Artificial Intelligence
Hyperparameter optimization for fine-tuning pre-trained transformer models from Hugging Face
Large attention-based transformer models have obtained massive gains on natural language processing (NLP). However, training these gigantic networks from scratch requires a tremendous amount of data and compute. For smaller NLP datasets, a simple yet effective strategy is to use a pre-trained transformer, usually trained in an unsupervised fashion on very large datasets, and fine-tune it on the dataset of interest. Hugging Face maintains a large model zoo of these pre-trained transformers and makes them easily accessible even for novice users.
However, fine-tuning these models still requires expert knowledge, because they’re quite sensitive to their hyperparameters, such as learning rate or batch size. In this post, we show how to optimize these hyperparameters with the open-source framework Syne Tune for distributed hyperparameter optimization (HPO). Syne Tune allows us to find a better hyperparameter configuration that achieves a relative improvement between 1-4% compared to default hyperparameters on popular GLUE benchmark datasets. The choice of the pre-trained model itself can also be considered a hyperparameter and therefore be automatically selected by Syne Tune. On a text classification problem, this leads to an additional boost in accuracy of approximately 5% compared to the default model. However, we can automate more decisions a user needs to make; we demonstrate this by also exposing the type of instance as a hyperparameter that we later use to deploy the model. By selecting the right instance type, we can find configurations that optimally trade off cost and latency.
For an introduction to Syne Tune please refer to Run distributed hyperparameter and neural architecture tuning jobs with Syne Tune.
Hyperparameter optimization with Syne Tune
We will use the GLUE benchmark suite, which consists of nine datasets for natural language understanding tasks, such as textual entailment recognition or sentiment analysis. For that, we adapt Hugging Face’s run_glue.py training script. GLUE datasets come with a predefined training and evaluation set with labels as well as a hold-out test set without labels. Therefore, we split the training set into a training and validation sets (70%/30% split) and use the evaluation set as our holdout test dataset. Furthermore, we add another callback function to Hugging Face’s Trainer API that reports the validation performance after each epoch back to Syne Tune. See the following code:
We start with optimizing typical training hyperparameters: the learning rate, warmup ratio to increase the learning rate, and the batch size for fine-tuning a pretrained BERT (bert-base-cased) model, which is the default model in the Hugging Face example. See the following code:
As our HPO method, we use ASHA, which samples hyperparameter configurations uniformly at random and iteratively stops the evaluation of poorly performing configurations. Although more sophisticated methods utilize a probabilistic model of the objective function, such as BO or MoBster exists, we use ASHA for this post because it comes without any assumptions on the search space.
In the following figure, we compare the relative improvement in test error over Hugging Faces’ default hyperparameter configuration.
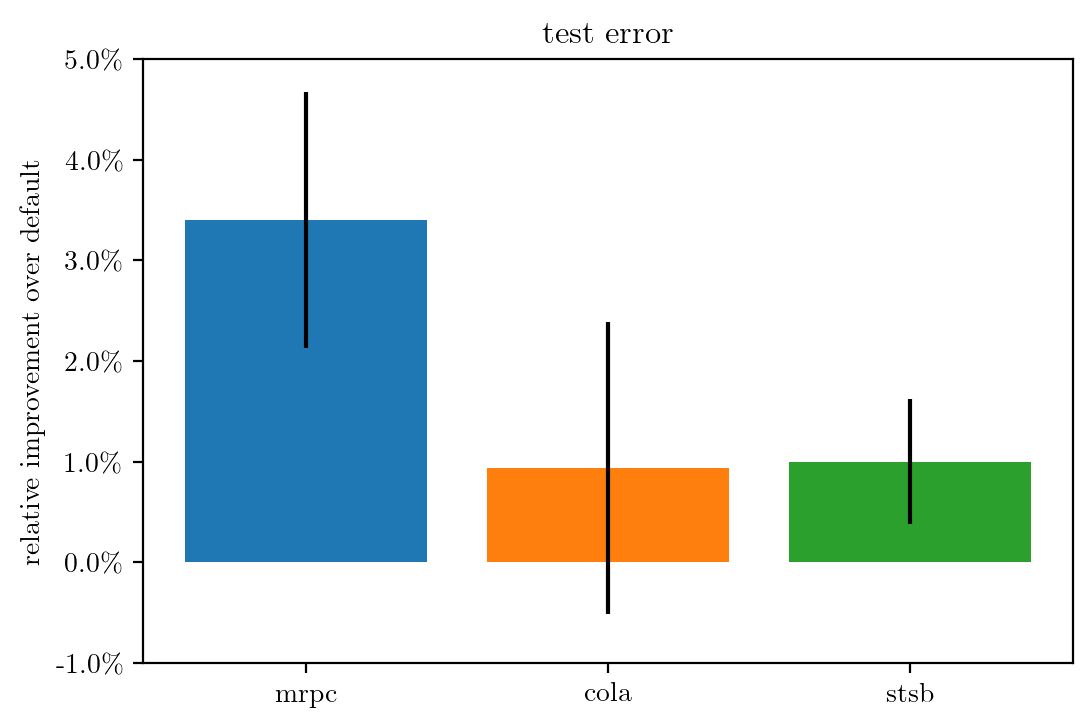
For simplicity, we limit the comparison to MRPC, COLA, and STSB, but we also observe similar improvements also for other GLUE datasets. For each dataset, we run ASHA on a single ml.g4dn.xlarge Amazon SageMaker instance with a runtime budget of 1,800 seconds, which corresponds to approximately 13, 7, and 9 full function evaluations on these datasets, respectively. To account for the intrinsic randomness of the training process, for example caused by the mini-batch sampling, we run both ASHA and the default configuration for five repetitions with an independent seed for the random number generator and report the average and standard deviation of the relative improvement across the repetitions. We can see that, across all datasets, we can in fact improve predictive performance by 1-3% relative to the performance of the carefully selected default configuration.
