AWS Storage Blog
From on premises to AWS: Hybrid-cloud architecture for network file shares
Enterprises often operate on-premises file servers or Network Attached Storage (NAS) to provide a centralized solution for storing and accessing user and enterprise data, such as workflow backups. Most organizations acknowledge that having a centralized solution has its practical advantages, but it also comes with inherent challenges of setting up and maintaining storage infrastructure at scale. Accurate capacity planning can be challenging. In addition, hardware supporting storage solutions can incur expensive replacement cycles every three-to-five years.
Many enterprises with dedicated on-premises file servers or NAS are looking for more flexible, cost-effective, and robust long-term cloud solutions. With the AWS Cloud pay-as-you-go storage model, enterprises gain the flexibility of no longer needing to invest in expensive hardware and software on premises. Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance at low cost. AWS designed S3 for 99.999999999% (11 9’s) of durability, and the service provides robust capabilities to manage access, cost, replication, versioning, and data protection.
So, customers naturally ask, “How do I use Amazon S3 with on-premises applications that don’t natively work with an object store, but instead need file-based SMB or NFS access?”
We address this question with a two-phase hybrid approach, where we migrate data and make it accessible to on-premises applications. In the migration phase, we use AWS DataSync to do an initial bulk migration of existing data from on-premises NAS and file servers to Amazon S3. In the access phase, we make the data stored in Amazon S3 easily accessible as an SMB or NFS file share on premises, using File Gateway. In the following diagram, you can see a high-level overview of the proposed two-phase architecture.
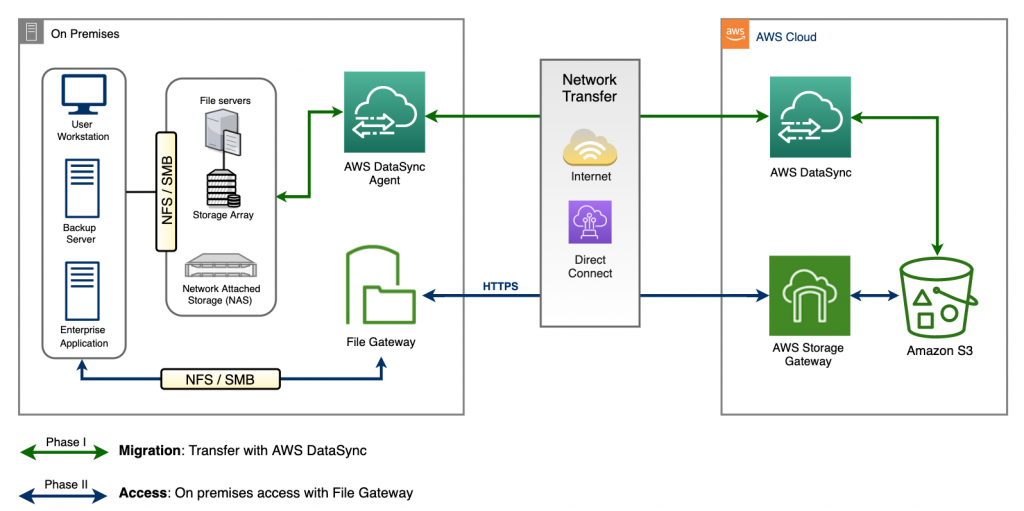
Figure 1: Two-phase hybrid-cloud storage solution using AWS DataSync, File Gateway, and Amazon S3
Migration phase
In the migration phase, our goal is to quickly, efficiently, and cost-effectively migrate existing data from on-premises storage to Amazon S3. The key to data migration for this particular solution is AWS DataSync. AWS DataSync is an online data transfer service that simplifies and automates copying large amounts of data between on-premises storage and AWS Storage services, in addition to copying data between AWS Storage services in the cloud. When copying between on-premises storage and AWS Storage services, DataSync can transfer data over the internet or via AWS Direct Connect, at a rate up to 10 Gbps. DataSync connects to existing storage systems and data sources with standard storage protocols (NFS, SMB, S3), and uses a purpose-built network protocol and scale-out architecture to accelerate transfer to and from AWS. With the flat, per-gigabyte pricing of DataSync, you pay only for data copied, with no minimum commitments or upfront fees. Additionally, you save on script development and management costs, and avoid the need for costly commercial transfer tools.
During migration, DataSync stores metadata about files and folders such as creation date, modification date, user ID, group ID, and POSIX permissions in Amazon S3. This metadata is stored as user data on the Amazon S3 object and is compatible with File Gateway. When copying from SMB-based storage, DataSync stores default POSIX metadata in Amazon S3.
To begin the migration, we start off with deploying a DataSync Agent on premises to read data from the local file servers or NAS systems. With the data available in the Amazon S3 bucket, you can also access it from any Amazon S3 API-enabled application or other AWS services.
Access phase
In the access phase, we have two goals. First, make the files and folders, which were transferred during the migration phase to the Amazon S3 bucket, accessible from on premises with the required SMB or NFS-based access. Second, provide access to Amazon S3’s virtually unlimited cloud storage from on premises. We achieve both of these goals by providing access to Amazon S3 using File Gateway. File Gateway provides a simple solution for presenting one or more Amazon S3 buckets or prefixes as a mountable NFS or SMB file share to clients on premises. File Gateway provides a low latency cache for frequently accessed data from Amazon S3, and fundamentally extends AWS Cloud storage to on premises. It requires no changes to your existing applications and reduces physical infrastructure cost, complexity, and management overhead. All data in transit to and from Amazon S3 is encrypted using TLS.
Using the File Gateway virtual machine (VM) or AWS Storage Gateway Hardware Appliance on premises, you access the data in Amazon S3 for both reads and writes with local caching. For gateway VMs deployed on premises, you have a choice of the type of VM host — VMware ESXi Hypervisor, Microsoft Hyper-V, or Linux Kernel-based VM (KVM). As you identify a host to deploy a gateway software appliance, you must also allocate sufficient cache storage for the gateway VM. AWS Storage Gateway deployed in a VMware environment on premises has a high availability option to protect storage workloads against hardware, hypervisor, or network failures. Through a set of health checks integrated with VMware vSphere High Availability (vSphere HA), the Storage Gateway automatically recovers from most service interruptions in under 60 seconds with no data loss. This protects storage workloads against hardware, hypervisor, or network failures; or software errors such as connection timeouts and file share or volume unavailability. This eliminates the need for custom scripts for health checks, auto‑restart, and alerting. For more information, refer to the documentation on using VMware vSphere High Availability with AWS Storage Gateway.
Once the File Gateway is deployed and activated on premises, it can be configured with one or more file shares. Each share (or mount point) on the gateway is associated with a single Amazon S3 bucket or prefix. The contents of the bucket or prefix are available as files and folders in the file share. For more information on using S3 prefixes, see the guides on creating an NFS file share or creating an SMB file share. Writing an individual file to a file share on the File Gateway creates a corresponding object in the associated Amazon S3 bucket. The shares are accessible by clients using NFS v3 or v4.1, or via SMB v2 or v3 protocols. File Gateway allows you to create the desired SMB or NFS-based file share from S3 buckets with existing content and permissions. In addition, users can optionally also define custom default UNIX permissions for all existing Amazon S3 objects within the bucket when a file share is created in the File Gateway.
When a file is written to the File Gateway, it first commits the write to the local cache. At this point, the write is acknowledged immediately to the SMB or NFS-based client. After the write cache is populated, the file is uploaded to the associated Amazon S3 bucket asynchronously. When you deploy File Gateway, you must specify how much disk space you want to allocate for local cache. To improve the performance and provide low latency access to large working datasets, you can easily scale the File Gateway’s local cache storage up to 64 TB. The increased scale of the local cache enables you to keep more data on premises, minimizing data access and restore times. Additionally, you can now buffer more data in the local cache when there is limited network bandwidth available to upload data to Amazon S3.

Figure 2: Caching with File Gateway on premises
Another architectural pattern that customers leverage is having multiple File Gateways associated with a single Amazon S3 bucket. You can have multiple readers on a single bucket by configuring a file share as read-only, and allowing multiple gateways to read objects from the same bucket. In such scenarios, it is important to ensure that the multiple local gateway caches are refreshed periodically to keep them in sync with the S3 bucket. This is important in situations where users are writing to the S3 bucket associated with File Gateways directly without writing through the gateway’s file shares. Keeping the gateway’s cache constantly refreshed and synced with the bucket has historically been challenging. Customers would write scripts, jobs, or AWS Lambda functions to systematically invoke the RefreshCache API.
In 2020, we launched the automated cache refresh feature for File Gateways. This feature is based on the ‘duration since last access’ timer for each share. For example, say if the automated cache refresh is set to 30 minutes. This implies that contents in the local cache reflect the contents in the Amazon S3 bucket no later than 30 minutes ago, and the first access after the 30 minute period will refresh the contents of that folder. All access requests made within the 30 minute period will see the same content. Once the duration of the timer expires, the next access results in a new refresh of the folder. Having multiple File Gateway writers for one Amazon S3 bucket is more challenging. If you are interested in this design pattern, refer to the File Gateway questions on the AWS Storage Gateway FAQ page.
End-to-end monitoring
Monitoring, reporting, and troubleshooting of AWS DataSync are simplified using Amazon CloudWatch. You can use the DataSync Console or AWS CLI to monitor the status of data transfer via DataSync. Using Amazon CloudWatch Metrics, you can see the number of files and amount of data that has been copied. You can also enable logging of individual files to CloudWatch Logs. This enables you to identify files, objects, and folders transferred and review the results of the content integrity verification performed by DataSync.
From File Gateway, you can use Amazon CloudWatch Logs to get information about the health of the gateway. You can use subscription filters to automate the processing of the logs in real time. You can monitor the performance metrics and alarms for your gateway, which gives insight into storage, bandwidth, throughput, and latency. These metrics and alarms are accessible directly from CloudWatch, or by following links in the Storage Gateway console. In addition to File Gateway specific metrics, each file share has a set of associated metrics. You can access those metrics in CloudWatch using the File Share ID to uniquely identify them. SMB file shares in File Gateway can be configured to generate audit logs of client operations performed on all files and folders.
You can use CloudWatch Events or Amazon EventBridge to set rules for sending notifications or taking actions when the DataSync tasks go through various state changes. You can also set up notifications for various file operations in the gateway, including when a file is uploaded to Amazon S3 or when the gateway finishes refreshing the cache.
Conclusion
In this post, we explored a two-phase hybrid-cloud storage architecture to simplify storage infrastructure requirements for network file shares on premises. This hybrid architecture leverages AWS DataSync, Amazon S3, and File Gateway allowing you to build scalable, centralized file shares on premises.
At this point, you may be eager to build a Proof-of-Concept (PoC) to test and validate the solution shown in this blog. To get started easily, watch the following embedded video of a recent AWS Storage Virtual Workshop where we take you through a systematic tutorial of the proposed hybrid-cloud storage solution. The modules referred to in the video are accessible on the AWS DataSync migration GitHub page, equipping you with resources to build the solution in your own environment.
We hope this blog encourages you to try out the workshop, and helps you with using AWS DataSync and File Gateway for your next project. If you have any questions or comments, don’t hesitate to leave them in the comments section!