Artificial Intelligence
Category: Best Practices
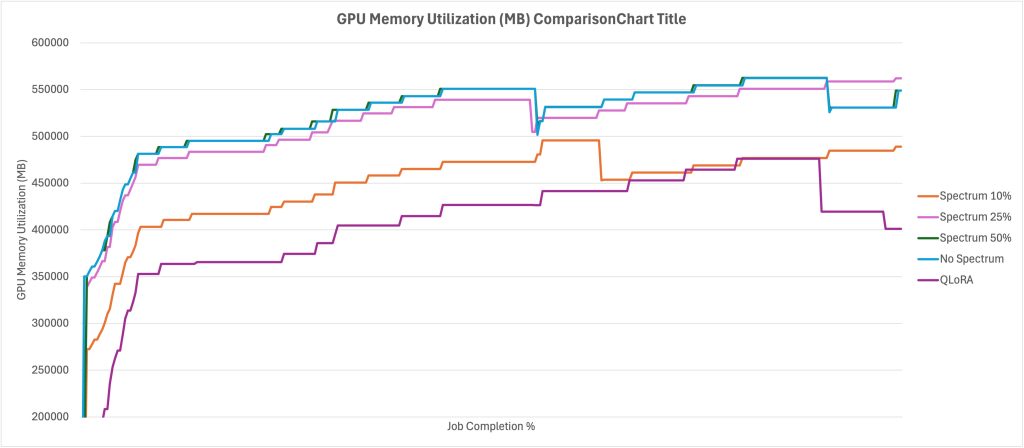
Using Spectrum fine-tuning to improve FM training efficiency on Amazon SageMaker AI
In this post you will learn how to use Spectrum to optimize resource use and shorten training times without sacrificing quality, as well as how to implement Spectrum fine-tuning with Amazon SageMaker AI training jobs. We will also discuss the tradeoff between QLoRA and Spectrum fine-tuning, showing that while QLoRA is more resource efficient, Spectrum results in higher performance overall.
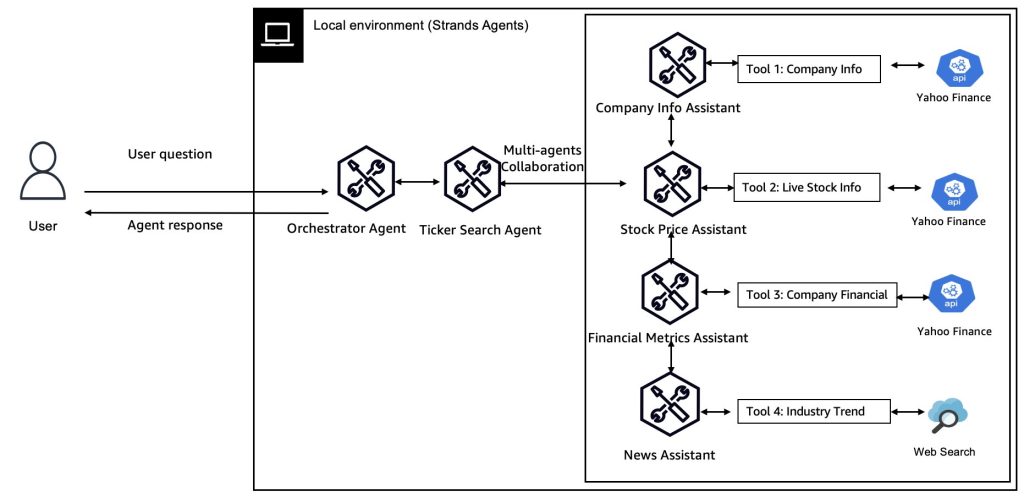
Multi-Agent collaboration patterns with Strands Agents and Amazon Nova
In this post, we explore four key collaboration patterns for multi-agent, multimodal AI systems – Agents as Tools, Swarms Agents, Agent Graphs, and Agent Workflows – and discuss when and how to apply each using the open-source AWS Strands Agents SDK with Amazon Nova models.
