Artificial Intelligence
Customizing text content moderation with Amazon Nova
Consider a growing social media platform that processes millions of user posts daily. Their content moderation team faces a familiar challenge: their rule-based system flags a cooking video discussing “knife techniques” as violent content, frustrating users, while simultaneously missing a veiled threat disguised as a restaurant review. When they try a general-purpose AI moderation service, it struggles with their community’s gaming terminology, flagging discussions about “eliminating opponents” in strategy games while missing actual harassment that uses coded language specific to their platform. The moderation team finds themselves caught between user complaints about over-moderation and advertiser concerns about harmful content slipping through—a problem that scales exponentially as their user base grows.
This scenario illustrates the broader challenges that content moderation at scale presents for customers across industries. Traditional rule-based approaches and keyword filters often struggle to catch nuanced policy violations, emerging harmful content patterns, or contextual violations that require deeper semantic understanding. Meanwhile, the volume of user-generated content continues to grow, making manual moderation increasingly impractical and costly. Customers need adaptable solutions that can scale with their content needs while maintaining accuracy and reflecting their specific moderation policies.
While general-purpose AI content moderation services offer broad capabilities, they typically implement standardized policies that might not align with a customer’s unique requirements. These approaches often struggle with domain-specific terminology, complex policy edge cases, or culturally-specific content evaluation. Additionally, different customers might have varying taxonomies for content annotation and different thresholds or boundaries for the same policy categories. As a result, many customers find themselves managing trade-offs between detection capabilities and false positives.
In this post, we introduce an approach to content moderation through Amazon Nova customization on Amazon SageMaker AI. With this solution, you can fine-tune Amazon Nova for content moderation tasks tailored to your requirements. By using domain-specific training data and organization-specific moderation guidelines, this customized approach can deliver improved accuracy and policy alignment compared to off-the-shelf solutions. Our evaluation across three benchmarks shows that customized Nova models achieve an average improvement of 7.3% in F1 scores compared to the baseline Nova Lite, with individual improvements ranging from 4.2% to 9.2% across different content moderation tasks. The customized Nova model can detect policy violations, understand contextual nuances, and adapt to content patterns based on your own dataset.
Key advantages
With Nova customization, you can build text content moderators that deliver compelling advantages over alternative approaches including training from scratch and using a general foundation model. By using pre-trained Nova models as a foundation, you can achieve superior results while reducing complexity, cost, and time-to-deployment.
When compared to building models entirely from the ground up, Nova customization provides several key benefits for your organization:
- Uses pre-existing knowledge: Nova comes with prior knowledge in text content moderation, having been trained on similar datasets, providing a foundation for customization that achieves competitive performance with just 10,000 instances for SFT.
- Simplified workflow: Instead of building training infrastructure from scratch, you can upload formatted data and submit a SageMaker training job, with training code and workflows provided, completing training in approximately one hour at a cost of $55 (based on US East Ohio Amazon EC2 P5 instance pricing).
- Reduced time and cost: Reduces the need for extensive computational resources and months of training time required for building models from the ground up.
While general-purpose foundation models offer broad capabilities, Nova customization delivers more targeted benefits for your content moderation use cases:
- Policy-specific customization: Unlike foundation models trained with broad datasets, Nova customization fine-tunes to your organization’s specific moderation guidelines and edge cases, achieving 4.2% to 9.2% improvements in F1 scores across different content moderation tasks.
- Consistent performance: Reduces unpredictability from third-party API updates and policy changes that can alter your content moderation behavior.
- Cost efficiency: At $0.06 per 1 million input tokens and $0.24 per 1 million output tokens, Nova Lite provides significant cost advantages compared to other commercial foundation models that spend about 10–100 times more cost, delivering substantial cost savings.
Beyond specific comparisons, Nova customization offers inherent benefits that apply regardless of your current approach:
- Flexible policy boundaries: Custom thresholds and policy boundaries can be controlled through prompts and taught to the model during fine-tuning.
- Accommodates diverse taxonomies: The solution adapts to different annotation taxonomies and organizational content moderation frameworks.
- Flexible data requirements: You can use your existing training datasets with proprietary data or use public training splits from established content moderation benchmarks if you don’t have your own datasets.
