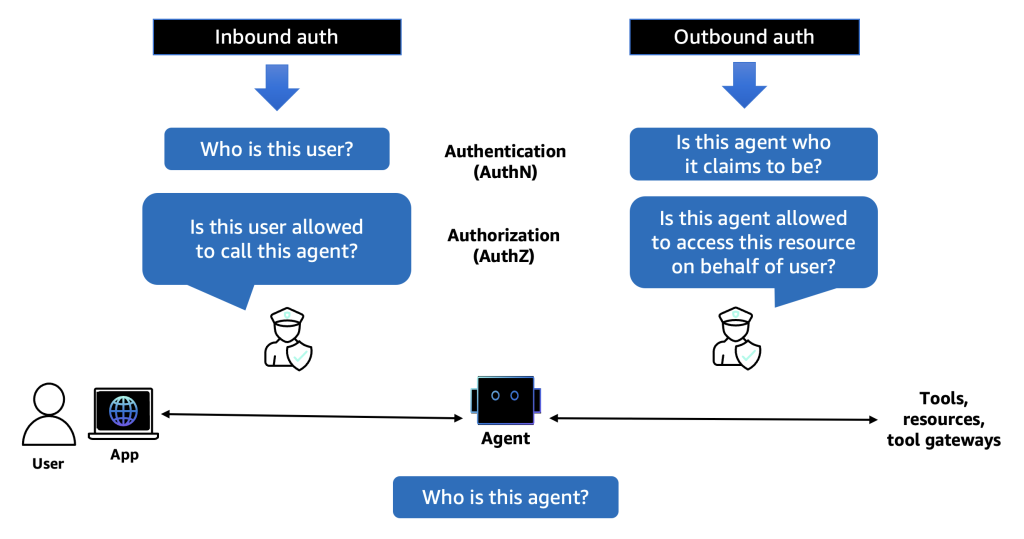
Introducing Amazon Bedrock AgentCore Identity: Securing agentic AI at scale
In this post, we explore Amazon Bedrock AgentCore Identity, a comprehensive identity and access management service purpose-built for AI agents that enables secure access to AWS resources and third-party tools. The service provides robust identity management features including agent identity directory, agent authorizer, resource credential provider, and resource token vault to help organizations deploy AI agents securely at scale.
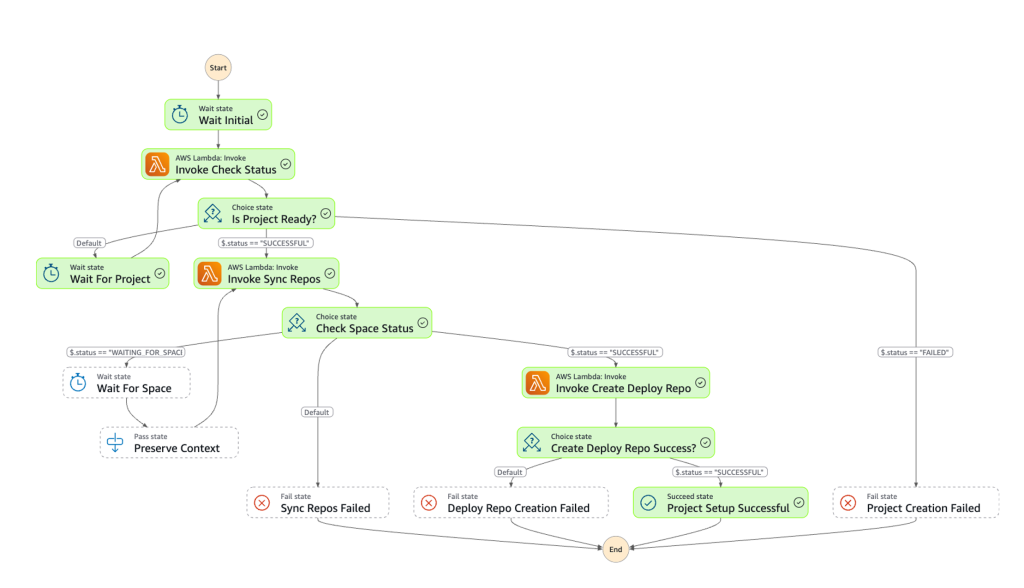
Automate ModelOps with SageMaker Unified Studio, Part 2: Technical implementation
In this post, we focus on implementing this architecture with step-by-step guidance and reference code. We provide a detailed technical walkthrough that addresses the needs of two critical personas in the AI development lifecycle: the administrator who establishes governance and infrastructure through automated templates, and the data scientist who uses SageMaker Unified Studio for model development without managing the underlying infrastructure.
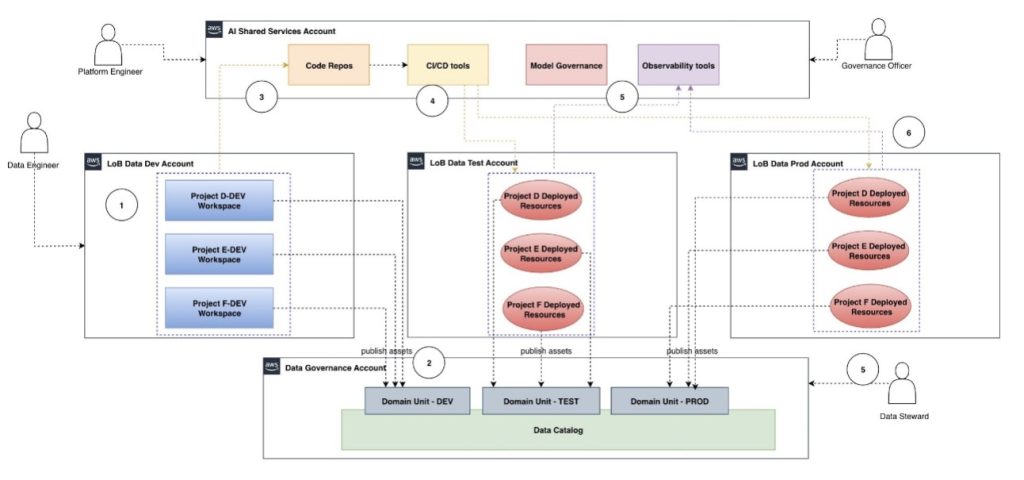
Automate ModelOps with Amazon SageMaker Unified Studio, Part 1: Solution architecture
This post presents architectural strategies and a scalable framework that helps organizations manage multi-tenant environments, automate consistently, and embed governance controls as they scale their AI initiatives with SageMaker Unified Studio.

