Artificial Intelligence
How Skello uses Amazon Bedrock to query data in a multi-tenant environment while keeping logical boundaries
This is a guest post co-written with Skello.
Skello is a leading human resources (HR) software as a service (SaaS) solution focusing on employee scheduling and workforce management. Catering to diverse sectors such as hospitality, retail, healthcare, construction, and industry, Skello offers features including schedule creation, time tracking, and payroll preparation. With approximately 20,000 customers and 400,000 daily users across Europe as of 2024, Skello continually innovates to meet its clients’ evolving needs.
One such innovation is the implementation of an AI-powered assistant to enhance user experience and data accessibility. In this post, we explain how Skello used Amazon Bedrock to create this AI assistant for end-users while maintaining customer data safety in a multi-tenant environment. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
We dive deep into the challenges of implementing large language models (LLMs) for data querying, particularly in the context of a French company operating under the General Data Protection Regulation (GDPR). Our solution demonstrates how to balance powerful AI capabilities with strict data protection requirements.
Challenges with multi-tenant data access
As Skello’s platform grew to serve thousands of businesses, we identified a critical need: our users needed better ways to access and understand their workforce data. Many of our customers, particularly those in HR and operations roles, found traditional database querying tools too technical and time-consuming. This led us to identify two key areas for improvement:
- Quick access to non-structured data – Our users needed to find specific information across various data types—employee records, scheduling data, attendance logs, and performance metrics. Traditional search methods often fell short when users had complex questions like “Show me all part-time employees who worked more than 30 hours last month” or “What’s the average sick leave duration in the retail department?”
- Visualization of data through graphs for analytics – Although our platform collected comprehensive workforce data, users struggled to transform this raw information into actionable insights. They needed an intuitive way to create visual representations of trends and patterns without writing complex SQL queries or learning specialized business intelligence tools.
To address these challenges, we needed a solution that could:
- Understand natural language questions about complex workforce data
- Correctly interpret context and intent from user queries
- Generate appropriate database queries while respecting data access rules