Demonstrating content moderation performance with Nova customization
To evaluate the effectiveness of Nova customization for content moderation, we developed and evaluated three content moderation models using Amazon Nova Lite as our foundation. Our approach used both proprietary internal content moderation datasets and established public benchmarks, training low-rank adaptation (LoRA) models with 10,000 fine-tuning instances—augmenting Nova Lite’s extensive base knowledge with specialized content moderation expertise.
Training approach and model variants
We created three model variants from Nova Lite, each optimized for different content moderation scenarios that you might encounter in your own implementation:
- NovaTextCM: Trained on our internal content moderation dataset, optimized for organization-specific policy enforcement
- NovaAegis: Fine-tuned using Aegis-AI-Content-Safety-2.0 training split, specialized for adversarial prompt detection
- NovaWildguard: Customized with WildGuardMix training split, designed for content moderation across real and synthetic contents
This multi-variant approach demonstrates the flexibility of Nova customization in adapting to different content moderation taxonomies and policy frameworks that you can apply to your specific use cases.
Comprehensive benchmark evaluation
We evaluated our customized models against three established content moderation benchmarks, each representing different aspects of the content moderation challenges that you might encounter in your own deployments. In our evaluation, we computed F1 scores for binary classification, determining whether each instance violates the given policy or not. The F1 score provides a balanced measure of precision and recall, which is useful for content moderation where both false positives (incorrectly flagging safe content) and false negatives (missing harmful content) carry costs.
- Aegis-AI-Content-Safety-2.0 (2024): A dataset with 2,777 test samples (1,324 safe, 1,453 unsafe) for binary policy violation classification. This dataset combines synthetic LLM-generated and real prompts from red teaming datasets, featuring adversarial prompts designed to test model robustness against bypass attempts. Available at Aegis-AI-Content-Safety-Dataset-2.0.
- WildGuardMix (2024): An evaluation set with 3,408 test samples (2,370 safe, 1,038 unsafe) for binary policy violation classification. The dataset consists mostly of real prompts with some LLM-generated responses, curated from multiple safety datasets and human-labeled for evaluation coverage. Available at wildguardmix.
- Jigsaw Toxic Comment (2018): A benchmark with 63,978 test samples (57,888 safe, 6,090 unsafe) for binary toxic content classification. This dataset contains real Wikipedia talk page comments and serves as an established benchmark in the content moderation community, providing insights into model performance on authentic user-generated content. Available at jigsaw-toxic-comment.
Performance achievements
Our results show that Nova customization provides meaningful performance improvements across all benchmarks that you can expect when implementing this solution. The customized models achieved performance levels comparable to large commercial language models (referred to here as LLM-A and LLM-B) while using only a fraction of the training data and computational resources.
The performance data shows significant F1 score improvements across all model variants. NovaLite baseline achieved F1 scores of 0.7822 on Aegis, 0.54103 on Jigsaw, and 0.78901 on Wildguard. NovaTextCM improved to 0.8305 (+6.2%) on Aegis, 0.59098 (+9.2%) on Jigsaw, and 0.83871 (+6.3%) on Wildguard. NovaAegis achieved the highest Aegis performance at 0.85262 (+9.0%), with scores of 0.55129 on Jigsaw, and 0.81701 on Wildguard. NovaWildguard scored 0.848 on Aegis, 0.56439 on Jigsaw, and 0.82234 (+4.2%) on Wildguard.