Responsible AI for the payments industry – Part 1
This post explores the unique challenges facing the payments industry in scaling AI adoption, the regulatory considerations that shape implementation decisions, and practical approaches to applying responsible AI principles. In Part 2, we provide practical implementation strategies to operationalize responsible AI within your payment systems.

Responsible AI for the payments industry – Part 2
In Part 1 of our series, we explored the foundational concepts of responsible AI in the payments industry. In this post, we discuss the practical implementation of responsible AI frameworks.

Structured outputs with Amazon Nova: A guide for builders
We launched constrained decoding to provide reliability when using tools for structured outputs. Now, tools can be used with Amazon Nova foundation models (FMs) to extract data based on complex schemas, reducing tool use errors by over 95%. In this post, we explore how you can use Amazon Nova FMs for structured output use cases.

Build modern serverless solutions following best practices using Amazon Q Developer CLI and MCP
This post explores how the AWS Serverless MCP server accelerates development throughout the serverless lifecycle, from making architectural decisions with tools like get_iac_guidance and get_lambda_guidance, to streamlining development with get_serverless_templates, sam_init, to deployment with SAM integration, webapp_deployment_help, and configure_domain. We show how this conversational AI approach transforms the entire process, from architecture design through operations, dramatically accelerating AWS serverless projects while adhering to architectural principles.
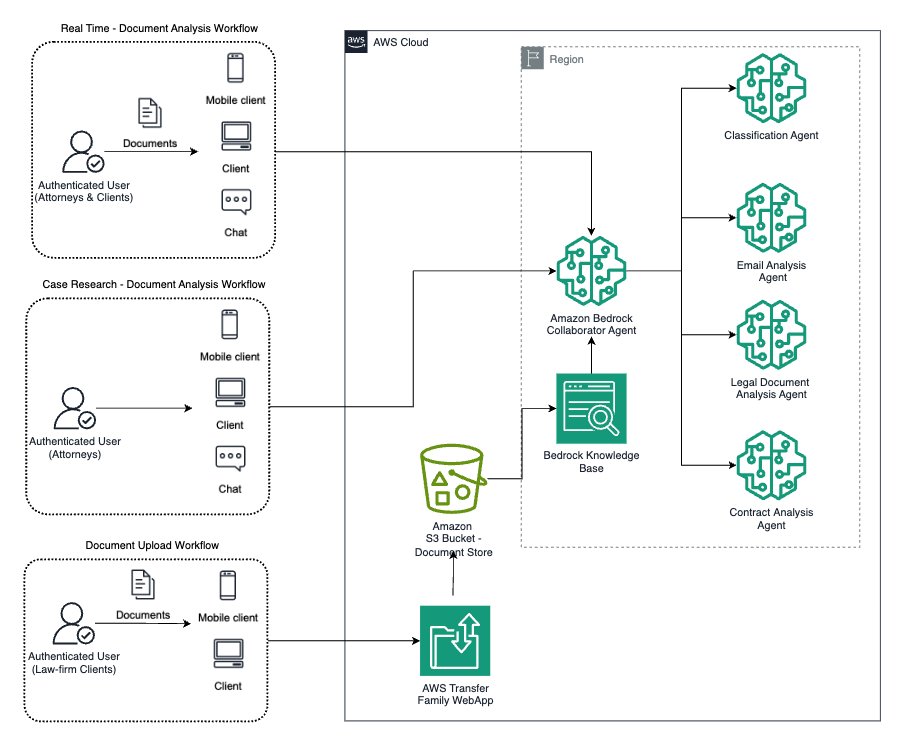
Build an intelligent eDiscovery solution using Amazon Bedrock Agents
In this post, we demonstrate how to build an intelligent eDiscovery solution using Amazon Bedrock Agents for real-time document analysis. We show how to deploy specialized agents for document classification, contract analysis, email review, and legal document processing, all working together through a multi-agent architecture. We walk through the implementation details, deployment steps, and best practices to create an extensible foundation that organizations can adapt to their specific eDiscovery requirements.