- Return results in user-friendly formats, including visualizations
- Handle variations in how users might phrase similar questions
- Process queries about time-based data and trends
LLMs emerged as the ideal solution for this task. Their ability to understand natural language and context, combined with their capability to generate structured outputs, made them perfectly suited for translating user questions into precise database queries. However, implementing LLMs in a business-critical application required careful consideration of security, accuracy, and performance requirements.
Solution overview
Using LLMs to generate structured queries from natural language input is an emerging area of interest. This process enables the transformation of user requests into organized data structures, which can then be used to query databases automatically.
The following diagram of Skello’s high-level architecture illustrates this user request transformation process.
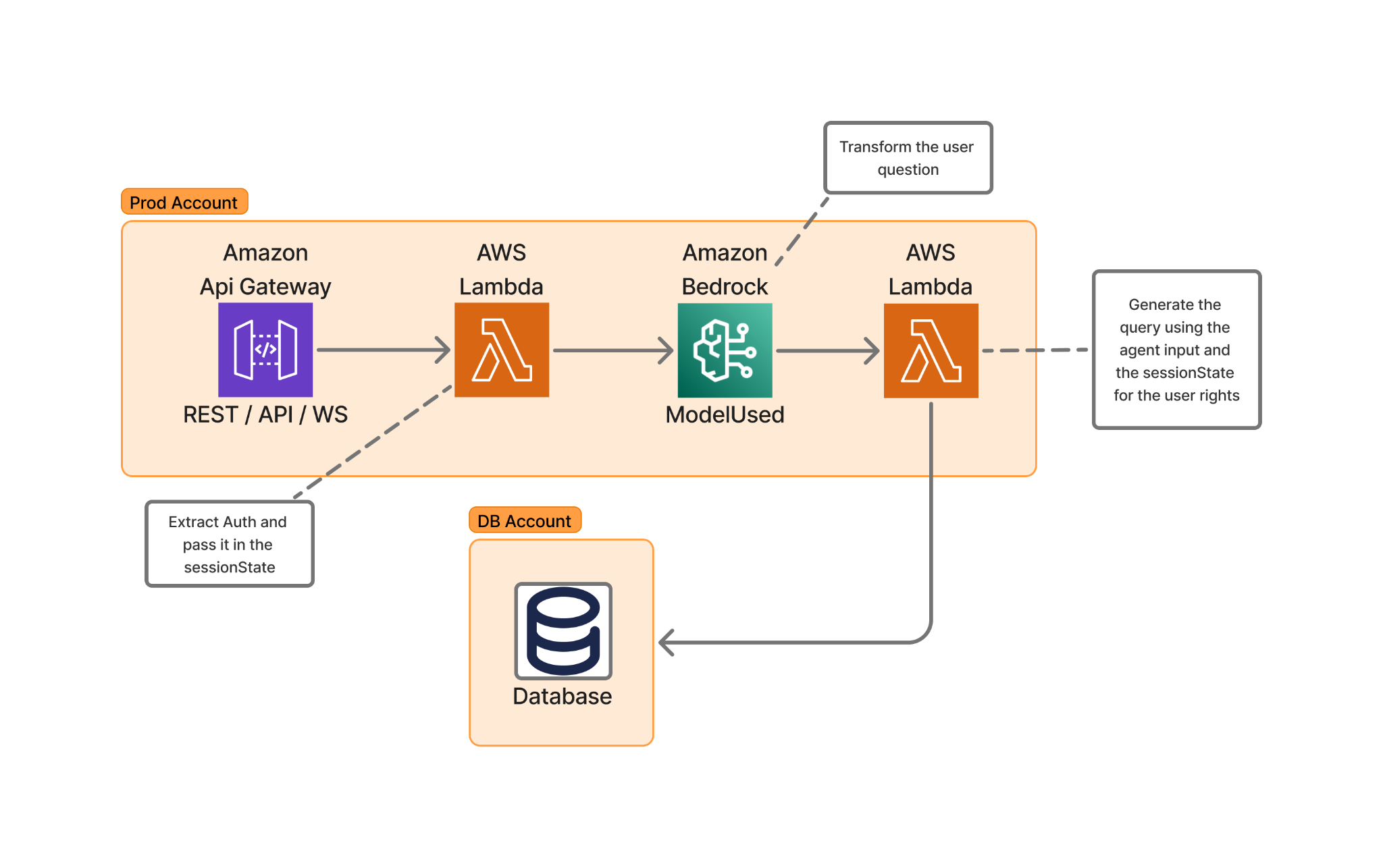
The implementation using AWS Lambda and Amazon Bedrock provides several advantages:
- Scalability through serverless architecture
- Cost-effective processing with pay-as-you-go pricing
- Low-latency performance
- Access to advanced language models like Anthropic’s Claude 3.5 Sonnet
- Rapid deployment capabilities
- Flexible integration options
Basic query generation process
The following diagram illustrates how we transform natural language queries into structured database requests. For this example, the user asks “Give me the gender parity.”
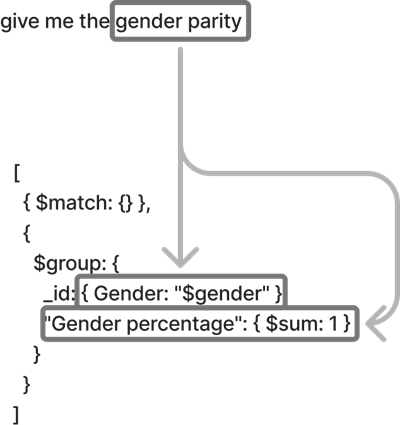
The process works as follows:
- The authentication service validates the user’s identity and permissions.
- The LLM converts the natural language to a structured query format.
- The query validation service enforces compliance with security policies.
- The database access layer executes the query within the user’s permitted scope.
Handling complex queries
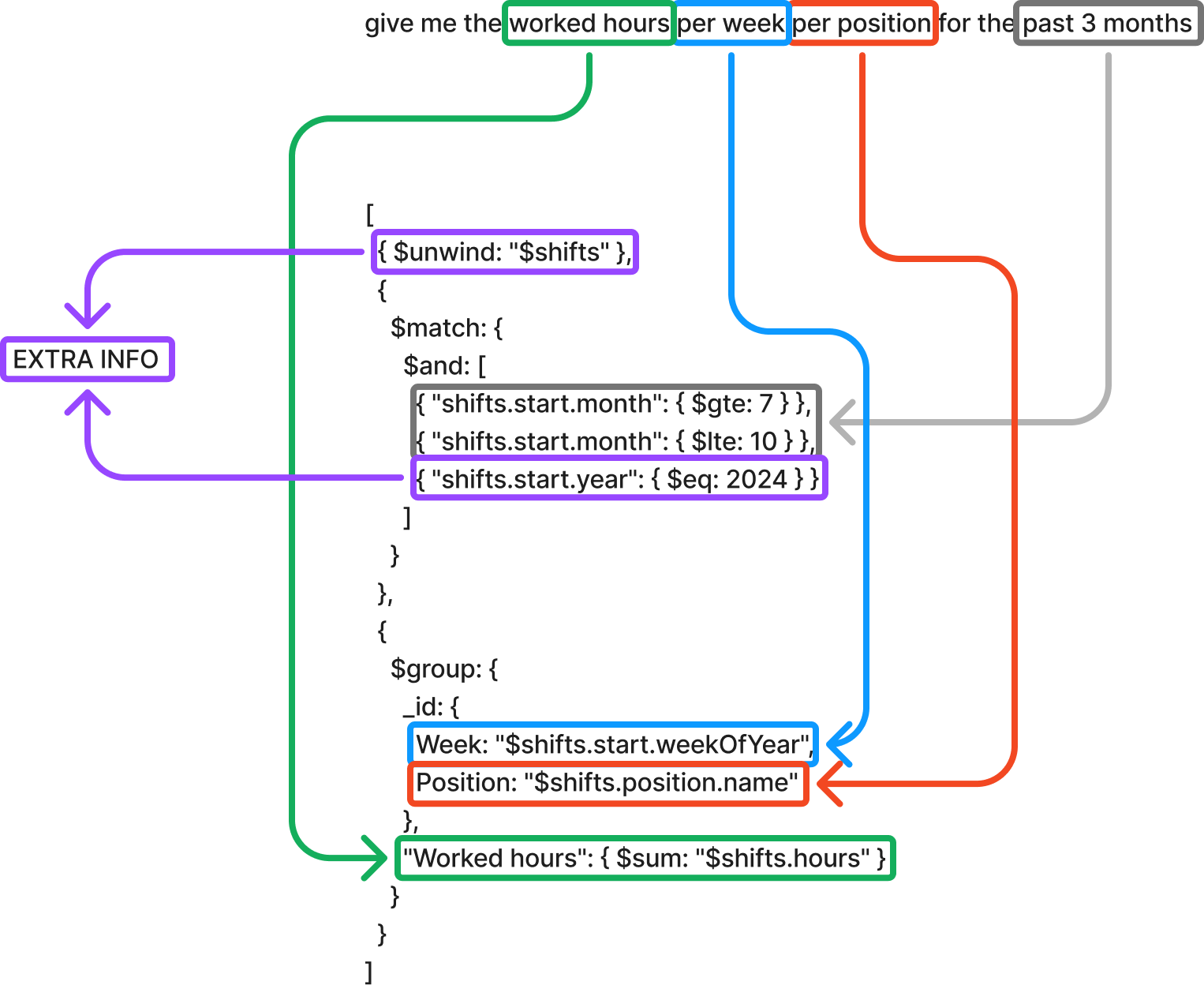
For more sophisticated requests like “Give me the worked hours per week per position for the last 3 months,” our system completes the following steps:
- Extract query components:
- Target metric: worked hours
- Aggregation levels: week, position
- Time frame: 3 months
- Generate temporal calculations:
- Use relative time expressions instead of hard-coded dates
- Implement standardized date handling patterns
Data schema optimization
To make our system as efficient and user-friendly as possible, we carefully organized our data structure—think of it as creating a well-organized filing system for a large office.
