AWS Cloud Operations Blog
How Honeycomb improved resilience using AWS Fault Injection Service
Building resilience within cloud workloads is an important goal for ISVs to prevent application downtime, increase system reliability, and build customer trust. Honeycomb.io is a fast and collaborative observability platform for software developers and engineering teams to understand and troubleshoot their cloud-native applications. Honeycomb gives you the rich context at sub-second query speeds and AI-assisted investigations you need to debug your code at the pace of AI.
This blog post explores how Honeycomb transformed their resilience testing approach using AWS Fault Injection Service, shifting from reactive incident response to proactive resilience testing.
The Challenge: From Reactive to Proactive
Importance of Resilience Testing
Resilience testing helps build confidence in a system’s ability to withstand degradation in production. Experiments identify weak points that could lead to failure, which helps customers improve their systems to automatically and efficiently mitigate failure and degradation. Injecting faults to verify the resilience of a workload allows customers to gain confidence that the recovery procedures of their resilient design will work in the case of a real fault.
As part of the Reliability Pillar best practices within the AWS Well-Architected Framework, AWS recommends incorporating both resilience testing as well as fault injection experiments to be a part of pre-production and production workloads using Game day simulations.
Honeycomb’s Approach
The Honeycomb team’s aim was to maintain system reliability in the face of unexpected failures. Although there were documented procedures for outages in place, the Honeycomb team wanted to move beyond theoretical readiness to practical strategy. Before drawing out a complete strategy, the team evaluated some considerations and primary objectives, listed below:
- Building Redundancy: Recognizing that individual Availability Zones (AZs) can experience impairments for AWS services, the team needed to validate their multi-AZ redundancy strategy.
- Testing for Uncertainty: Chaos engineering or simulated failures help test real-world problems that could arise in the system. The team wanted to control the blast radius while testing failure scenarios.
- Increasing Customer Trust: Increasing application uptime and system robustness builds customer confidence, which in turn improves customer retention.
- Supporting Existing Infrastructure: The team needed seamless integration with all their cloud services. The complex interconnections between various AWS services presented its own challenge.
- Observability and Monitoring: The team needed to enhance current telemetry collection systems, implement distributed tracing, and develop custom dashboards that provided real-time insights into system behavior during experiments.
The Solution: Implementing AWS Fault Injection Service
Considering all factors above, Honeycomb selected AWS Fault Injection Service (FIS) for achieving their resilience goals and the ability to provide precise, controlled fault injection at scale. AWS FIS offered guardrails such as stop conditions and safety levers, which were necessary to a testing environment, along with comprehensive monitoring capabilities, and support for automated experiment execution. This choice aligned with Honeycomb’s three objectives – validating their disaster recovery strategies, improving system resilience, and enhancing incident response procedures.
FIS’s logging and reporting capabilities helped document experiment results, providing evidence that could be used for compliance and audit purposes, while also enabling post-experiment analysis in support of Honeycomb’s proactive reliability practices.
Honeycomb decided to construct the experiment in a way that would recreate, as closely as possible, a total AZ outage for all production infrastructure. Thorough preparation preceded the actual experiments, where the team planned extensively. They outlined test parameters, established clear success metrics, and developed comprehensive rollback strategies. This careful groundwork was crucial for balancing their goals of maximizing learning opportunities while making real-world improvements to their ability to recover from failure in production.
The Experiment: Simulating Disaster in Production
Honeycomb’s architecture is designed to run on Multi-AZ Amazon Elastic Kubernetes Service (EKS) clusters behind AWS Application Load Balancers (ALBs) with PrivateLink connectivity available using AWS Network Load Balancers. Kafka is deployed in a multi-AZ mode as well and is used to ingest the event streams.
The team’s approach to this simulation experiment was built on three crucial pillars:
- Building Test Scenarios: The team began by defining a clear hypothesis: production services should continue operating normally even during a complete Availability Zone failure. They built progressively larger test scenarios, starting small and scaling up to a full AZ outage simulation, using controlled failures such as compute termination, latency injection, and service degradation. The hypothesis was confirmed: Kubernetes successfully handled the redistributed load, and customers experienced no significant service impact.
