AWS Storage Blog
Accelerating Amazon S3 Batch Operations at scale with on-demand manifest generation
Modern enterprises routinely manage billions of objects across their cloud storage environments, needing efficient bulk operations for disaster recovery, compliance management, data transfer, and cost optimization. Performing these operations manually or through custom scripts becomes impractical at scale, often creating operational bottlenecks when time-sensitive actions are necessary. Organizations frequently need to identify and process specific subsets of their data based on criteria such as age, size, or type—a challenge that grows exponentially with data volume. When responding to critical situations such as system restoration or compliance audits, the ability to quickly locate and process relevant objects becomes essential, yet traditional approaches may need hours or days of preparation before actual processing can begin.
Amazon S3 Batch Operations addresses these challenges by enabling organizations to run a single operation on up to 20 billion objects with a single request. Whether you need to copy or replicate data, restore archived content, apply retention policies, manage object tags, compute checksums, update access controls, or transition objects between storage classes, S3 Batch Operations eliminates the complexity of custom development while providing enterprise-scale processing capabilities. Traditionally, S3 Batch Operations needs a manifest file listing target objects, which is typically generated through Amazon S3 Inventory reports or manually created CSV files. Although S3 Inventory provides comprehensive object metadata for scheduled operations supported, the initial report can take up to 48 hours. This is often too long for urgent operational needs. To address this, Amazon S3 offers the manifest generator feature through both the AWS Command Line Interface (AWS CLI)/SDKs and S3 console. Customers can use this capability to create and run batch jobs immediately by dynamically generating manifests based on specified filters, eliminating the inventory report waiting period.
In this post, we demonstrate how to use the S3 Batch Operations manifest generator to perform on-demand, targeted operations across your S3 objects without waiting for inventory reports or manually creating manifest files. We demonstrate how to use both the AWS CLI and S3 console with specific filters to selectively process objects based on criteria such as storage class, object size, creation date, or key name patterns. You can implement these techniques to bypass inventory report generation wait time and launch S3 batch jobs with dynamic filtering as soon as operational needs arise. This approach transforms hours of waiting into immediate action, streamlines disaster recovery procedures, and provides granular control over exactly which objects are processed. Whether you’re restoring archived objects during a recovery scenario, implementing object locks for compliance, selectively replicating data, or applying tags for lifecycle management, these approaches can help you manage your storage resources more efficiently and meet time-sensitive operational requirements.
Understanding S3 Batch Operations with the manifest generator
The S3 Batch Operations manifest generator is a powerful feature that enables you to create batch jobs on demand without pre-generating a manifest file. This approach offers several advantages:
- Immediate execution: Create and run batch operations without waiting for inventory reports or manually created CSV files listing S3 objects.
- Dynamic filtering: Target specific objects based on various filters.
- Simplified workflow: Eliminate the need for intermediate steps such as inventory configuration and report querying.
Common use cases and implementation examples
In this section we explore several real-world scenarios where the S3 Batch Operations manifest generator can provide significant value by leveraging its capabilities through the s3control create-job method using AWS CLI and the AWS Management Console:
Option 1: AWS CLI
Set up AWS CLI following the instructions from the User Guide. When the AWS CLI setup is complete, you can run AWS CLI commands from your local machine or AWS CloudShell.
Scenario 1: Size and prefix based filtering for bucket-to-bucket copy operations
When you need to perform time sensitive copy operations between buckets, the manifest generator provides powerful filtering capabilities. Objects to be copied can be up to 5 GB in size when using S3 Batch Operations Copy. Using the ObjectSizeLessThanBytes, MatchAnyPrefix filters, you can identify and process only objects below specific size thresholds, enabling appropriate handling of objects based on their dimensions. This is particularly valuable when dealing with objects less than 5 GB for standard copy operations, allowing you to efficiently route objects to the appropriate copy mechanism.
aws s3control create-job \
--region <region> \
--account-id 123456789012 \
--operation '{"S3PutObjectCopy": {"TargetResource": "arn:aws:s3:::destination-bucket","MetadataDirective": "COPY","RequesterPays": false, "StorageClass": "STANDARD"}}' \
--manifest-generator '{"S3JobManifestGenerator": {"ExpectedBucketOwner": "123456789012","SourceBucket": "arn:aws:s3:::source-bucket","ManifestOutputLocation": {"ExpectedManifestBucketOwner": "123456789012", "Bucket": "arn:aws:s3:::manifest-bucket","ManifestPrefix": "manifests/copy-job", "ManifestEncryption": {"SSES3": {}},"ManifestFormat": "S3InventoryReport_CSV_20211130"}, "Filter": {"ObjectSizeLessThanBytes": 5368709120, "KeyNameConstraint": {"MatchAnyPrefix": ["expense/"]}}, "EnableManifestOutput": true}}' \
--priority 1 \
--role-arn "arn:aws:iam::123456789012:role/batch-operations-role" \
--description "Size and prefix filtered copy job" \
--report '{"Bucket":"arn:aws:s3:::report-bucket","Prefix":"reports/copy-job","Format":"Report_CSV_20180820","Enabled":true,"ReportScope":"AllTasks"}'
For larger objects (>5 GB), you can invoke an AWS Lambda function to handle the copy operation.
Scenario 2: On-demand S3 Batch Replication
When adding a new bucket to an existing replication configuration or modifying replication rules, you can use the manifest generator to selectively replicate specific objects that meet defined criteria. In this example, only objects from the prefix 2024/may-24/ in Standard storage tier would be picked for replication.
