Artificial Intelligence
Getting Started with Amazon Comprehend custom entities
Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find insights and relationships in text. We released an update to Amazon Comprehend enabling support for private, custom entity types. Customers can now train state-of-the-art entity recognition models to extract their specific terms, completely automatically. No machine learning experience required. For example, financial companies can analyze market reports for terms and language related to bankruptcy activity. Manufacturing companies can now analyze logistics documents looking for specific parts IDs and route numbers. Combining custom entities with Comprehend’s pre-trained entities enables a complete picture of what is contained within text data. Use this data to look for trends, anomalies, or specific conditions within text.
Training the service to learn custom entity types is as easy as providing a set of those entities and a set of real-world documents that contain them. To get started, put together a list of entities. Gather these from a product database, or an Excel file that your company uses for business planning. For this blog post, we are going to train a custom entity type to extract key financial terms from financial documents.
The CSV format requires “Text” and “Type” as column headers. The text contains the entities and the type is the name of the entity type we are about to create.
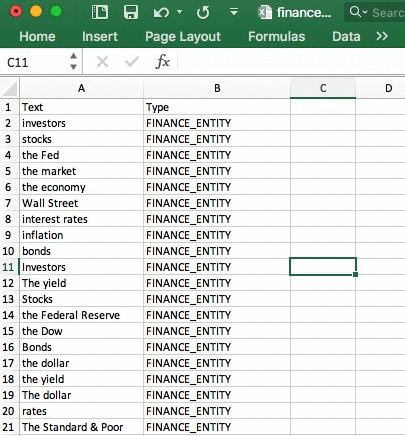
Next, collect a set of documents that contain those entities in the context of how they are used. The service needs a minimum of 1,000 documents containing at least one or more of the entities from our list.
Next, configure the training job to read the entity list CSV from one folder, and the text file containing all of the documents (one per line) from another folder.
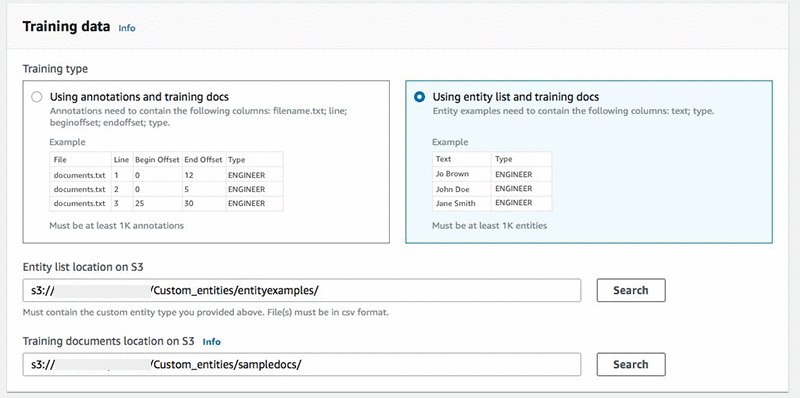
After both sets of training data are prepared, train the model. This process can take a few minutes, or multiple hours depending on the size and complexity of the training data. Using automatic machine learning, Amazon Comprehend selects the right algorithm, sampling and tuning the models to find the right combination that works best for the data.
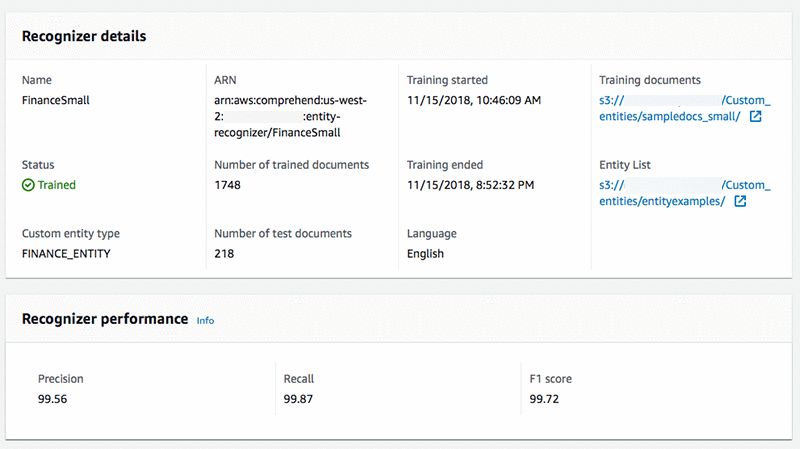
When the training is completed the custom model is ready to go. Below, view the trained model along with some helpful metadata.
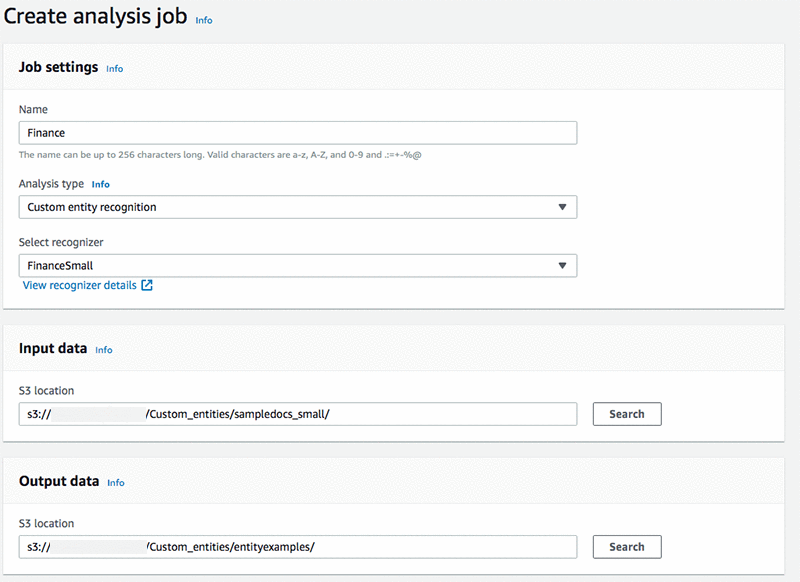
To start analyzing documents looking for custom entities, either use the portal or APIs via the AWS SDK. In this example, create an analysis job in the portal to analyze financial documents using the custom entity type:
This is how the same job submission would look using our CLI:
Take a look at the job output by opening the JSON response object and look at our custom entities. For each entity, the service also returns a confidence score metric. If there are lower confidence scores, fix them by adding more documents that contain that specific entity.
Below, view the custom model extracted financial terms.
Please visit the product forum to provide feedback or get some help.
About the author
 Nino Bice is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.
Nino Bice is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.