Artificial Intelligence
Identify potential root cause in business-critical anomalies using Amazon Lookout for Metrics
We are excited to launch a causal contribution analysis capability in Amazon Lookout for Metrics that helps you to understand the potential root causes for the business-critical anomalies in the data. Previously, you were only given the root causes for a single anomaly per measure. You had to analyze to determine if causal relationships existed between the detected anomalies in different measures. When focusing on a single anomaly, you can easily miss the anomaly’s downstream (or upstream) impact. For example, you may see a spike in your checkout cart abandonment and know that your revenue will decrease. However, you may not know what caused the checkout carts to be abandoned at a higher rate. The causal contribution analysis feature can tell you that the spike in checkout cart abandonment may be due to spikes in transaction failures or sudden changes in prices due to promotion expiration.
Lookout for Metrics uses machine learning (ML) to automatically detect and diagnose anomalies in large datasets where deviations from normal are hard to detect and missed anomalies have business-critical impact. Lookout for Metrics reduces the time to implement AI/ML services for business-critical problems.
In this post, we discuss the new causal contribution analysis capability and its benefits.
Challenges in anomaly detection
Anomaly detection has two parts: detecting anomalies and identifying the root cause that triggered the anomalies so that team can take action to mitigate the problem.
Traditional business intelligence (BI) systems that use static threshold-based or rule-based anomalies have three problems. First, you might have millions of metrics to track across multiple data sources. Take digital advertisement, for example—you want to track metrics like impression, clicks, revenue, and shopping cart metrics across campaign IDs, product categories, geographies, and more. And it’s the same for any domain, be it retail, telecom, gaming, or financial services. With traditional BI tools, managing data across multiple sources, creating dashboards and reports, and adding alerts at a granular level requires a lot of manual work and isn’t scalable.
Second, these traditional BI tools work by setting up rules. You set up a range, and anything outside the range is an anomaly and you are alerted on those. If the range is too broad, you miss important alerts, and if it’s too narrow, you receive too many false alerts.