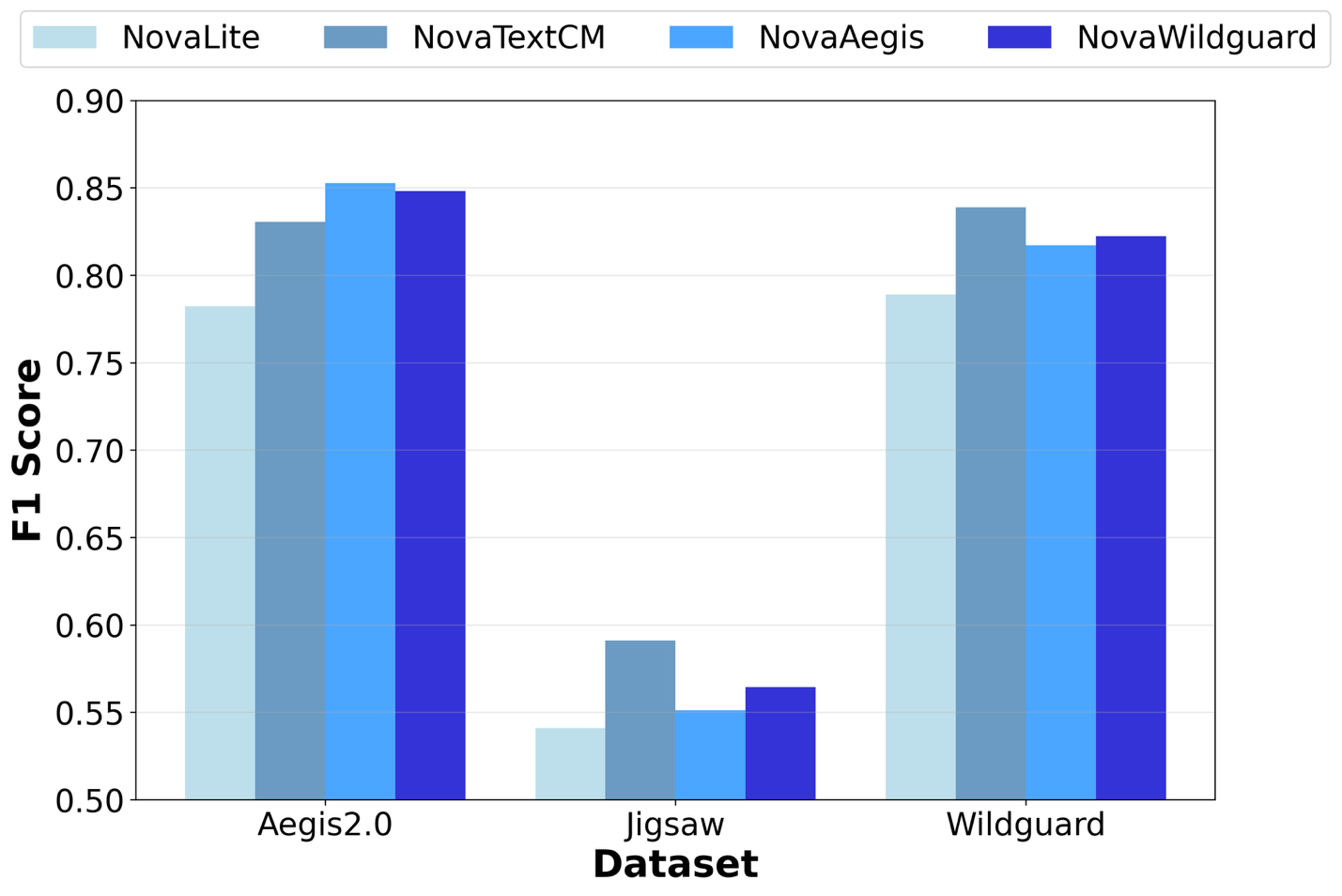
As shown in the preceding figure, the performance gains were observed across all three variants, with each model showing improvements over the baseline Nova Lite across multiple evaluation criteria:
- NovaAegis achieved the highest performance on the Aegis benchmark (0.85262), representing a 9.0% improvement over Nova Lite (0.7822)
- NovaTextCM showed consistent improvements across all benchmarks: Aegis (0.8305, +6.2%), Jigsaw (0.59098, +9.2%), and WildGuard (0.83871, +6.3%)
- NovaWildguard performed well on JigSaw (0.56439, +2.3%) and WildGuard (0.82234, +4.2%)
- All three customized models showed gains across benchmarks compared to the baseline Nova Lite
These performance improvements suggest that Nova customization can facilitate meaningful gains in content moderation tasks through targeted fine-tuning. The consistent improvements across different benchmarks indicate that customized Nova models have the potential to exceed the performance of commercial models in specialized applications.