We created standardized schema definitions, establishing consistent ways to store similar types of information. For example, date-related fields (hire dates, shift times, vacation periods) follow the same format. This helps prevent confusion when users ask questions like “Show me all events from last week.” It’s similar to having all calendars in your office using the same date format instead of some using MM/DD/YY and others using DD/MM/YY.
Our system employs consistent naming conventions with clear, predictable names for all data fields. Instead of technical abbreviations like emp_typ_cd, we use clear terms like employee_type. This makes it straightforward for the AI to understand what users mean when they ask questions like “Show me all full-time employees.”
For optimized search patterns, we strategically organized our data to make common searches fast and efficient. This is particularly important because it directly impacts user experience and system performance. We analyzed usage patterns to identify the most frequently requested information and designed our database indexes accordingly. Additionally, we created specialized data views that pre-aggregate common report requests. This comprehensive approach means questions like “Who’s working today?” get answered almost instantly.
We also established clear data relationships by mapping out how different pieces of information relate to each other. For example, we clearly connect employees to their departments, shifts, and managers. This helps answer complex questions like “Show me all department managers who have team members on vacation next week.”
These optimizations deliver real benefits to our users:
- Faster response times when asking questions
- More accurate answers to queries
- Less confusion when referring to specific types of data
- Ability to ask more complex questions about relationships between different types of information
- Consistent results when asking similar questions in different ways
For example, whether a user asks “Show me everyone’s vacation time” or “Display all holiday schedules,” the system understands they’re looking for the same type of information. This reliability makes the system more trustworthy and easier to use for everyone, regardless of their technical background.
Graph generation and display
One of the most powerful features of our system is its ability to turn data into meaningful visual charts and graphs automatically. This consists of the following actions:
- Smart label creation – The system understands what your data means and creates clear, readable labels. For example, if you ask “Show me employee attendance over the last 6 months,” the horizontal axis automatically labels the months (January through June), the vertical axis shows attendance numbers with simple-to-read intervals, and the title clearly states what you’re looking at: “Employee Attendance Trends.”