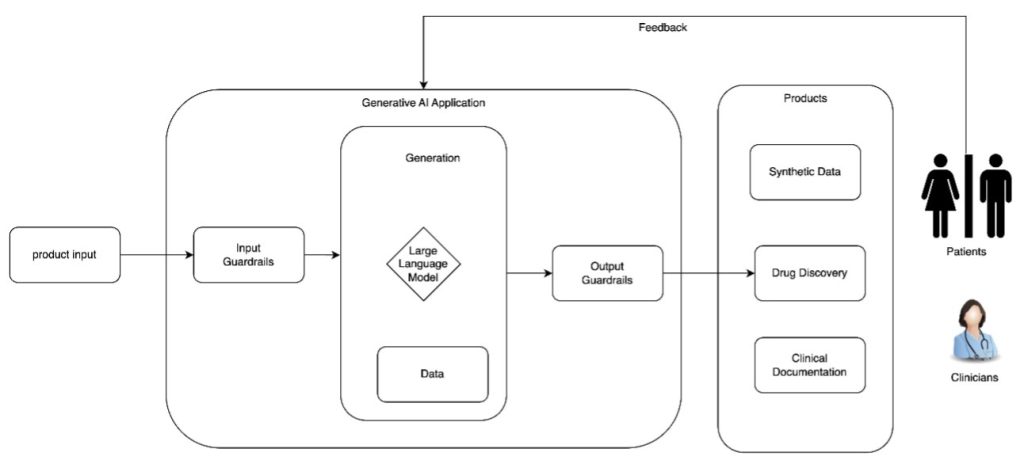
Responsible AI design in healthcare and life sciences
In this post, we explore the critical design considerations for building responsible AI systems in healthcare and life sciences, focusing on establishing governance mechanisms, transparency artifacts, and security measures that ensure safe and effective generative AI applications. The discussion covers essential policies for mitigating risks like confabulation and bias while promoting trust, accountability, and patient safety throughout the AI development lifecycle.

Beyond pilots: A proven framework for scaling AI to production
In this post, we explore the Five V’s Framework—a field-tested methodology that has helped 65% of AWS Generative AI Innovation Center customer projects successfully transition from concept to production, with some launching in just 45 days. The framework provides a structured approach through Value, Visualize, Validate, Verify, and Venture phases, shifting focus from “What can AI do?” to “What do we need AI to do?” while ensuring solutions deliver measurable business outcomes and sustainable operational excellence.

Incorporating responsible AI into generative AI project prioritization
In this post, we explore how companies can systematically incorporate responsible AI practices into their generative AI project prioritization methodology to better evaluate business value against costs while addressing novel risks like hallucination and regulatory compliance. The post demonstrates through a practical example how conducting upfront responsible AI risk assessments can significantly change project rankings by revealing substantial mitigation work that affects overall project complexity and timeline.
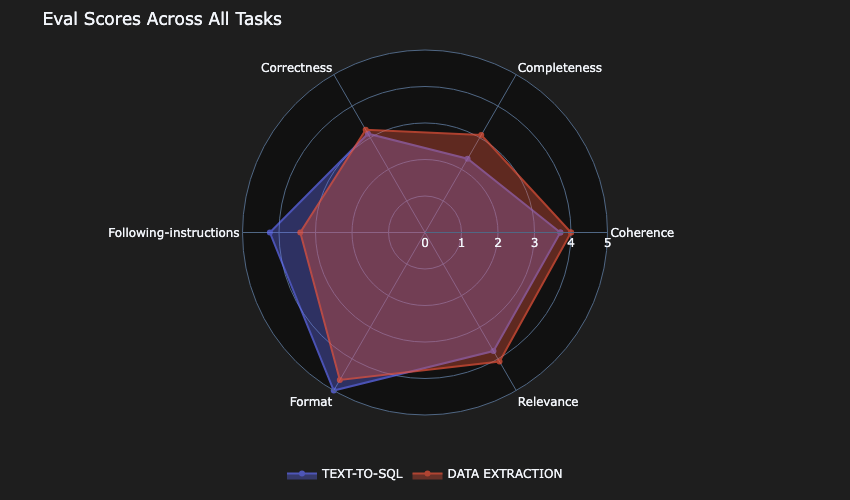
Beyond vibes: How to properly select the right LLM for the right task
In this post, we discuss an approach that can guide you to build comprehensive and empirically driven evaluations that can help you make better decisions when selecting the right model for your task.