aws s3control create-job \
--region <region> \
--account-id 123456789012 \
--operation '{"S3ReplicateObject": {}}' \
--manifest-generator '{"S3JobManifestGenerator": {"ExpectedBucketOwner": "123456789012","SourceBucket": "arn:aws:s3:::source-bucket","ManifestOutputLocation": {"ExpectedManifestBucketOwner": "123456789012", "Bucket": "arn:aws:s3:::inventory-bucket","ManifestPrefix": "source-data", "ManifestEncryption": {"SSEKMS": {"KeyId": "arn:aws:kms:us-east-1:123456789012:key/dummy-key-id"}},"ManifestFormat": "S3InventoryReport_CSV_20211130"}, "Filter": {"EligibleForReplication": true,"KeyNameConstraint": {"MatchAnyPrefix": ["2024/may-24/"]},"MatchAnyStorageClass": ["STANDARD"]},"EnableManifestOutput": true}}' \
--priority 10 \
--role-arn "arn:aws:iam::123456789012:role/service-role/s3-replication-role" \
--description "Selective replication of May 2024 data" \
--report '{"Bucket":"arn:aws:s3:::report-bucket","Prefix":"replication-reports","Format":"Report_CSV_20180820","Enabled":true,"ReportScope":"AllTasks"}'
To further process the batch replication for failed objects, you can use the other filter ObjectReplicationStatuses as Failed and reattempt the replication. The following command demonstrates the scenario:
aws s3control create-job \
--region <region> \
--account-id 123456789012 \
--operation '{"S3ReplicateObject": {}}' \
--manifest-generator '{"S3JobManifestGenerator": {"ExpectedBucketOwner": "123456789012","SourceBucket": "arn:aws:s3:::source-bucket","ManifestOutputLocation": {"ExpectedManifestBucketOwner": "123456789012", "Bucket": "arn:aws:s3:::manifest-bucket","ManifestPrefix": "manifests/replication-job", "ManifestEncryption": {"SSES3": {}},"ManifestFormat": "S3InventoryReport_CSV_20211130"}, "Filter": {"EligibleForReplication": true, "ObjectReplicationStatuses": ["FAILED"]},"EnableManifestOutput": true}}' \
--priority 1 \
--role-arn "arn:aws:iam::123456789012:role/replication-role" \
--description "Failed replication recovery job" \
--report '{"Bucket":"arn:aws:s3:::report-bucket","Prefix":"reports/replication-job","Format":"Report_CSV_20180820","Enabled":true,"ReportScope":"AllTasks"}'
This approach is particularly valuable for disaster recovery scenarios where you need to quickly replicate specific data.
Scenario 3: Restoring objects from archival storage
During disaster recovery, you may need to restore objects from S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage classes. Using the manifest generator, you can identify and restore only the objects in specific storage classes:
aws s3control create-job \
--region <region> \
--account-id 123456789012 \
--operation '{"S3InitiateRestoreObject": {"ExpirationInDays": 10,"GlacierJobTier": "BULK"}}' \
--manifest-generator '{"S3JobManifestGenerator": {"ExpectedBucketOwner": "123456789012","SourceBucket": "arn:aws:s3:::archive-bucket","ManifestOutputLocation": {"ExpectedManifestBucketOwner": "123456789012", "Bucket": "arn:aws:s3:::manifest-bucket","ManifestPrefix": "manifests/restore-job", "ManifestEncryption": {"SSES3": {}},"ManifestFormat": "S3InventoryReport_CSV_20211130"}, "Filter": {"MatchAnyStorageClass": ["GLACIER"]},"EnableManifestOutput": true}}' \
--priority 1 \
--role-arn "arn:aws:iam::123456789012:role/restore-role" \
--description "Glacier restore job" \
--report '{"Bucket":"arn:aws:s3:::report-bucket","Prefix":"reports/restore-job","Format":"Report_CSV_20180820","Enabled":true,"ReportScope":"AllTasks"}'
Scenario 4: Implementing object locks for compliance
Amazon S3 Object Lock offers unique flexibility in cloud object storage WORM capabilities. You can set retention periods for individual objects and apply default retention settings across entire S3 buckets. When you need to apply object lock configurations to items uploaded within specific time windows, S3 Batch Operations manifest generator provides a solution. Using its CreatedBefore and CreatedAfter parameters, you can filter and select objects based on their upload timestamps, streamlining the process of applying time-specific retention policies. To protect objects created within a specific time window against deletion, you can apply object locks using date-based filters:
aws s3control create-job \
--region <region> \
--account-id 123456789012 \
--operation '{"S3PutObjectRetention": {"Retention": {"RetainUntilDate": "2025-06-30T00:00:00Z","Mode": "COMPLIANCE"}}}' \
--manifest-generator '{"S3JobManifestGenerator": {"ExpectedBucketOwner": "123456789012","SourceBucket": "arn:aws:s3:::compliance-bucket","ManifestOutputLocation": {"ExpectedManifestBucketOwner": "123456789012", "Bucket": "arn:aws:s3:::manifest-bucket","ManifestPrefix": "manifests/lock-job", "ManifestEncryption": {"SSES3": {}},"ManifestFormat": "S3InventoryReport_CSV_20211130"}, "Filter": {"CreatedBefore": "2022-06-10", "CreatedAfter": "2021-06-12"},"EnableManifestOutput": true}}' \
--priority 1 \
--role-arn "arn:aws:iam::123456789012:role/compliance-role" \
--description "Date-based object lock job" \
--report '{"Bucket":"arn:aws:s3:::report-bucket","Prefix":"reports/lock-job","Format":"Report_CSV_20180820","Enabled":true,"ReportScope":"AllTasks"}'
Scenario 5: Selective tagging for lifecycle management
For organizations that store various file types and need to apply different lifecycle policies based on file type, the manifest generator can tag objects based on file extensions:
aws s3control create-job \
--region <region> \
--account-id 123456789012 \
--operation '{"S3PutObjectTagging": { "TagSet": [{"Key":"media-type", "Value":"image"}] }}' \
--manifest-generator '{"S3JobManifestGenerator": {"ExpectedBucketOwner": "123456789012","SourceBucket": "arn:aws:s3:::media-bucket","ManifestOutputLocation": {"ExpectedManifestBucketOwner": "123456789012", "Bucket": "arn:aws:s3:::manifest-bucket","ManifestPrefix": "manifests/tagging-job", "ManifestEncryption": {"SSES3": {}},"ManifestFormat": "S3InventoryReport_CSV_20211130"}, "Filter": {"KeyNameConstraint":{"MatchAnySuffix":["jpg"]}},"EnableManifestOutput": true}}' \
--priority 1 \
--role-arn "arn:aws:iam::123456789012:role/tagging-role" \
--description "Image file tagging job" \
--report '{"Bucket":"arn:aws:s3:::report-bucket","Prefix":"reports/tagging-job","Format":"Report_CSV_20180820","Enabled":true,"ReportScope":"AllTasks"}'
Option 2: Amazon S3 console
Along with the AWS CLI approach, you can now use the manifest generator directly through the console. You can use the user-friendly interface to create S3 Batch Operations jobs without waiting for inventory reports. In this section we walk through the process for few operations (copy, restore, object lock retention, tagging):
Size and prefix based filtering for bucket-to-bucket copy operations
- Sign in to the console and navigate to S3.