- Planning and Rollback: With each test, they planned early for resource capacity, IAM permissions, rollback strategies, and expected behaviors.
- Real-time Monitoring: The team ensured that they were monitoring the system behavior for any anomalies in real-time. They also created risk assessments and impact maps for the tests.
Before executing any chaos experiments, the team defined what “normal” looked like for the application. Steady state was characterized by key metrics including successful transaction rates, API response latency thresholds, error rate baselines, and service availability targets. These metrics served as the reference point against which all experiment outcomes were measured — if these indicators remained within acceptable bounds during a simulated impairment, the hypothesis was considered validated.
For each of the preliminary tests, Honeycomb depended on close collaboration between the AWS account team and Honeycomb engineering teams to ensure alignment with best practices and enterprise-grade cloud resilience strategies. The AWS Technical Account Manager (TAM) — a designated technical advisor included with AWS Enterprise Support — worked closely with the Honeycomb team throughout the engagement. The TAM leveraged AWS Countdown to drive pre-event readiness reviews, coordinate subject matter experts, oversee capacity planning, and lead post-event retrospectives, ensuring the team was fully prepared before a single test ran. This partnership enhanced test execution efficiency and provided deep insights into optimizing AWS resource utilization during failure conditions.
The team conducted mapping of critical AWS services, including AWS Lambda functions, Elastic Load Balancers, and Auto Scaling groups, to understand their complex interdependencies. This mapping proved essential for predicting failure cascades and validating redundancy mechanisms for the larger experiment to simulate a complete AZ failure.
While rollback procedures were planned as part of the experiment design, the team established clear triggers and execution paths for both manual and automated recovery. Rollback would be initiated if monitored metrics, such as error rates or latency, exceeded steady state thresholds during an experiment. In practice, FIS stop conditions served as the first line of automated rollback, immediately terminating the experiment upon alarm breach. For scenarios requiring infrastructure-level recovery, automated rollback actions were supported through AWS Systems Manager, enabling rapid remediation without manual intervention.
Throughout the process, the team maintained a feedback-driven approach, integrating insights from each failure test into future system enhancements. Their implementation of continuous monitoring and automated alerting mechanisms enabled quick responses and iterative improvements to the cloud environment, creating a learning and enhancement feedback loop.
FIS in Action
When the team had developed enough confidence through smaller tests on their development environment, Honeycomb decided to move their tests to production infrastructure. This introduced greater complexity across multiple regional clusters. While Honeycomb engineers execute these experiments, AWS FIS provides the structured, safety-focused service that helps to control the fault injection and experiment lifecycle, enabling it to be automated.
The team leveraged several key AWS Fault Injection Service (FIS) features to ensure experiments were both effective and safely controlled:
- Experiment templates were used to define repeatable, version-controlled failure scenarios.
- IAM role-based permissions ensured that FIS actions were scoped and executed with least-privilege access.
- Stop conditions were configured as a critical safety mechanism — linked to Amazon CloudWatch alarms, these automatically halted any experiment if key metrics breached predefined thresholds, preventing controlled tests from escalating into real service impairments.
Honeycomb planned for a comprehensive two-hour Availability Zone failure simulation in their production environment. As part of this test, the team intentionally terminated one-third of their production infrastructure, affecting their Amazon EC2 instances across their 3 availability zones.