Cost-effective large-scale deployment
Beyond performance improvements, Nova Lite offers significant cost advantages for large-scale content moderation deployments that you can take advantage of for your organization. With low-cost pricing for both input and output tokens, Nova Lite provides substantial cost advantages compared to commercial foundation models, delivering cost savings while maintaining competitive performance.
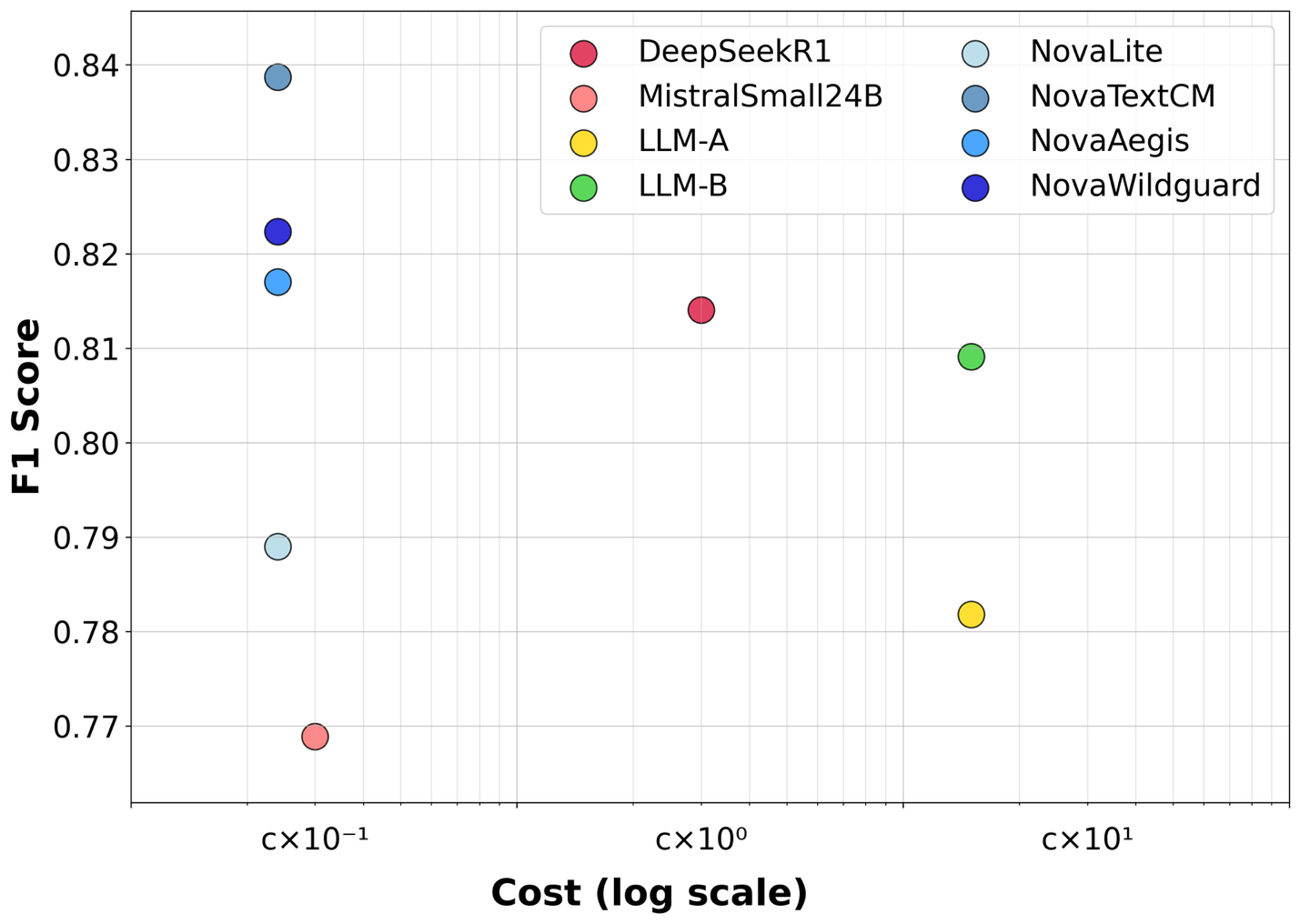
The cost-performance analysis on the WildGuard benchmark reveals compelling advantages for Nova customization that you can realize in your deployments. Your Nova variants achieve superior F1 scores compared to commercial foundation models while operating in the low-cost category. For example, NovaTextCM achieves an F1 score of 0.83871 on WildGuard while operating at extremely low cost, outperforming LLM-B’s F1 score of 0.80911 which operates at high-cost pricing—delivering better performance at significantly lower cost.
This cost efficiency becomes particularly compelling at scale for your organization. When you’re moderating large volumes of content daily, the pricing advantage of Nova variants in the low-cost category can translate to substantial operational savings while delivering superior performance. The combination of better accuracy and dramatically lower costs makes Nova customization an economically attractive solution for your enterprise content moderation needs.
Key training insights
We observed several important findings for Nova customization that can guide your implementation approach as follows.
- More data isn’t necessarily better: We found that 10,000 training instances represents a suitable amount for LoRA adaptation. When we increased the training data from 10,000 to 28,000 instances, we observed evidence of overfitting. This finding suggests that when using LoRA for fine-tuning, additional training instances can hurt performance, indicating that the pre-existing content moderation knowledge built in to Nova allows for learning with relatively small, well-curated datasets.
- Format consistency is important: Performance degraded when training and evaluation data formats were inconsistent. This highlights the importance of maintaining consistent data formatting throughout the customization pipeline.
- Task-specific adaptation: Each model variant performed best on benchmarks most similar to their training data, confirming that targeted customization can deliver improved results compared to general-purpose approaches.
How to train a model with Nova customization
This section provides a walkthrough for training your own customized Nova model for content moderation. We’ll cover the data preparation, configuration setup, and training execution using SageMaker AI.
Prerequisites and setup
Before beginning the training process, ensure you have followed the comprehensive instructions in Fine-tuning Amazon Nova models using SageMaker training jobs. The following examples demonstrate the specific configurations we used for our text content moderation models.
Training data format
Your training data must be formatted as a JSONL file and uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. Each line should contain a complete conversation following the Amazon Bedrock conversation schema. Here’s an example from our training dataset:
This format helps ensure that the model learns both the input structure (content moderation instructions and text to evaluate) and the expected output format (structured policy violation responses).
Training configuration
The training recipe defines all the hyperparameters and settings for your Nova customization. Save the following configuration as a YAML file (for example, text_cm.yaml):
This configuration uses LoRA for efficient fine-tuning, which significantly reduces training time and computational requirements while maintaining high performance.
SageMaker AI training job setup
Use the following notebook code to submit your training job to SageMaker AI. This implementation closely follows the sample notebook provided in the official guidelines, with specific adaptations for content moderation:
Important configuration notes:
- Note that we used
region_name='us-east-1' - For the
role_arnvariable, refer to the AWS Identity and Access Management (IAM) roles documentation for proper setup - The job name should not contain underscores or special symbols
Training performance
With our configuration using LoRA fine-tuning, training 10,000 instances on Nova Lite takes approximately one hour using the preceding setup. This efficient training time demonstrates the power of parameter-efficient fine-tuning combined with Nova’s pre-existing knowledge base.The relatively short training duration makes it practical to iterate on your content moderation policies and retrain models as needed, enabling rapid adaptation to evolving content challenges.
How to infer with a customized Nova model
After your Nova model has been successfully trained for content moderation, this section guides you through the evaluation and inference process. We’ll demonstrate how to benchmark your customized model against established datasets and deploy it for production use.
Prerequisites and setup
Before proceeding with model evaluation, ensure you have followed the comprehensive instructions in Evaluating your SageMaker AI-trained model. The following examples show the specific configurations we used for benchmarking our content moderation models against public datasets.
Test data format
Your evaluation data should be formatted as a JSONL file and uploaded to an S3 bucket. Each line contains a query-response pair that represents the input prompt and expected output for evaluation. Here’s an example from our test dataset:
This format allows the evaluation framework to compare your model’s generated responses against the expected ground truth labels, enabling accurate performance measurement across different content moderation benchmarks. Note that the response field was not used in the inference but included here to deliver the label in the inference output.