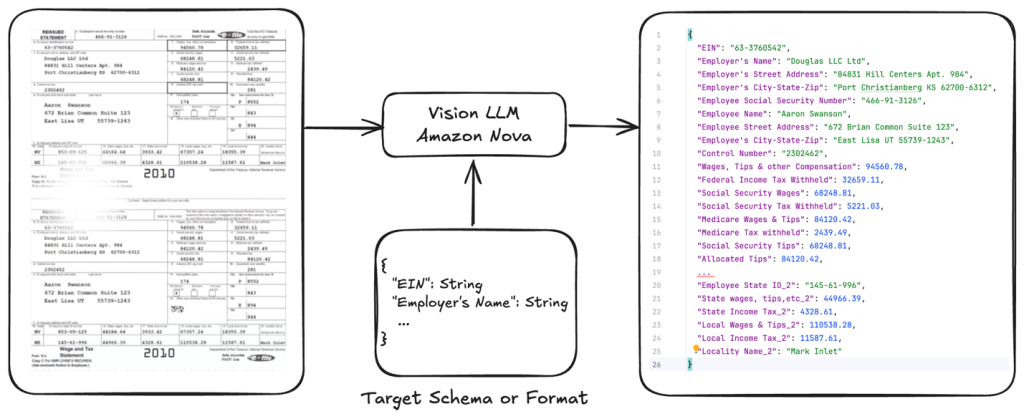
Optimizing document AI and structured outputs by fine-tuning Amazon Nova Models and on-demand inference
This post provides a comprehensive hands-on guide to fine-tune Amazon Nova Lite for document processing tasks, with a focus on tax form data extraction. Using our open-source GitHub repository code sample, we demonstrate the complete workflow from data preparation to model deployment.

Transforming enterprise operations: Four high-impact use cases with Amazon Nova
In this post, we share four high-impact, widely adopted use cases built with Nova in Amazon Bedrock, supported by real-world customers deployments, offerings available from AWS partners, and experiences. These examples are ideal for organizations researching their own AI adoption strategies and use cases across industries.
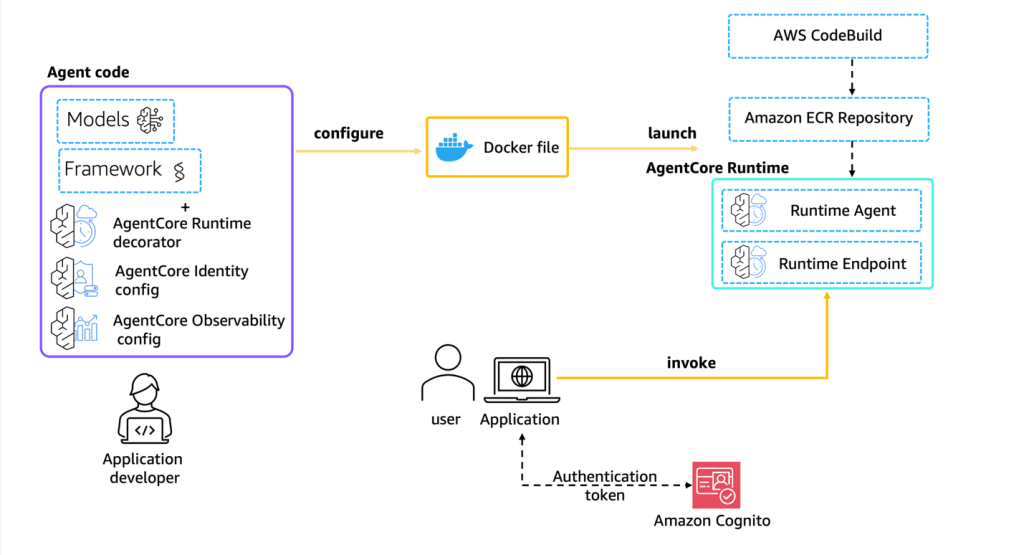
Move your AI agents from proof of concept to production with Amazon Bedrock AgentCore
This post explores how Amazon Bedrock AgentCore helps you transition your agentic applications from experimental proof of concept to production-ready systems. We follow the journey of a customer support agent that evolves from a simple local prototype to a comprehensive, enterprise-grade solution capable of handling multiple concurrent users while maintaining security and performance standards.

Migrate from Anthropic’s Claude Sonnet 3.x to Claude Sonnet 4.x on Amazon Bedrock
This post provides a systematic approach to migrating from Anthropic’s Claude 3.5 Sonnet to Claude Sonnet 4.5 on Amazon Bedrock. We examine the key model differences, highlight essential migration considerations, and deliver proven best practices to transform this necessary transition into a strategic advantage that drives measurable value for your organization.