Automate selecting the pre-trained model
We can use HPO to not only find hyperparameters, but also automatically select the right pre-trained model. Why do we want to do this? Because no a single model outperforms across all datasets, we have to select the right model for a specific dataset. To demonstrate this, we evaluate a range of popular transformer models from Hugging Face. For each dataset, we rank each model by its test performance. The ranking across datasets (see the following Figure) changes and not one single model that scores the highest on every dataset. As reference we also show the absolute test performance of each model and dataset in the following figure.
 |
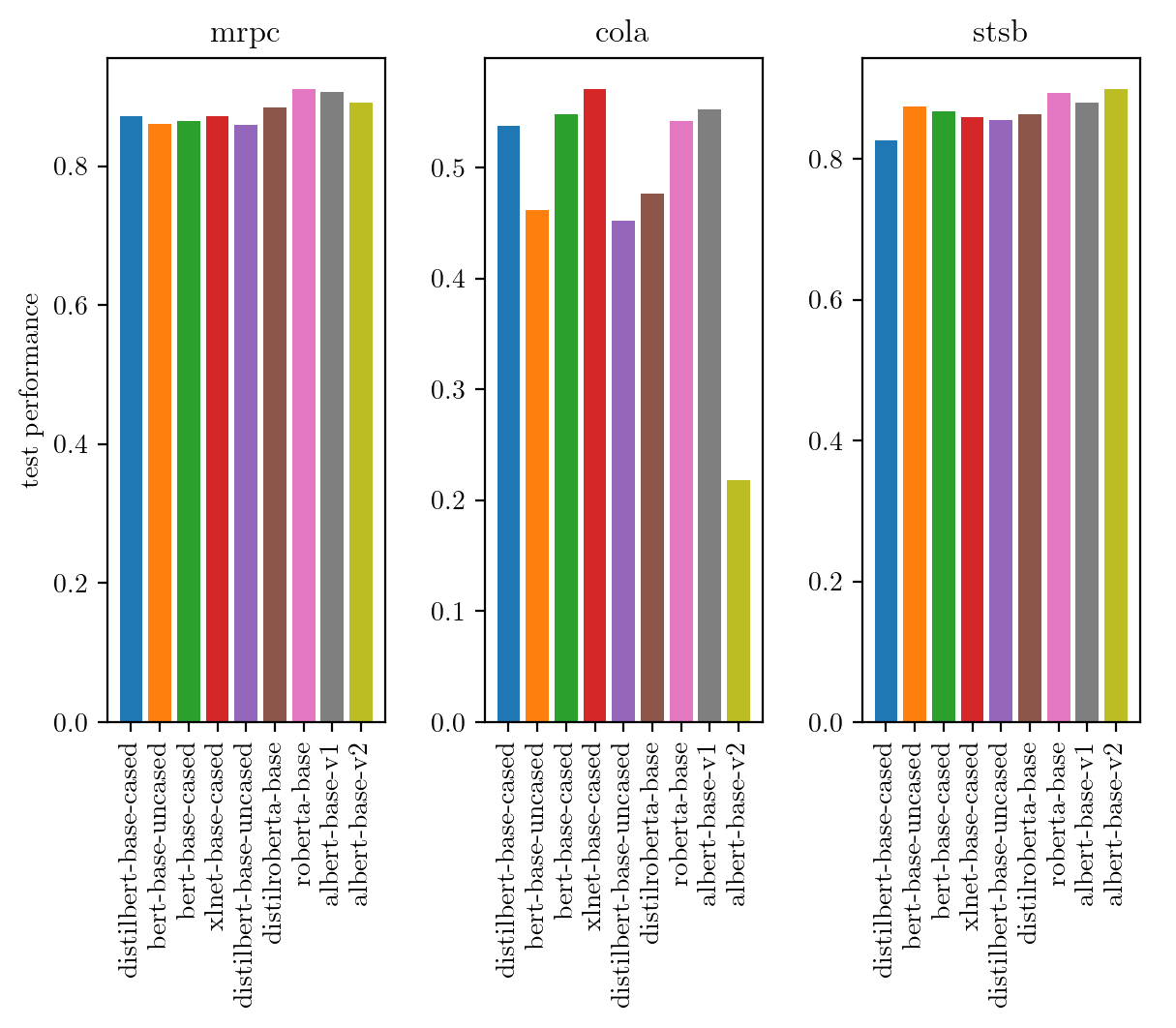 |
To automatically select the right model, we can cast the choice of the model as categorical parameters and add this to our hyperparameter search space:
Although the search space is now larger, that doesn’t necessarily mean that it’s harder to optimize. The following figure shows the test error of the best observed configuration (based on the validation error) on the MRPC dataset of ASHA over time when we search in the original space (blue line) (with a BERT-base-cased pre-trained model) or in the new augmented search space (orange line). Given the same budget, ASHA is able to find a much better performing hyperparameter configuration in the extended search space than in the smaller space.