Evaluation configuration
The evaluation recipe defines the inference parameters and evaluation settings for your customized Nova model. Save the following configuration as a YAML file (for example, recipe.yaml):
Key configuration notes:
- The
temperature: 0setting ensures deterministic outputs, which is crucial for benchmarking
SageMaker evaluation job setup
Use the following notebook code to submit your evaluation job to SageMaker. You can use this setup to benchmark your customized model against the same datasets used in our performance evaluation:
Important setup notes:
- Download the evaluation recipe from the SageMaker HyperPod recipes repository
- Instance type can be adjusted based on your computational requirements and budget constraints
Clean up
To avoid incurring additional costs after following along with this post, you should clean up the AWS resources that were created during the training and deployment process. Here’s how you can systematically remove these resources:
Stop and delete training jobs
After your training job finishes, you can clean up your training job using the following AWS Command Line Interface (AWS CLI) command.
aws sagemaker list-training-jobsaws sagemaker stop-training-job --training-job-name <name> # only if still running
Delete endpoints, endpoint configs, models
These are the big cost drivers if left running. You should delete them in this specific order:
aws sagemaker delete-endpoint --endpoint-name <endpoint-name>
aws sagemaker delete-endpoint-config --endpoint-config-name <endpoint-config-name>
aws sagemaker delete-model --model-name <model-name>
Delete in that order:
- endpoint
- config
- model.
Clean up storage and artifacts
Training output and checkpoints are stored in Amazon S3. Delete them if not needed:
aws s3 rm s3://your-bucket-name/path/ --recursive
Additional storage considerations for your cleanup:
- FSx for Lustre (if you attached it for training or HyperPod): delete the file system in the FSx console
- EBS volumes (if you spun up notebooks or clusters with attached volumes): check to confirm that they aren’t lingering
Remove supporting resources
If you built custom Docker images for training or inference, delete them:
aws ecr delete-repository --repository-name <name> --force
Other supporting resources to consider:
- CloudWatch logs: These don’t usually cost much, but you can clear them if desired
- IAM roles: If you created temporary roles for jobs, detach or delete policies if unused
If you used HyperPod
For HyperPod deployments, you should also:
- Delete the HyperPod cluster (to the SageMaker console and choose HyperPod)
- Remove associated VPC endpoints, security groups, and subnets if dedicated
- Delete training job resources tied to HyperPod (same as the previous: endpoints, configs, models, FSx, and so on)
Evaluation performance and results
With this evaluation setup, processing 100,000 test instances using the trained Nova Lite model takes approximately one hour using a single p5.48xlarge instance. This efficient inference time makes it practical to regularly evaluate your model’s performance as you iterate on training data or adjust moderation policies.
Next steps: Deploying your customized Nova model
Ready to deploy your customized Nova model for production content moderation? Here’s how to deploy your model using Amazon Bedrock for on-demand inference:
Custom model deployment workflow
After you’ve trained or fine-tuned your Nova model through SageMaker using PEFT and LoRA techniques as demonstrated in this post, you can deploy it in Amazon Bedrock for inference. The deployment process follows this workflow:
- Create your customized model: Complete the Nova customization training process using SageMaker with your content moderation dataset
- Deploy using Bedrock: Set up a custom model deployment in Amazon Bedrock
- Use for inference: Use the deployment Amazon Resource Name (ARN) as the model ID for inference through the console, APIs, or SDKs
On-demand inference requirements
For on-demand (OD) inference deployment, ensure your setup meets these requirements:
- Training method: If you used SageMaker customization, on-demand inference is only supported for Parameter-Efficient Fine-Tuned (PEFT) models, including Direct Preference Optimization, when hosted in Amazon Bedrock.
- Deployment platform: Your customized model must be hosted in Amazon Bedrock to use on-demand inference capabilities.
Implementation considerations
When deploying your customized Nova model for content moderation, consider these factors:
- Scaling strategy: Use the managed infrastructure of Amazon Bedrock to automatically scale your content moderation capacity based on demand.
- Cost optimization: Take advantage of on-demand pricing to pay only for the inference requests you make, optimizing costs for variable content moderation workloads.
- Integration approach: Use the deployment ARN to integrate your customized model into existing content moderation workflows and applications.
Conclusion
The fast inference speed of Nova Lite—processing 100,000 instances per hour using a single P5 instance—provides significant advantages for large-scale content moderation deployments. With this throughput, you can moderate high volumes of user-generated content in real-time, making Nova customization particularly well-suited for platforms with millions of daily posts, comments, or messages that require immediate policy enforcement.
With the deployment approach and next steps described in this post, you can seamlessly integrate your customized Nova model into production content moderation systems, benefiting from both the performance improvements demonstrated in our evaluation and the managed infrastructure of Amazon Bedrock for reliable, scalable inference.
About the authors
 Yooju Shin is an Applied Scientist on Amazon’s AGI Foundations RAI team. He specializes in auto-prompting for RAI training dataset and supervised fine-tuning (SFT) of multimodal models. He completed his Ph.D. from KAIST in 2023.
Yooju Shin is an Applied Scientist on Amazon’s AGI Foundations RAI team. He specializes in auto-prompting for RAI training dataset and supervised fine-tuning (SFT) of multimodal models. He completed his Ph.D. from KAIST in 2023.
 Chentao Ye is a Senior Applied Scientist in the Amazon AGI Foundations RAI team, where he leads key initiatives in post-training recipes and multimodal large language models. His work focuses particularly on RAI alignment. He brings deep expertise in Generative AI, Multimodal AI, and Responsible AI.
Chentao Ye is a Senior Applied Scientist in the Amazon AGI Foundations RAI team, where he leads key initiatives in post-training recipes and multimodal large language models. His work focuses particularly on RAI alignment. He brings deep expertise in Generative AI, Multimodal AI, and Responsible AI.
 Fan Yang is a Senior Applied Scientist on the Amazon AGI Foundations RAI team, where he develops multimodal observers for responsible AI systems. He obtained a PhD in Computer Science from the University of Houston in 2020 with research focused on false information detection. Since joining Amazon, he has specialized in building and advancing multimodal models.
Fan Yang is a Senior Applied Scientist on the Amazon AGI Foundations RAI team, where he develops multimodal observers for responsible AI systems. He obtained a PhD in Computer Science from the University of Houston in 2020 with research focused on false information detection. Since joining Amazon, he has specialized in building and advancing multimodal models.
 Weitong Ruan is an Applied Science Manger on the Amazon AGI Foundations RAI team, where he leads the development of RAI systems for Nova and improving Nova’s RAI performance during SFT. Before joining Amazon, he completed his Ph.D. in Electrical Engineering with specialization in Machine Learning from the Tufts University in Aug 2018.
Weitong Ruan is an Applied Science Manger on the Amazon AGI Foundations RAI team, where he leads the development of RAI systems for Nova and improving Nova’s RAI performance during SFT. Before joining Amazon, he completed his Ph.D. in Electrical Engineering with specialization in Machine Learning from the Tufts University in Aug 2018.
 Rahul Gupta is a senior science manager at the Amazon Artificial General Intelligence team heading initiatives on Responsible AI. Since joining Amazon, he has focused on designing NLU models for scalability and speed. Some of his more recent research focuses on Responsible AI with emphasis on privacy preserving techniques, fairness and federated learning. He received his PhD from the University of Southern California in 2016 on interpreting non-verbal communications in human interaction. He has published several papers in avenues such as EMNLP, ACL, NAACL, ACM Facct, IEEE-Transactions of affective computing, IEEE-Spoken language Understanding workshop, ICASSP, Interspeech and Elselvier computer speech and language journal. He is also co-inventor on over twenty five patented/patent-pending technologies at Amazon.
Rahul Gupta is a senior science manager at the Amazon Artificial General Intelligence team heading initiatives on Responsible AI. Since joining Amazon, he has focused on designing NLU models for scalability and speed. Some of his more recent research focuses on Responsible AI with emphasis on privacy preserving techniques, fairness and federated learning. He received his PhD from the University of Southern California in 2016 on interpreting non-verbal communications in human interaction. He has published several papers in avenues such as EMNLP, ACL, NAACL, ACM Facct, IEEE-Transactions of affective computing, IEEE-Spoken language Understanding workshop, ICASSP, Interspeech and Elselvier computer speech and language journal. He is also co-inventor on over twenty five patented/patent-pending technologies at Amazon.