- Automatic legend creation – The system creates helpful legends that explain what each part of the chart means. For instance, if you ask “Compare sales across different departments,” different departments get different colors, a clear legend shows which color represents which department, and additional information like “Dashed lines show previous year” is automatically added when needed.
- Choosing the right type of chart – The system is smart about picking the best way to show your information. For example, it uses bar charts for comparing different categories (“Show me sales by department”), line graphs for trends over time (“How has attendance changed this year?”), pie charts for showing parts of a whole (“What’s the breakdown of full-time vs. part-time staff?”), and heat maps for complex patterns (“Show me busiest hours per day of the week”).
- Smart sizing and scaling – The system automatically adjusts the size and scale of charts to make them simple to read. For example, if numbers range from 1–100, it might show intervals of 10; if you’re looking at millions, it might show them in a more readable way (1M, 2M, etc.); charts automatically resize to show patterns clearly; and important details are never too small to see.
All of this happens automatically—you ask your question, and the system handles the technical details of creating a clear, professional visualization. For example, the following figure is an example for the question “How many hours my employees worked over the past 7 weeks?”
Security-first architecture
Our implementation adheres to OWASP best practices (specifically LLM06) by maintaining complete separation between security controls and the LLM.
Through dedicated security services, user authentication and authorization checks are performed before LLM interactions, with user context and permissions managed through Amazon Bedrock SessionParameters, keeping security information entirely outside of LLM processing.
Our validation layer uses Amazon Bedrock Guardrails to protect against prompt injection, inappropriate content, and forbidden topics such as racism, sexism, or illegal content.
The system’s architecture implements strict role-based access controls through a detailed permissions matrix, so users can only access data within their authorized scope. For authentication, we use industry-standard JWT and SAML protocols, and our authorization service maintains granular control over data access permissions.
This multi-layered approach prevents potential security bypasses through prompt manipulation or other LLM-specific attacks. The system automatically enforces data boundaries at both database and API levels, effectively preventing cross-contamination between different customer accounts. For instance, department managers can only access their team’s data, with these restrictions enforced through database compartmentalization.
Additionally, our comprehensive audit system maintains immutable logs of all actions, including timestamps, user identifiers, and accessed resources, stored separately to protect their integrity. This security framework operates seamlessly in the background, maintaining robust protection of sensitive information without disrupting the user experience or legitimate workflows.
Benefits
Creating data visualizations has never been more accessible. Even without specialized expertise, you can now produce professional-quality charts that communicate your insights effectively. The streamlined process makes sure your visualizations remain consistently clear and intuitive, so you can concentrate on exploring your data questions instead of spending time on presentation details.
The solution works through simple conversational requests that require no technical knowledge or specialized software. You simply describe what you want to visualize using everyday language and the system interprets your request and creates the appropriate visualization. There’s no need to learn complex software interfaces, remember specific commands, or understand data formatting requirements. The underlying technology handles the data processing, chart selection, and professional formatting automatically, transforming your spoken or written requests into polished visual presentations within moments.
Your specific information needs to drive how the data is displayed, making the insights more relevant and actionable. When it’s time to share your findings, these visualizations seamlessly integrate into your reports and presentations with polished formatting that enhances your overall message. This democratization of data visualization empowers everyone to tell compelling data stories.
Conclusion
In this post, we explored Skello’s implementation of an AI-powered assistant using Amazon Bedrock and Lambda. We saw how end-users can query their own data in a multi-tenant environment while maintaining logical boundaries and complying with GDPR regulations. The combination of serverless architecture and advanced language models proved effective in enhancing data accessibility and user experience.
We invite you to explore the AWS Machine Learning Blog for more insights on AI solutions and their potential business applications. If you’re interested in learning more about Skello’s journey in modernizing HR software, check out our blog post series on the topic.
If you have any questions or suggestions about implementing similar solutions in your own multi-tenant environment, please feel free to share them in the comments section.
About the authors
 Nicolas de Place is a Data & AI Solutions Architect specializing in machine learning strategy for high-growth startups. He empowers emerging companies to harness the full potential of artificial intelligence and advanced analytics, designing scalable ML architectures and data-driven solutions
Nicolas de Place is a Data & AI Solutions Architect specializing in machine learning strategy for high-growth startups. He empowers emerging companies to harness the full potential of artificial intelligence and advanced analytics, designing scalable ML architectures and data-driven solutions
 Cédric Peruzzi is a Software Architect at Skello, where he focuses on designing and implementing Generative AI features. Before his current role, he worked as a software engineer and architect, bringing his experience to help build better software solutions.
Cédric Peruzzi is a Software Architect at Skello, where he focuses on designing and implementing Generative AI features. Before his current role, he worked as a software engineer and architect, bringing his experience to help build better software solutions.