Automate selecting the instance type
In practice, we might not just care about optimizing predictive performance. We might also care about other objectives, such as training time, (dollar) cost, latency, or fairness metrics. We also need to make other choices beyond the hyperparameters of the model, for example selecting the instance type.
Although the instance type doesn’t influence predictive performance, it strongly impacts the (dollar) cost, training runtime, and latency. The latter becomes particularly important when the model is deployed. We can phrase HPO as a multi-objective optimization problem, where we aim to optimize multiple objectives simultaneously. However, no single solution optimizes all metrics at the same time. Instead, we aim to find a set of configurations that optimally trade off one objective vs. the other. This is called the Pareto set.
To analyze this setting further, we add the choice of the instance type as an additional categorical hyperparameter to our search space:
We use MO-ASHA, which adapts ASHA to the multi-objective scenario by using non-dominated sorting. In each iteration, MO-ASHA also selects for each configuration also the type of instance we want to evaluate it on. To run HPO on a heterogeneous set of instances, Syne Tune provides the SageMaker backend. With this backend, each trial is evaluated as an independent SageMaker training job on its own instance. The number of workers defines how many SageMaker jobs we run in parallel at a given time. The optimizer itself, MO-ASHA in our case, runs either on the local machine, a Sagemaker notebook or on a separate SageMaker training job. See the following code:
The following figures show the latency vs test error on the left and latency vs cost on the right for random configurations sampled by MO-ASHA (we limit the axis for visibility) on the MRPC dataset after running it for 10,800 seconds on four workers. Color indicates the instance type. The dashed black line represents the Pareto set, meaning the set of points that dominate all other points in at least one objective.
 |
 |
We can observe a trade-off between latency and test error, meaning the best configuration with the lowest test error doesn’t achieve the lowest latency. Based on your preference, you can select a hyperparameter configuration that sacrifices on test performance but comes with a smaller latency. We also see the trade off between latency and cost. By using a smaller ml.g4dn.xlarge instance, for example, we only marginally increase latency, but pay a fourth of the cost of an ml.g4dn.8xlarge instance.
Conclusion
In this post, we discussed hyperparameter optimization for fine-tuning pre-trained transformer models from Hugging Face based on Syne Tune. We saw that by optimizing hyperparameters such as learning rate, batch size, and the warm-up ratio, we can improve upon the carefully chosen default configuration. We can also extend this by automatically selecting the pre-trained model via hyperparameter optimization.
With the help of Syne Tune’s SageMaker backend, we can treat the instance type as an hyperparameter. Although the instance type doesn’t affect performance, it has a significant impact on the latency and cost. Therefore, by casting HPO as a multi-objective optimization problem, we’re able to find a set of configurations that optimally trade off one objective vs. the other. If you want to try this out yourself, check out our example notebook.
About the Authors
 Aaron Klein is an Applied Scientist at AWS.
Aaron Klein is an Applied Scientist at AWS.
 Matthias Seeger is a Principal Applied Scientist at AWS.
Matthias Seeger is a Principal Applied Scientist at AWS.
 David Salinas is a Sr Applied Scientist at AWS.
David Salinas is a Sr Applied Scientist at AWS.
 Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
 Cedric Archambeau is a Principal Applied Scientist at AWS and Fellow of the European Lab for Learning and Intelligent Systems.
Cedric Archambeau is a Principal Applied Scientist at AWS and Fellow of the European Lab for Learning and Intelligent Systems.