- In the left navigation pane, choose Batch Operations.
- Choose Create job.
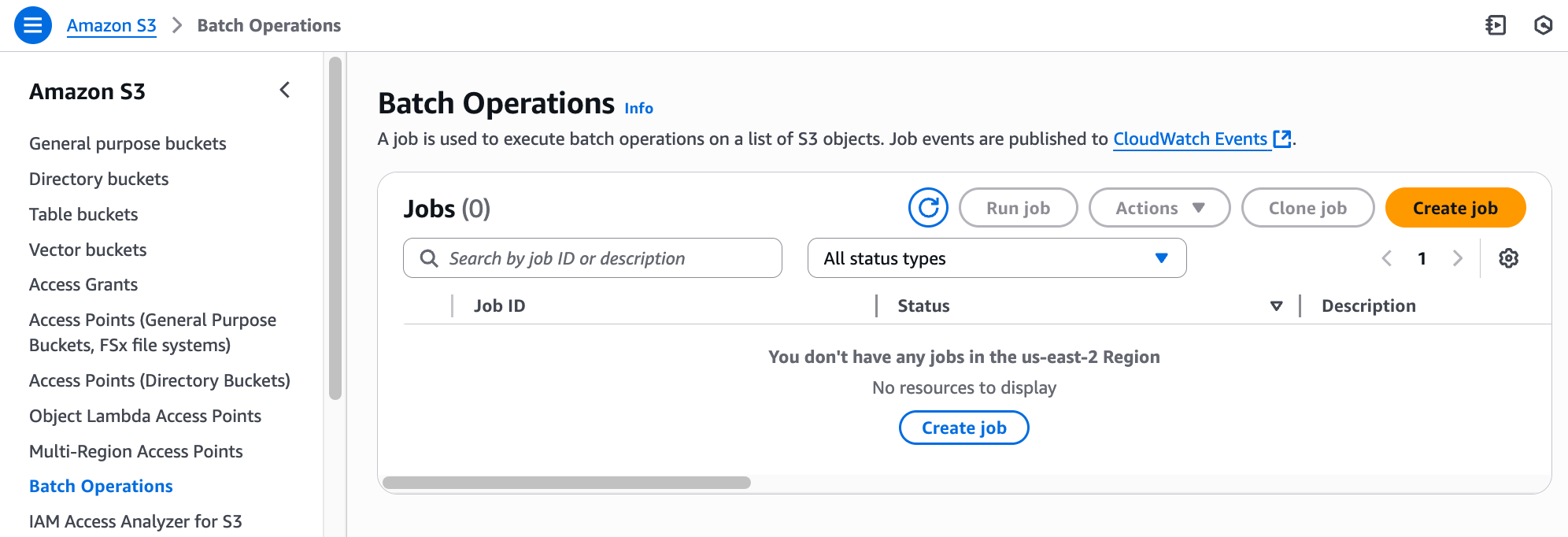
Step 1: Choose AWS Region and scope
- Choose your desired AWS Region (for example US East (N. Virginia)).
- Under Scope, choose Generate an object list by specifying filters.
- For Source bucket, enter or browse to your source bucket (for example s3://my-s3-bucket).
- Under Object filters, enter your desired prefix pattern to target specific objects.
- Choose Next.
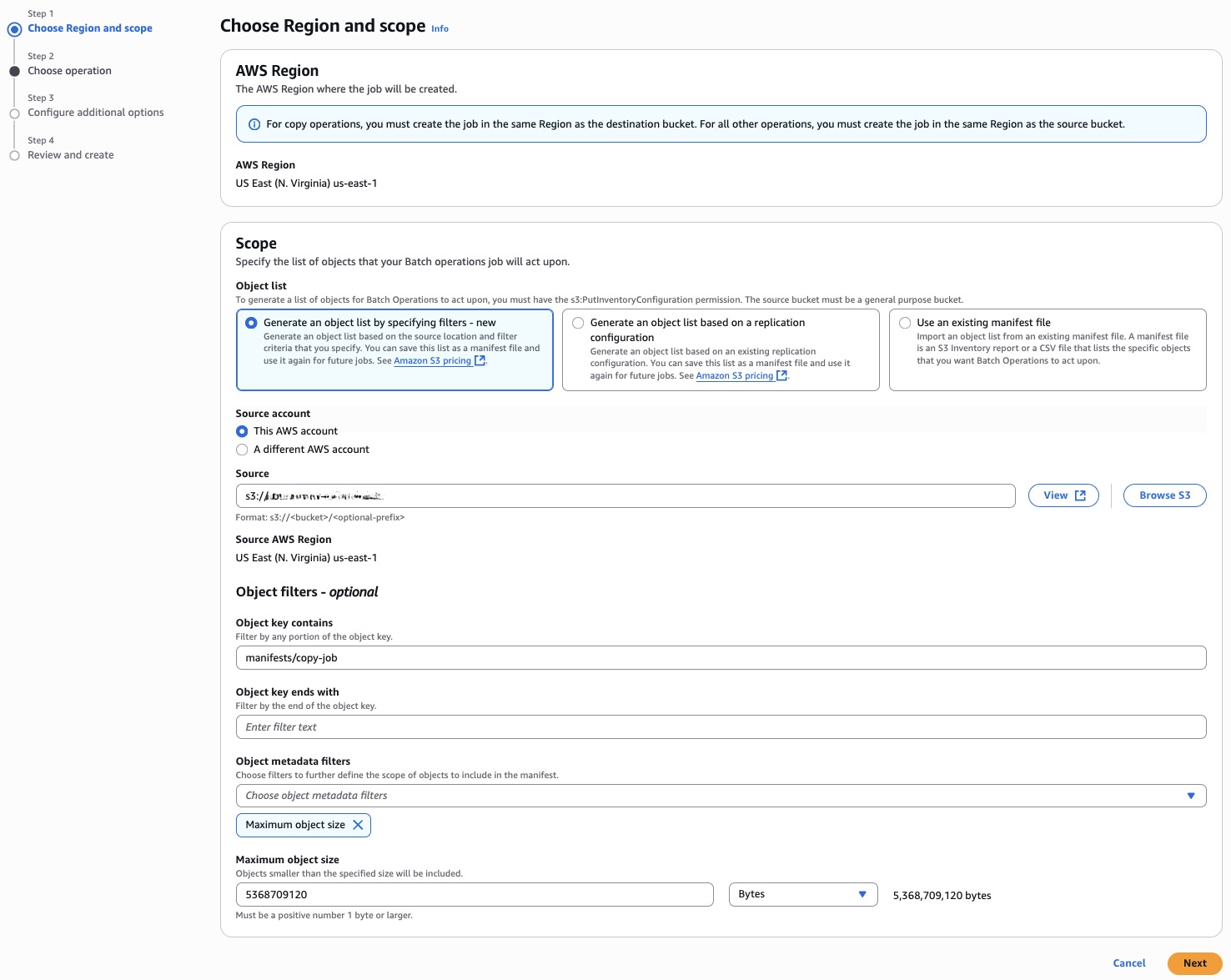
Step 2: Choose operation
- Choose your desired operation type, in this case Copy.