These ranges (upper bound and lower bound in image above) are also static, and don’t change based on the time of the day, day of the week, or seasons; they need to be manually updated. You’re likely to miss important anomalies and receive too many false alarms, or you lose trust in the tool and start ignoring these alerts altogether.
Lastly, BI reports and dashboards are often generated at the end of hour, end of day, or end of week, when it’s too late for you to act on a problem. And even when these results come, it doesn’t answer the why. So developers, analysts, and business owners can spend weeks trying to identify the root cause of the anomaly, delaying meaningful action even further.
Causal inference in Lookout for Metrics
Although asking for the root cause of an unexpected event seems to be at the heart of the human way of understanding the world, statistical associations are often misinterpreted as a causal influence. That is, correlation doesn’t imply causation, and discerning the causes of events from observational data requires specialized causal inference methods.
The root cause analysis in Lookout for Metrics uses causal inference techniques to increase the visibility and interpretability of anomalies across measures. Lookout for Metrics is capable of not only identifying causal drivers, but also quantitatively attributing the anomalous events to them, providing a percentage score of likelihood among the probable causal drivers of an anomalous event. For example, Lookout for Metrics can now draw causal links between a drop in advertisement views (anomaly) due to fewer clicks on your website, IOS, and Android (causation), leading to a decline in the revenue (downstream impact). Suppose one or more potential root causes occur (website, iOS, Android). In that case, Lookout for Metrics can identify the most likely cause (for example, website with a 90% likelihood) that led to a drop in advertisement views.
The scientific approach relies on a two-step procedure:
- Infer the causal relations between the measures.
- Based on the inferred causal structure, attribute the anomalies of the affected measure to the causing measures.
To infer the causal relations between the measures, we use a Granger causality method that takes the panel data structure of Lookout for Metrics into account. The existing Granger causality methods for panel data can’t deal with dependencies across dimension value combinations (for instance, dependencies of revenue across different countries that we typically have in real data). For example, events such as Black Friday increase the revenue of multiple countries and therefore there is an external source that renders the revenue of different countries dependent). We therefore had to develop our own Granger causality[1] method on panel data that can deal with these types of dependencies.
Once the causal structure is available, we attribute the anomalies of the affected measure to its causing measures to quantify the cause-effect relationships.
Analyze anomalies on the Lookout for Metrics console
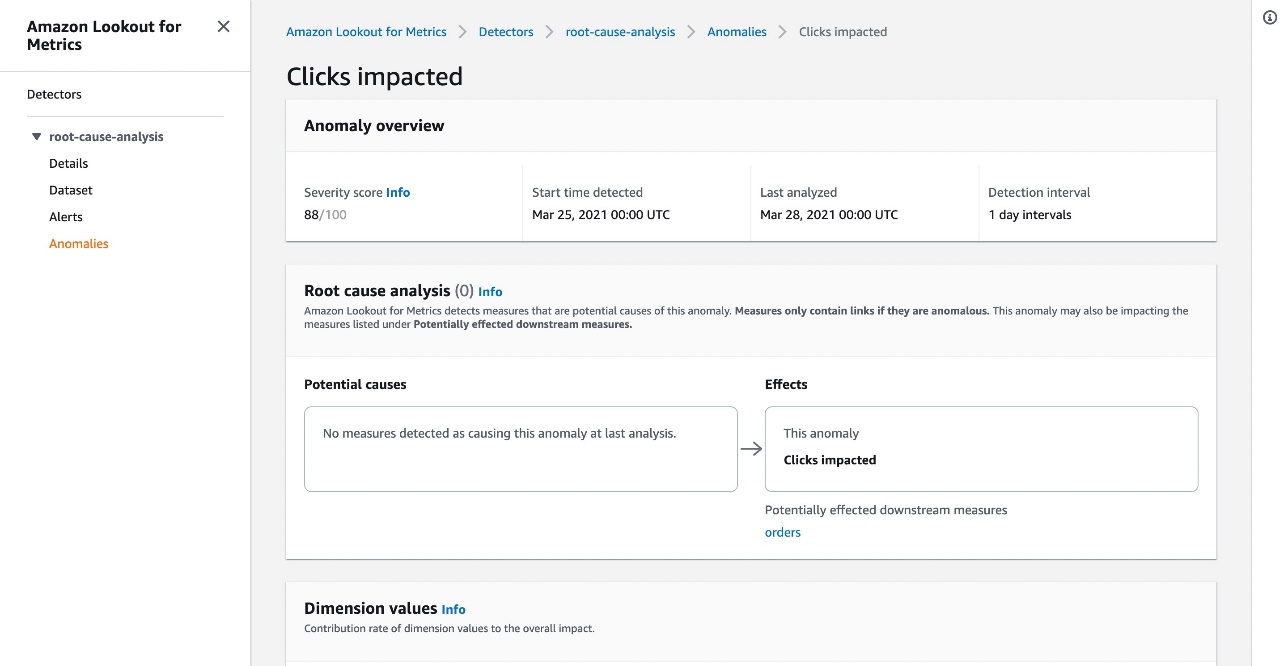
After Lookout for Metrics starts anomaly detection, you can look for the detected anomalies on the Anomalies page for the detector. When you choose an anomaly, you’re redirected to the details page for the observed anomaly.

The anomaly details page includes a Root cause analysis section. This section tries to explain this observed anomaly with respect to the other anomalies for the anomaly detector configured measures.
In the following example, “Revenue impacted” is the observed anomaly, and the potential causes include orders and non-configured measures. Orders contributes approximately 81.84% to the current anomaly, namely revenue that leads to a downstream impact on profit.

Choosing the potential cause orders takes us to the details of its observed anomaly. In this case, the possible causes for this anomaly are clicks and non-configured measures. Clicks could be one of the potential causes of this anomaly, but it gets a relatively low contribution score of 8.37%, and the detector doesn’t observe anything anomalous for it. In this case, Lookout for Metrics concludes that the orders anomaly is caused by external factors or measures that weren’t configured for monitoring during the detector setup phase. This anomaly in orders has a potential downstream impact on profit and revenue.

Choosing the potential downstream impact profit takes us to the details of its observed anomaly. In this case, the potential causes seem to be a mix of anomalies in revenue, orders, and non-configured measures, with respective contribution scores of 33%, 14%, and 53%. No downstream measures are affected by this anomaly.