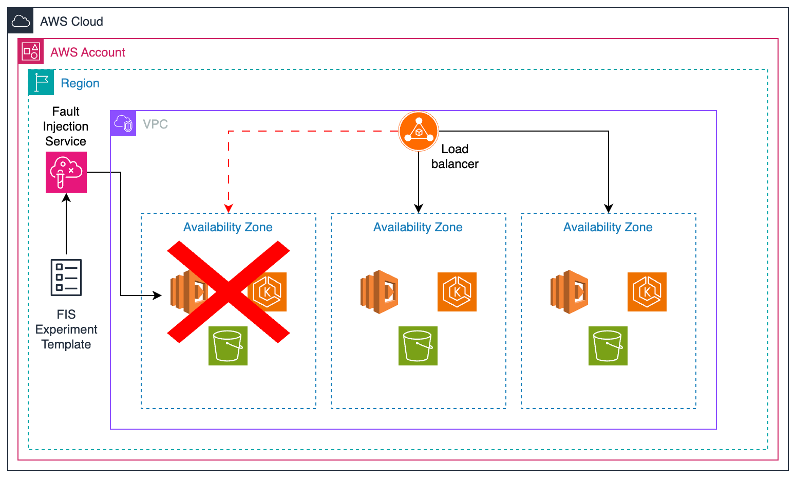
Figure 1- Honeycomb’s example architecture to simulate an AZ failure
This large-scale experiment yielded impressive results: the system maintained robust resilience with query processing continuing almost uninterrupted, and automated failover mechanisms performing as designed.
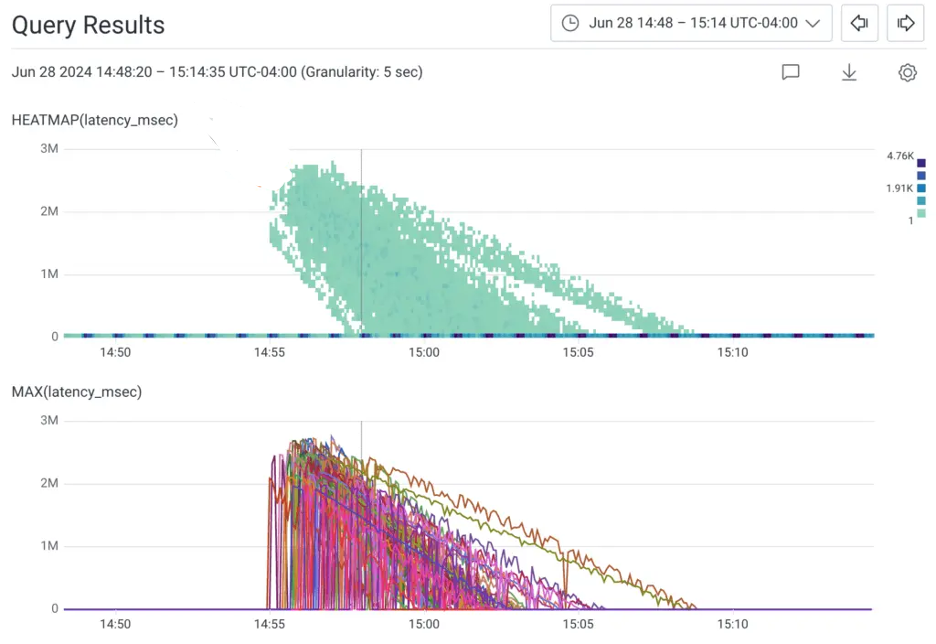
Figure 2- Honeycomb query results showing multiple service partitions rebuilding redundancy with a subsequent reduction in latency
This successful execution validated the Honeycomb team’s disaster recovery procedures and identified key areas for infrastructure optimization. AWS FIS then served as the chaos engineering engine, actively injecting failure scenarios to stress-test the environment. Together, AWS Countdown and FIS proved FIS’s value as an effective tool for both targeted development testing and large-scale production experiments.
The Impact and Learnings
The post-experiment cleanup process was efficiently managed over three hours, encompassing system state verification, data consistency confirmation, and documentation of key learnings.
- Resilience Metrics: Honeycomb’s FIS experiments demonstrated and validated their system resilience and the effectiveness of AWS Fault Injection Service (FIS). The system maintained 99.99% query success rates with only minimal latency increases of 150ms during the failure period. This matters because engineers need fast, reliable tools to stay focused when debugging complex production issues. During an outage, a slow or unreliable observability tool only makes things worse — adding frustration instead of helping resolve the problem quickly.
- Controlled Failure Injection: FIS proved its worth as an enterprise-scale chaos engineering tool, successfully orchestrating over 50 distinct failure injections across their architecture while maintaining precise control and detailed telemetry.