- For Copy destination, specify your target bucket.
- You have two configuration options:
- Use API default settings: Choose this for operations with default parameters.
- Specify settings: Choose this for customized operations, allowing you to configure:
- Storage class (for example Standard)
- Encryption settings
- Checksum algorithm options (for example “Copy existing checksum algorithms”)
- Object tags
- Metadata
- Choose Next.
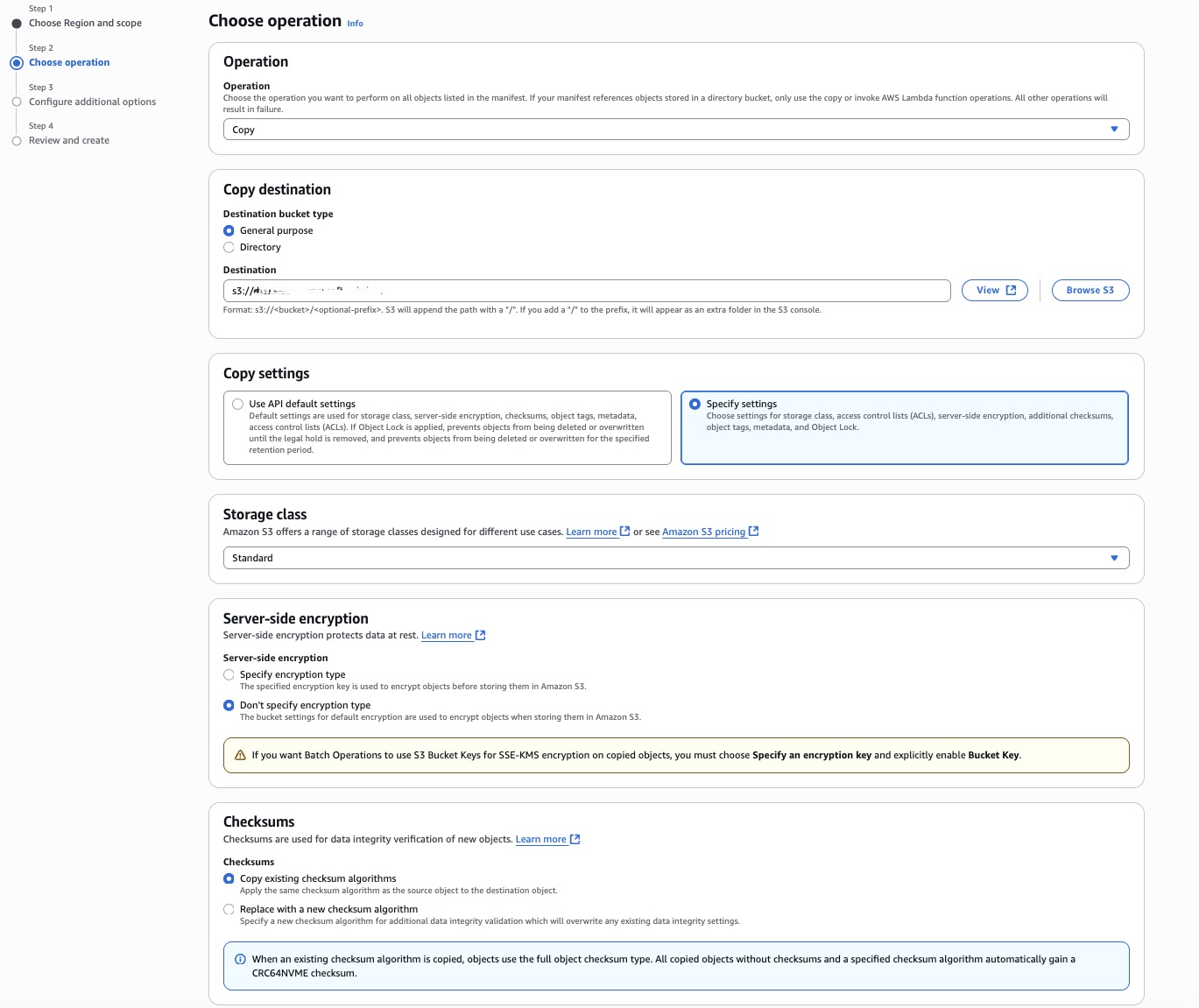
Choose default settings if you don’t need customization in API settings.