For this example, the anomaly in profit can be partially explained by the anomalies in revenue and orders. Then the anomaly in revenue can be explained by the anomaly in orders with a high certainty.
Conclusion
The new causal contribution analysis capability in Lookout for Metrics detects the causal interaction between anomalies in your measures. To achieve this, the detector learns the causal relation between measures in your data fully self-supervised and uses this causal information to trace anomalies back to their root causes. This feature can help you causally connect anomalies across measures and provides you with a tool to quickly diagnose and subsequently fix any issues in your system.
[1] L. Minorics, C. Turkmen, P. Bloebaum, D. Kernert, L. Callot and D. Janzing. Testing Granger Non-Causality in Panels with Cross-Sectional dependencies. AISTATS, 2022.
About the Authors
 Lenon Minorics is an Applied Scientist focusing on causal inference and anomaly detection. Prior to Amazon, Lenon was an academic researcher in mathematics. His personal research interests include machine learning, causal inference, stochastics, and fractal geometry. In his free time, Lenon enjoys practicing all kinds of sports, especially Brazilian Jiu-Jitsu.
Lenon Minorics is an Applied Scientist focusing on causal inference and anomaly detection. Prior to Amazon, Lenon was an academic researcher in mathematics. His personal research interests include machine learning, causal inference, stochastics, and fractal geometry. In his free time, Lenon enjoys practicing all kinds of sports, especially Brazilian Jiu-Jitsu.
 Shashank Srivastava is Senior Product Manager for Amazon AI vertical services. He is passionate about solving problems in AI in NLP, novelty detection, and data scarcity. In his free time, Shashank enjoys playing tennis and golf.
Shashank Srivastava is Senior Product Manager for Amazon AI vertical services. He is passionate about solving problems in AI in NLP, novelty detection, and data scarcity. In his free time, Shashank enjoys playing tennis and golf.
 Caner Türkmen is an Applied Scientist at Amazon Web Services, where he works on problems at the intersection of machine learning, forecasting, and anomaly detection. Before joining AWS, he worked in the management consulting industry as a data scientist, serving the financial services and telecommunications industries on projects across the globe. Caner’s personal research interests span a range of topics, including probabilistic and Bayesian ML, stochastic processes, and their practical applications.
Caner Türkmen is an Applied Scientist at Amazon Web Services, where he works on problems at the intersection of machine learning, forecasting, and anomaly detection. Before joining AWS, he worked in the management consulting industry as a data scientist, serving the financial services and telecommunications industries on projects across the globe. Caner’s personal research interests span a range of topics, including probabilistic and Bayesian ML, stochastic processes, and their practical applications.
 Alex Kim is a Sr. Product Manager for AWS AI Services. His mission is to deliver AI/ML solutions to all customers who can benefit from it. In his free time, he enjoys all types of sports and discovering new places to eat.
Alex Kim is a Sr. Product Manager for AWS AI Services. His mission is to deliver AI/ML solutions to all customers who can benefit from it. In his free time, he enjoys all types of sports and discovering new places to eat.
 Syed Ahsan Ishtiaque is a Software Engineer at Amazon Web Services. He uses his experience in the large-scale distributed systems and machine learning to build practical solutions in this space. He has helped build various solutions across AWS and Amazon. Outside of AWS, he is a photographer and loves taking care of his lawn.
Syed Ahsan Ishtiaque is a Software Engineer at Amazon Web Services. He uses his experience in the large-scale distributed systems and machine learning to build practical solutions in this space. He has helped build various solutions across AWS and Amazon. Outside of AWS, he is a photographer and loves taking care of his lawn.
 Ketan Vijayvargiya is a Senior Software Development Engineer in Amazon Web Services (AWS). His focus areas are machine learning, distributed systems and open source. Outside work, he likes to spend his time self-hosting and enjoying nature.
Ketan Vijayvargiya is a Senior Software Development Engineer in Amazon Web Services (AWS). His focus areas are machine learning, distributed systems and open source. Outside work, he likes to spend his time self-hosting and enjoying nature.