AWS Storage Blog
Tag: AWS Lambda

Simplify compliance-driven Amazon S3 data movement with multi-criteria filtering
Organizations routinely need to move a subset of their stored data from one location to another, such as a compliance audit that requires all PDFs from a specific quarter, a company reorganization that splits one tenant’s records into an isolated bucket, or a regulatory mandate that demands financial documents older than 7 years be archived […]
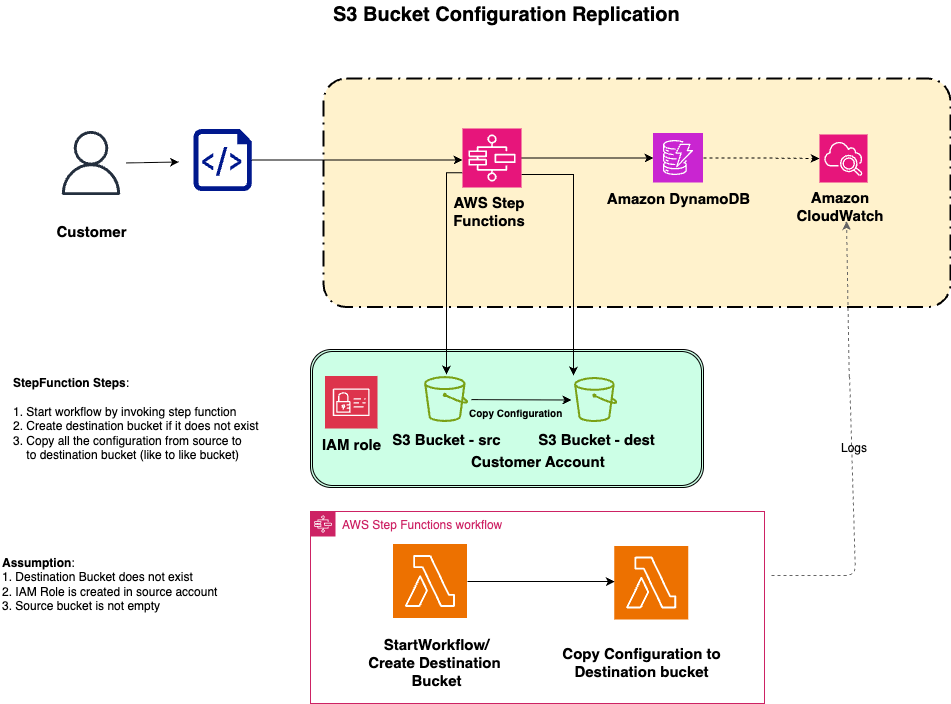
Replicate Amazon S3 bucket configurations across AWS Regions with AWS Step Functions
Many organizations operate thousands of Amazon S3 buckets in a single AWS Region, each with its own configuration accumulated over the years. Some were created manually in the AWS Management Console and others by scripts that are no longer actively maintained, provisioned by different business units with their own policies, lifecycle rules, encryption, and tags. […]

Implement single-exchange tokens for short-lived Amazon S3 presigned URLs with Terraform
Organizations across industries use signed URLs to grant temporary, credential-less access to private resources such as receipts, medical or financial records, legal files, or confidential reports. However, signed URLs can be reused by anyone until they expire, creating security risks if a URL is shared or inadvertently disclosed. This risk can be mitigated by vending […]

Migrate to Amazon S3 account regional namespaces
Since its launch in 2006, Amazon S3 has used a global namespace where bucket names must be unique across all AWS accounts and AWS Regions. This design has served customers well at scale, but organizations managing multiple accounts and environments often encounter naming collisions. When a bucket is deleted, its name returns to the global […]

Bridge legacy and modern applications with Amazon S3 Access Points for Amazon FSx
Organizations rely on file storage accessed from traditional, file-based, applications while simultaneously wanting to build modern, cloud-native applications and services that access the same underlying data. Consequently, many cloud-native apps are built to work with Amazon S3. Amazon Web Services (AWS) recently introduced a new capability, S3 Access Points for Amazon FSx which solves challenges […]
Automatically decompress files in Amazon S3 using AWS Step Functions
Every day, AWS customers process millions of compressed files in Amazon S3, from small ZIP archives to multi-gigabyte datasets. While decompressing a single file is straightforward, processing thousands of files efficiently requires complex orchestration, error handling, and infrastructure management. Consider this scenario: Your organization receives over 10,000 compressed files daily from partners, ranging from 5 […]

Accelerating Amazon S3 Batch Operations at scale with on-demand manifest generation
Modern enterprises routinely manage billions of objects across their cloud storage environments, needing efficient bulk operations for disaster recovery, compliance management, data transfer, and cost optimization. Performing these operations manually or through custom scripts becomes impractical at scale, often creating operational bottlenecks when time-sensitive actions are necessary. Organizations frequently need to identify and process specific […]

Boost testing confidence with automated Amazon RDS data replication from production to non-production environment
Automated testing in a pre-production environment is crucial for verifying the reliability and stability of software releases in any organization. However, for many applications, writing and executing these tests necessitates the use of data from production system. This production data is valuable for testing and development because it represents real-world scenarios, usage patterns, and edge […]
Enforcing organization-wide Amazon S3 bucket-tagging policies
In today’s complex cloud environments, maintaining consistent resource tagging is a critical challenge faced by organizations of all sizes. Proper resource tagging is essential for cost allocation, security compliance, operational management, and maintaining governance at scale. However, enforcing tagging standards across distributed teams and numerous resources can be difficult, especially when dealing with rapid deployment […]

KKCompany saves 93% on data storage by migrating music streaming services to AWS
KKCompany Technologies (KKCompany) is an AI multimedia technology group based in Taipei, with offices across Asia. Its flagship music streaming platform, KKBOX, serves over 12 million users worldwide. As its user base and music catalog rapidly grew, KKCompany faced significant challenges with its on-premises storage infrastructure. These included costly hardware scaling, constrained rack space, and […]