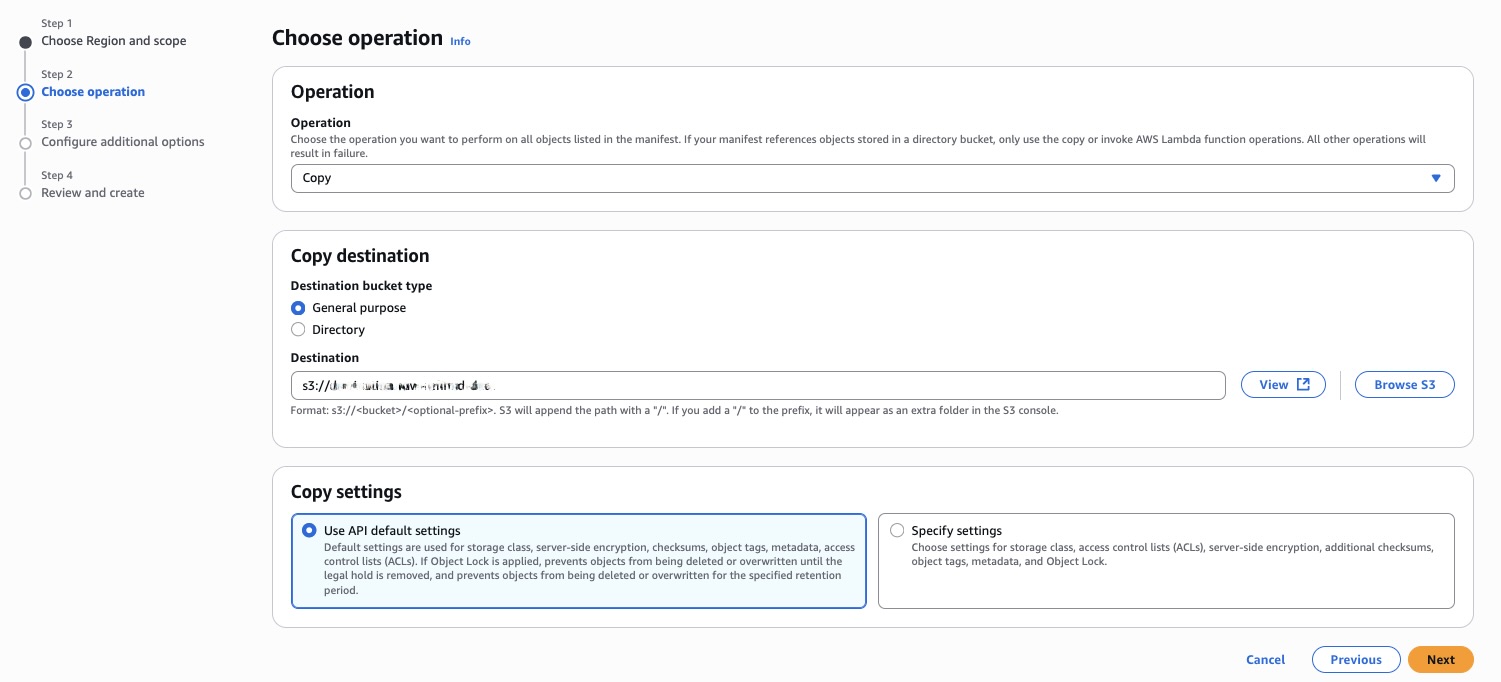
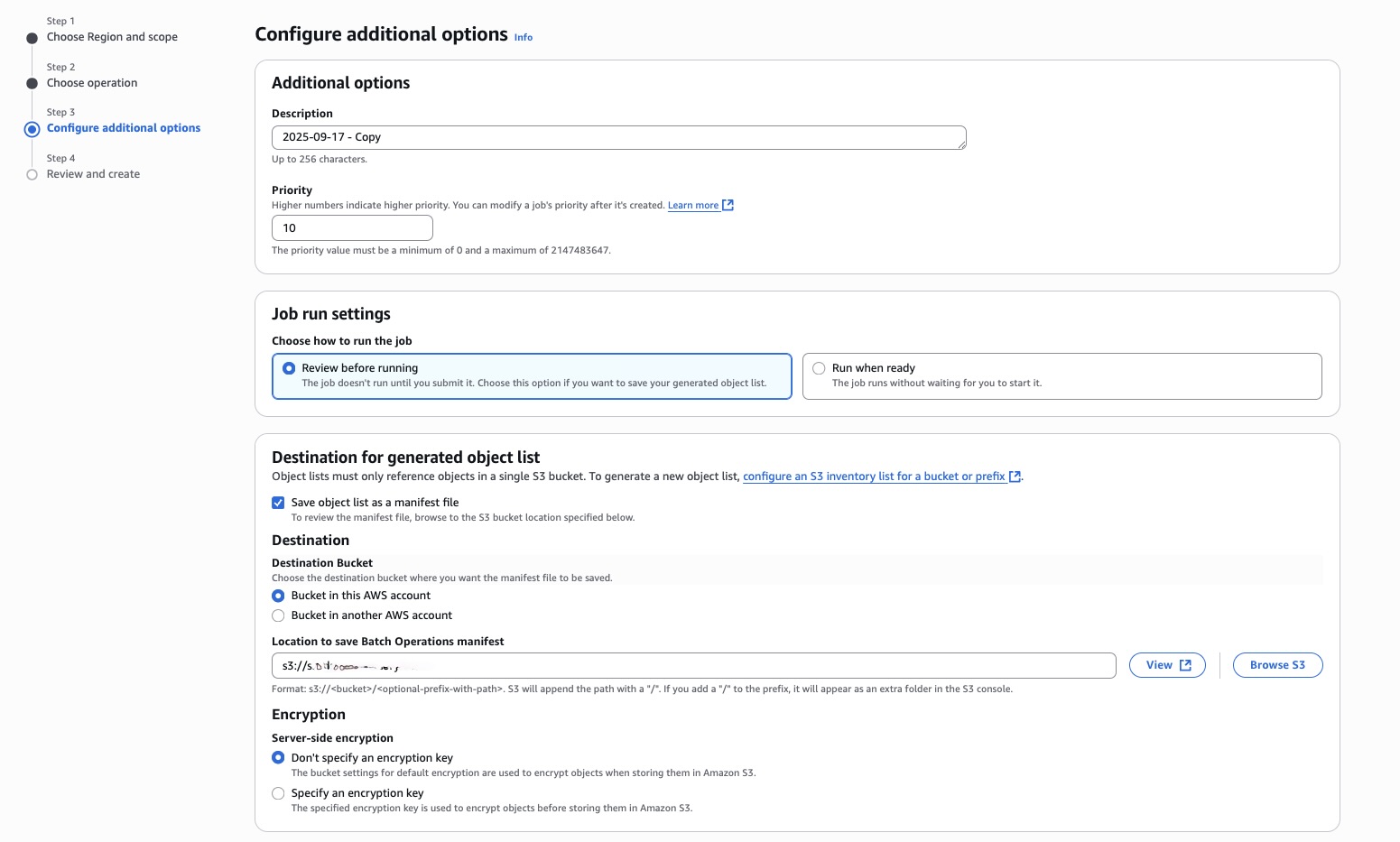
Step 3: Configure additional options
- Enter a descriptive Job description (for example “2025-09-27 – Copy”).
- Set a Priority level (1–10, where higher numbers indicate higher priority).
- Choose a Job run setting:
- Review before running if you want to verify job details before execution
- Run when ready to execute immediately after creation
- Under Destination for generated object list, specify where to save the generated manifest file (for example s3://manifest-bucket-name).
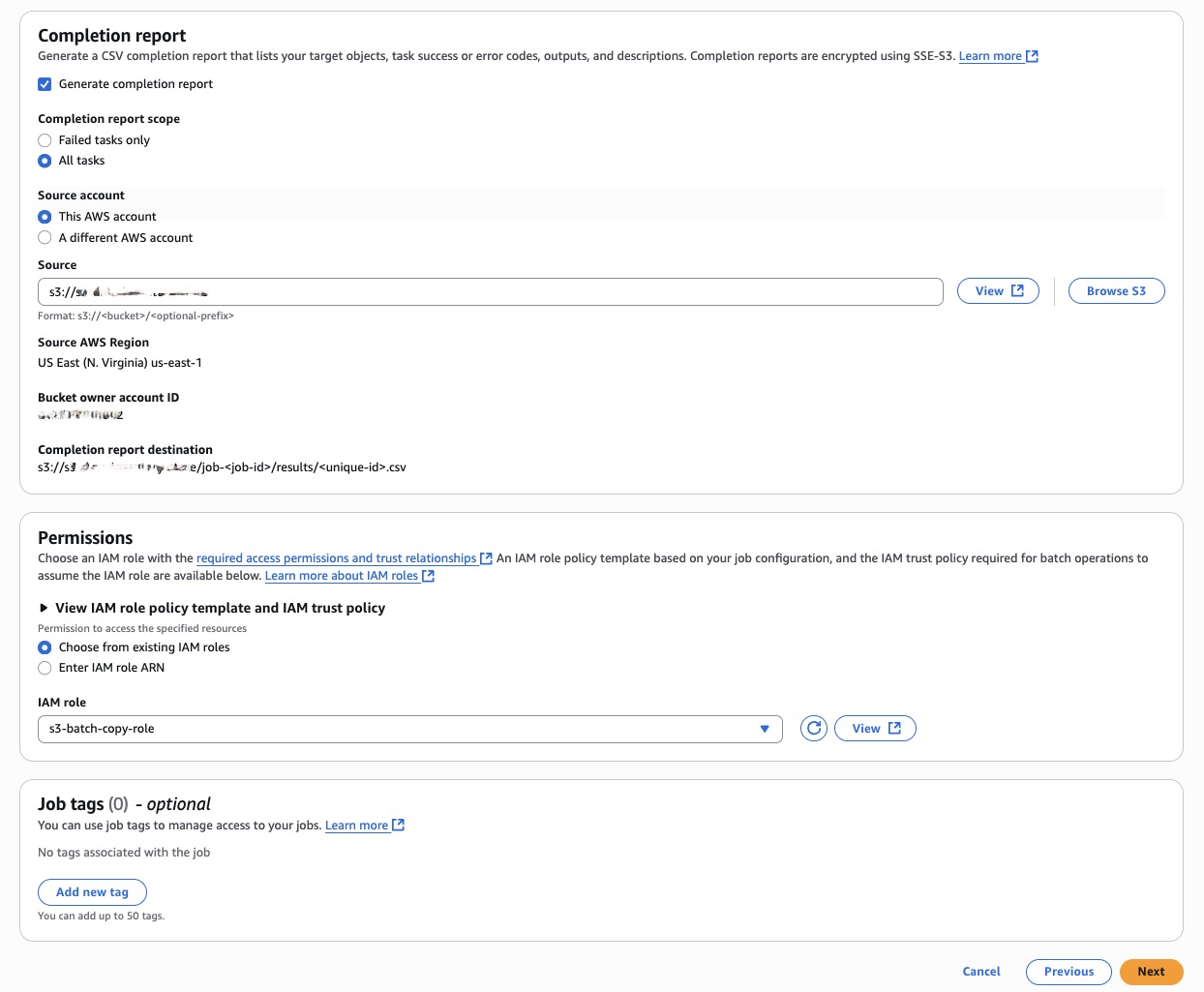
- For Completion report, choose whether to generate a report and its scope:
- Failed tasks only for troubleshooting
- All tasks for comprehensive reporting
- Specify the Report destination (for example s3://bath-job-result-bucket/job-<job-id>/results/<unique-id>.csv).
- Choose an existing IAM role with appropriate permissions or create a new one.
- Optionally, add tags to help organize and track your batch jobs.
- Choose Next.
Configure Completion report, Permissions and Job tags.
Step 4: Review and create
- Review all of your job configuration details.
- Choose Create job to submit your job configuration.
- If you chose “Review before running,” then your job is prepared but won’t execute automatically.
- To execute the job, choose it from the jobs list and choose Run job.
Similarly, for other operations as explained for the Copy operation, all of the steps would remain same except Step 2, and you can set up the batch operation over the console with manifest generator.
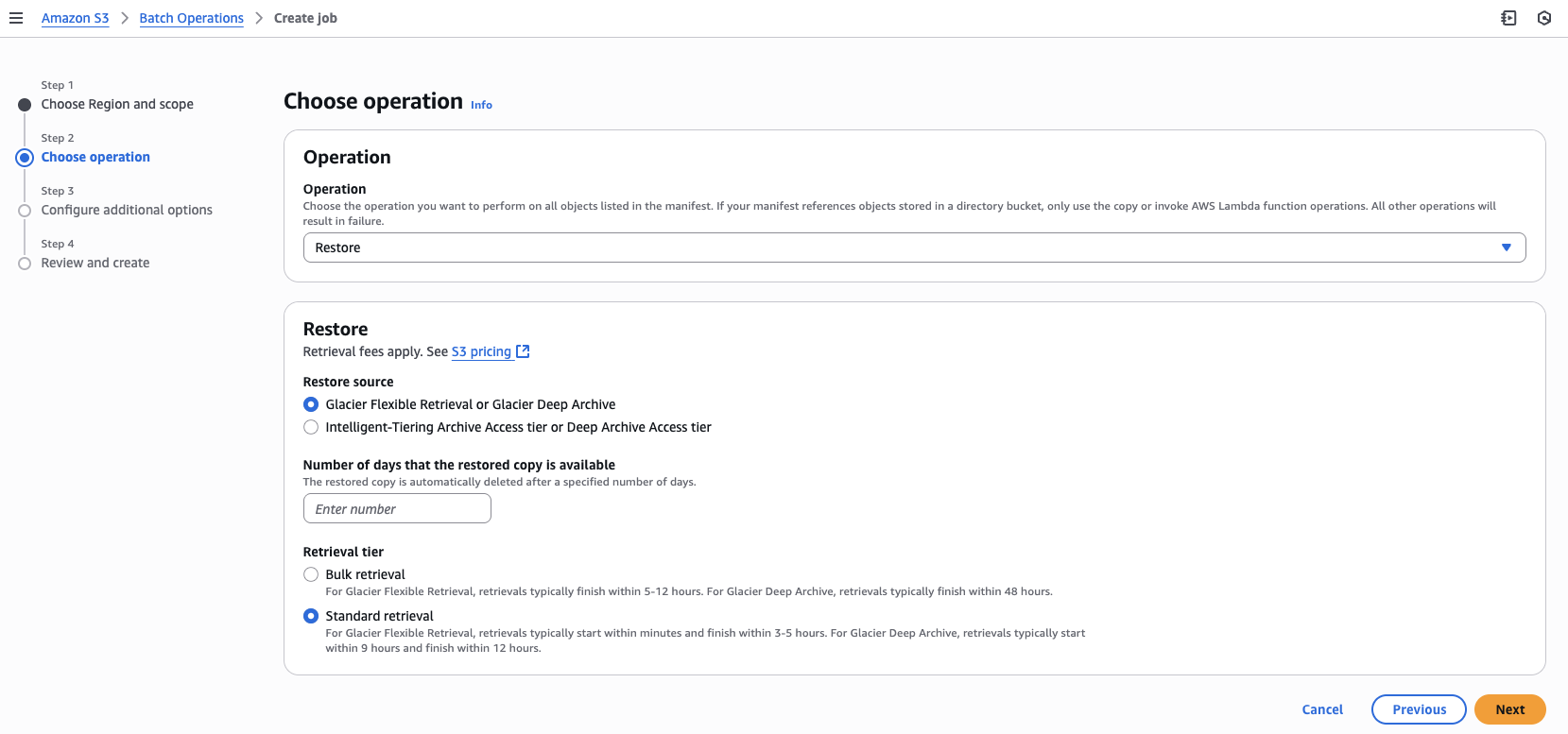
Restore
You can restore all of the objects filtered through manifest generator. Steps 1, 3, and 4 would remain the same as described in the preceding section for the Copy operation.
Step 2: Choose operation
- Choose your desired operation type, in this case Restore.
- Choose Restore resource from two options:
- Glacier Flexible Retrieval or Glacier Deep Archive
- Intelligent-Tiering Archive Access tier or Deep Archive Access tier
- If you chose Glacier Flexible Retrieval or Glacier Deep Archive, then enter Number of days that the restored copy is available.
- Choose Retrieval tier:
- Bulk retrieval
- Standard retrieval
- Choose Next.
Object Lock retention
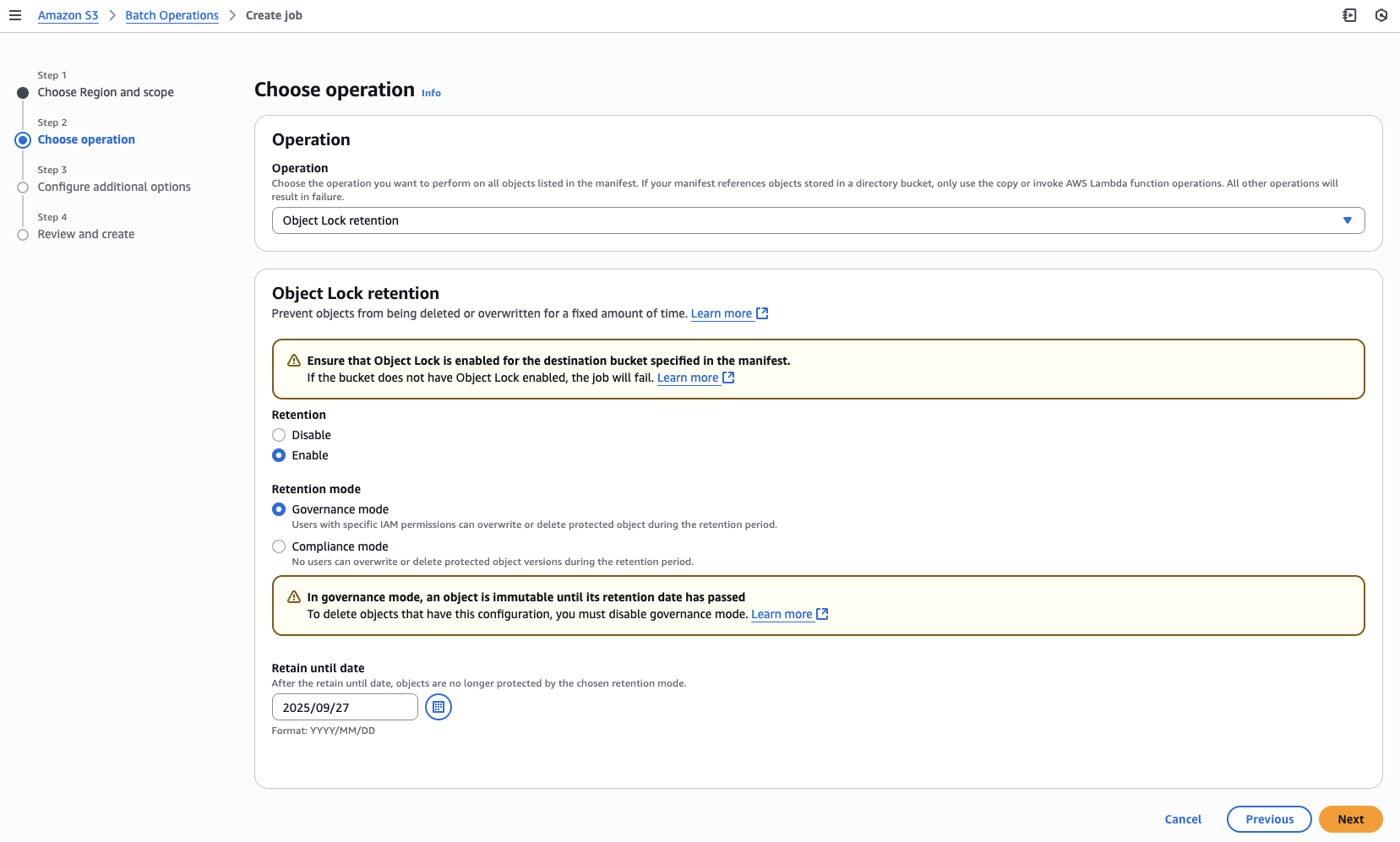
You can also perform data protection operations on the objects list prepared through manifest generator. Steps 1, 3, and 4 would remain the same as described in the preceding section for the Copy operation.
Step 2: Choose operation
- Choose your desired operation type, in this case Object Lock retention.
- Choose Retention, whether to Enable or Disable.
- If you chose Enable, then choose the Retention mode:
- Governance mode
- Compliance mode
- Specify Retain until date for retaining the object
- Choose Next.
Tagging
You can replace or delete all object tags through batch operations with manifest generator. Steps 1, 3, and 4 would remain the same as described in the preceding section for the Copy operation.
Step 2: Choose operation
- Choose your desired operation type, in this case Replace all object tags.
- Provide a Key-Value pair to replace the tag value with the provide for all the objects in the scope of manifest generator.
- Choose Next.
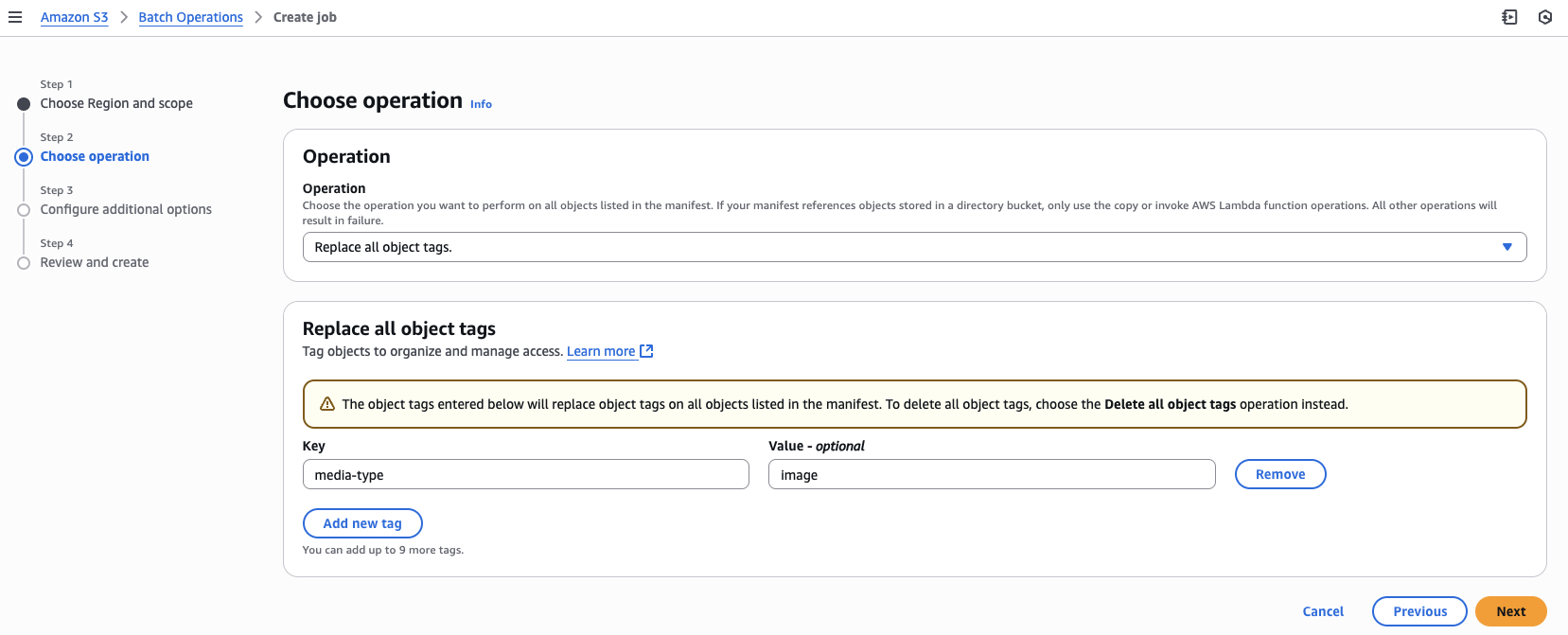
This console-based approach provides the same powerful filtering capabilities as the AWS CLI method but with a more intuitive, visual interface.
Best practices and considerations
When using the S3 Batch Operations manifest generator, keep these best practices in mind:
- IAM permissions: Make sure that your AWS Identity and Access Management (IAM) role has appropriate permissions for both the manifest generator and the specific batch operation you’re performing.
- Filter optimization: Use the most specific filters possible to minimize the number of objects scanned and processed.
- Job monitoring: Enable completion reports to identify objects processed (succeeded/failed) after batch job completion.
- Cost management: S3 Batch Operations incurs charges based on the number of objects processed. Using targeted filters can help control costs. Refer to the S3 pricing page.
- Version compatibility: The JSON format generated by AWS CLI may change between versions. When upgrading AWS CLI, verify the format of your JSON files.
- S3 object version: S3 Batch Operations manifest generator only works for the latest object versions. In the case of batch replication, it picks the older version of objects to meet the filter criteria.
- Object count limits: S3 Batch Operations jobs by default can process up to 4 billion objects for all operations. Specifically copy, object tagging, object lock, invoking a Lambda function, and batch replication jobs can support up to 20 billion objects.
- Manifest generation: S3 Batch Operations does not support cross-Region manifest generation. Refer to the S3 Batch Operations job documentation.
Conclusion
The S3 Batch Operations manifest generator provides a powerful solution for performing immediate, targeted operations across your S3 objects without waiting for inventory reports or generating a custom manifest file. You can use this feature through the AWS CLI/SDKs or AWS Management Console to perform S3 Batch Operations on demand, and you would not need to wait for an inventory report.
Whether you’re implementing disaster recovery procedures, managing compliance requirements, or optimizing storage costs, the ability to quickly identify and process specific objects at scale is invaluable. The examples provided in this post demonstrate how to use the manifest generator for common scenarios, but the flexibility of the filtering options allows for many more use cases. We’ve walked through multiple practical implementations, from size-based filtering for efficient copy operations to storage class targeting for urgent restoration of archived data. We’ve also explored how to leverage date-based filters for compliance-driven object lock operations and how to use key name constraints to selectively tag objects based on file extensions. Each example showcases the manifest generator’s ability to transform complex, multi-step workflows into streamlined, on-demand operations.
You can incorporate these techniques into your operational workflows to manage your S3 resources more efficiently and meet your time-sensitive requirements with confidence.