- Validation of Internal Systems: Honeycomb was also able to identify optimizations during this experiment. One such issue identified was with their internal metrics pipeline, which showed increased latency to populate metrics. The team quickly identified this and enhanced their monitoring systems to resolve it.
- Improvements to FIS Service: The Honeycomb team also identified 3 key features — particularly with AWS Lambda functions, multi-region handling, and Amazon CloudWatch integrations — to improve the FIS service and provided feedback to the FIS product teams.
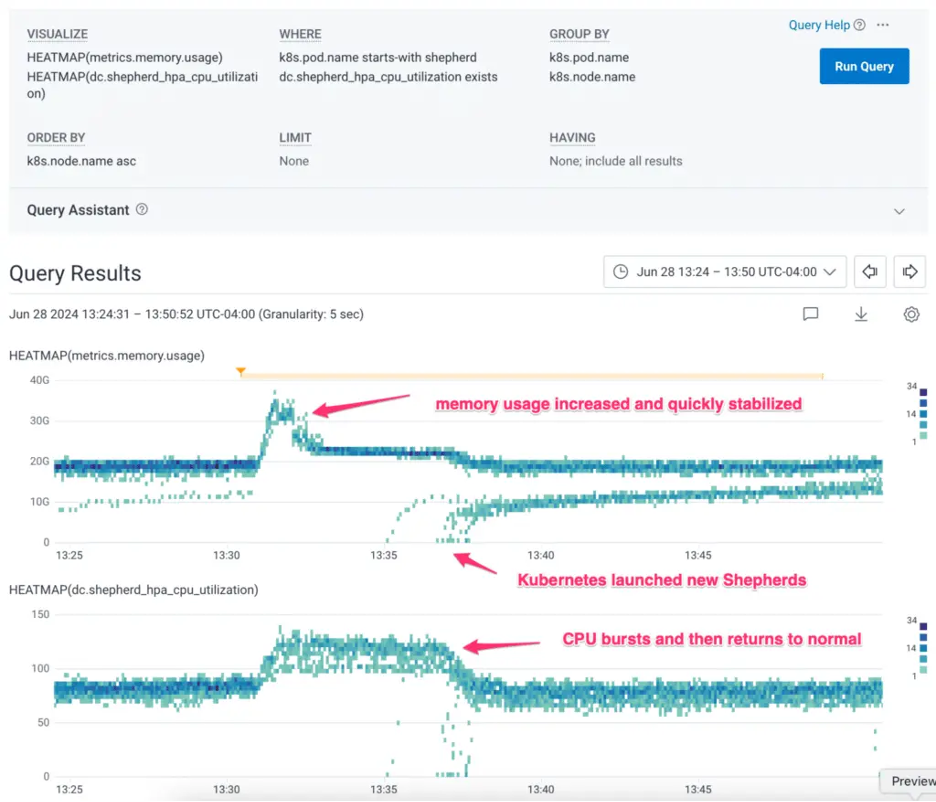
Figure 3- Honeycomb query showing system was stable and could continue operating indefinitely with loss of 1 AZ
“AWS Fault Injection Service (FIS) transformed our approach from theoretical disaster planning to real-world validation. Using FIS, we were able to deliberately terminate one-third of our production infrastructure and confirm that we maintained a 99.99% query success rate, showing our architecture was ready to safely handle a real-world disaster. FIS gave us the precision to conduct large-scale chaos experiments safely in production while seamlessly integrating with our existing AWS infrastructure. I would recommend FIS to any engineering team looking for an efficient approach to crafting a truly resilient system.”
— Emily Nakashima, Honeycomb SVP of Engineering
These results validated Honeycomb’s architectural decisions and also established a practical framework for conducting large-scale chaos experiments in production environments.
Conclusion
By choosing FIS, Honeycomb was able to conduct a realistic, large-scale chaos engineering experiment that closely mimicked potential real-world failures, thereby enhancing their system’s resilience and their team’s ability to respond to critical incidents. This exercise not only strengthened Honeycomb’s high availability guarantees but also showcased the power of controlled chaos in uncovering and addressing potential system vulnerabilities.
Learn More
To learn more about AWS Fault Injection Service and resilience best practices, please refer to: