亚马逊AWS官方博客
使用混合云HPC场景加快计算机辅助工程工作负载运行速度
作者:Holger Gantikow, Atos Science + Computing Unit HPCaaS 首席架构师;Florian Heimgärtner,Atos Science + Computing Unit高级HPC顾问;Hakan Korkmaz,亚马逊云科技高级合作伙伴解决方案架构师;Torsten Bloth,亚马逊云科技高级HPC专家
校对作者:胡正光,亚马逊云科技解决方案架构师,15年IT行业经验,目前负责基于亚马逊云科技云计算方案架构的咨询和设计
作为汽车和生命科学公司的长期合作伙伴,Atos Science + Computing Unit 致力于为客户提供定制的需求驱动型高性能计算(HPC,High-Performance Computing)解决方案。这包括整合云资源以高效实现客户的性能和业务目标。
Atos Science + Computing 的客户受益于多年对领域的了解以及技术专长,尤其是在将资源转化为完全集成到客户的 HPC、计算机辅助工程(CAE,Computer-Aided Engineering)和数据分析 IT 环境中的解决方案方面。
在本博文中,我们介绍了两种混合 HPC 部署。这两种部署都透明地与控制现有本地 HPC 资源的传统工作负载管理器集成,二者的区别在于方法完全不同。
选择这些解决方案是为了尽可能地满足各自的要求,并在混合场景中充分利用可能的灵活性:
- 目标架构 A:此架构针对的是高度动态的环境,在此环境中,云端只处理偶尔的峰值负载,其他时间不需要资源处于活动状态。此方法依赖于 Amazon ParallelCluster,这是 Amazon 提供的一个 HPC 集群管理工具,支持自动和动态调配 HPC 资源。
- 目标架构 B:此架构是本地 HPC 环境的常用扩展。因此,它会在云中尽可能地再现客户环境的特征,尽量使整合透明。
Atos International 是 Amazon Advanced Tier 服务合作伙伴和托管云服务提供商(MSP,Managed Cloud Services Provider),该公司帮助客户实现数字化抱负,并坚信将人员、业务和技术结合起来便能取得进步的理念。
Atos Science + Computing Unit 提供了 IT 服务、解决方案和软件,以便在研究、开发和计算领域高效地利用复杂的计算机环境。其客户包括汽车、微电子、航空航天和制药行业的制造商和供应商,以及科研机构。
Atos Science + Computing 提供了高效、经济实用的弹性 IT 基础设施,帮助客户专注于其核心业务目标。
背景
如今,创新的开发过程依赖于高性能计算,并将它视为将构思转化为产品的一项关键技术。HPC 已逐渐从主要用于研究设施的专业工具演变为广泛使用的技术,扎根于商业环境中。
为了充分利用 HPC,许多研究机构和公司逐渐投资了大型计算集群,其中大部分都是在本地运行的。然而,这些设施处理偶尔出现的峰值负载的能力有限。
另一个挑战是计算资源需求的总体增加(例如,因额外的项目所致),因为额外集群资源的采购过程通常费时费力。
利用云资源,可以在混合场景中轻松访问其他资源,从而减轻这些限制。此外,可以通过云获得市场上的最新技术,而这些技术在本地设施中尚不可获得。这可能包括加速卡或最新一代处理器,它们可以减少计算所需的时间。
通过选择与现有工作负载有效匹配的实例类型(更多内核与速度更快的内核或使用速度更快的磁盘),可以缩短总计算时间。
对于工作流的各个阶段,也可以完全依赖最合适的实例类型,从而仅在使用它时付费。在本地设施中,通常无法获得在各种不同的系统之间进行选择的这种灵活性,因为部署的系统通常更加同质。
特别是对于时间比较关键的计算,可以选择从云的弹性中受益,将流程分布于更多的资源,并在非常短的时间内获得结果。
通过向队列中添加更多节点,组织可以减少释放计算资源的等待时间。但是,可能需要解决特定于应用程序扩展的许可限制。
目标架构 A:CFD 模拟中峰值负载的弹性支持
在成本效益方面,HPC 集群的最佳规模调整的目标是,在正常运行时间内永久性接近 100% 负载。不过,HPC 用户组(例如 CAE 研发部门)通常不会产生持续一致的 HPC 工作负载。
尽管作业队列在周末或非营业期间可能为空,但随着项目截止日期的临近,集群通常很快就会达到容量限制。拥挤的队列和模拟开始前的等待时间会令人沮丧并导致项目延迟。
管理高峰需求 – 当本地容量不够用时
要处理临时的峰值负载,混合云架构会是一个不错的替代硬件升级的方案,可以避免构建一个相对日常工作负载配置过高的集群。
本地部署系统的设计旨在能够轻松处理日常工作负载,但是当出现峰值负载时,云端的资源将自动激活,用于避免瓶颈和延迟。在处理完峰值负载后,云上的集群会进行调整,并关闭多余的云资源。
下面介绍的部署实现了这样一个动态的、具有成本效益的场景。公司内部的本地计算集群与 Amazon Web Services上运行的云集群互联。图 1 所示为设置概览。
弹性混合云架构的关键点
本地和云集群都使用 Slurm 工作负载管理器。Slurm 支持联合身份验证这一概念,允许将计算作业从本地透明地提交给远程 Slurm 集群。因此,无论作业是安排在本地集群中还是云端,HPC 用户都可以使用标准工具进行作业提交或状态监控。
云集群是使用 Amazon ParallelCluster 创建的,此 Amazon 支持的开源集群管理工具简化了云资源调配,并支持资源的自动扩展,而这是该架构的一个关键特性。
其他配置调整是使用安装后脚本实现的。例如,将云集群的 Slurm 控制器节点连接到本地 SlurmdBD 数据库守护进程,或分发身份验证密钥。
使用的 Amazon 服务
通过将作业输入数据推送到 Amazon Simple Storage Service(Amazon S3)存储桶来传输到云集群。使用 Amazon FSx for Lustre 将存储桶内容作为 Lustre 文件系统呈现给集群。要将作业输出数据传输回本地文件系统,需要使用第二个 Amazon S3 存储桶。
只要云集群处于空闲状态,Amazon 上需要保持开启状态并使用的唯一资源就是 Slurm 控制器节点。计算节点 Amazon Elastic Compute Cloud(Amazon EC2)实例是使用 Slurm 节能功能按需创建和终止的,该功能最初用于暂停和恢复物理计算节点。
依靠消息传递接口(MPI,Message Passing Interface)进行节点间通信的多节点作业将通过 Elastic Fabric Adapter(EFA)网络接口进行加速。这种高性能互联提供了可与 InfiniBand 媲美的性能,对于在 Amazon 上大规模运行 HPC 应用程序来说至关重要。
本地 HPC 集群通过 Amazon Site-to-Site VPN 连接到云集群的 Amazon Virtual Private Cloud(Amazon VPC)。
工作负载 + 按需许可证
此方案中运行的主要工作负载是 Simcenter Star-CCM+,它是一种常用的计算流体力学(CFD,Computational Fluid Dynamics)求解器。它由 Simcenter STAR-CCM+ Power On Demand(POD)许可。
此步骤解决了软件许可证的配置通常与本地硬件资源完全一致的问题。这意味着 ,当本地资源被充分利用时,云端集群就没有可用的许可证了。
POD 提供了按使用付费方案,在这里,通过访问软件供应商运营的云许可服务,将该方案用于 Amazon 上运行的资源。通过这种方式,云集群可以处理峰值工作负载,既不需要连接到本地许可证服务器,也不需要扩展许可证池。
为了简化应用程序部署,Atos 已预设基于 Singularity 容器引擎的容器化操作以及对 Amazon Elastic Container Registry(Amazon ECR)的选择性使用。
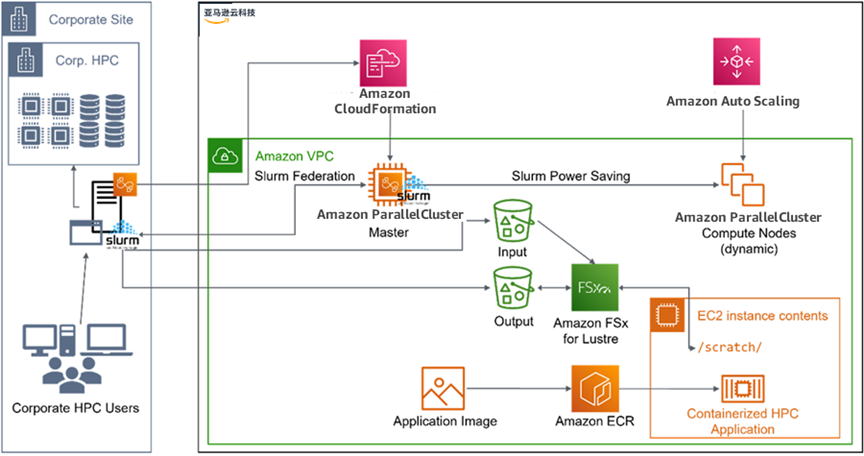
图 1 – 使用 Amazon ParallelCluster 的混合 CFD 模拟架构。
目标架构 B:通过云资源进行永久集群扩展
在这种方法中,云资源将充当本地计算集群的永久扩展,并且不断用于各种 CAE 应用程序,主要是 LS-Dyna 和 Abaqus。
考虑到这种架构的持续运行,一个关键特征是将云资源尽可能紧密地集成到本地环境中。因此,不同资源的操作任务是使用同一配置管理工具执行的,并且还可以从云端访问某些中央基础设施服务(例如,全公司范围的许可证服务器)。
永久混合云架构的关键点
云资源是通过模仿本地集群中使用的计算单元这一概念来构建的。计算单元代表一个部分独立的子集群,它由几个不同的元素组成:
- 网关:用于与单元外部的资源进行通信,例如许可证服务器和用于提供结果数据的传输服务器。
- 文件服务器:通过网络文件系统(NFS,Network File System)提供共享存储和 HPC 应用程序。
- 计算节点:通过不同的网络互联来传递不同类型的流量,如常规 TCP/IP 或 MPI。
使用的 Amazon 服务
文件服务器的特性集由 Amazon Cloud 存储服务 Amazon Elastic File System(Amazon EFS)提供,可根据需要动态增加和缩减。
Amazon EFS 为 HPC集群提供共享存储空间,并提供给传输节点,可通过这些节点在企业网络中的本地环境与云之间传输作业的输入和输出数据。
由于可以通过传输服务器进行访问,因此 Amazon EFS 位于单独的子网中,如图 2 所示。
客户环境和云 HPC 环境通过 Amazon Direct Connect 进行连接。通过仅允许与明确定义的端点进行通信,并通过 OpenVPN 点对点连接保护此链接,可以满足客户对传输中数据机密性的要求。
通过加密实现静态数据的机密性。因此,所有计算实例都配置了加密的磁盘,并且也将 Amazon EFS 配置为使用加密功能。
通过结合使用基于 Grid Engine 的工作负载管理器与自定义工作流引擎来执行工作负载管理和作业编排,自定义工作流引擎将客户自己的 HPC 资源和 Amazon 上的资源集中在一个位置。

图 2 – 由多个子集群组成的混合云 HPC 环境。
取得的成果
实施的不同解决方案让客户真正受益:
- 访问其他资源以增加其计算环境的容量。
- 透明地集成到现有工作流和整体环境中。
- 灵活地优化资源以最大程度地满足所需的工作负载。
- 可以直接关掉空闲资源(即用即付模式)。
- 满足客户的隐私和安全要求,尤其是传输中数据和静态数据。
- 业经验证的工作流与技术和资源相结合,可在云端实现一流的 HPC 环境。
小结
Atos Science + Computing Unit 实施的混合云 HPC 方法展示了此类解决方案的高度灵活性、适应能力和可扩展性。
目前面临的问题不再是云端高性能计算(HPC,High-Performance Computing)是否真的有效,而是哪种设置最适合工作负载以及应在多大程度上将它集成到现有环境中。例如,在本博文展示的示例中,云资源主要用作计算环境的扩展;在本地环境中再次进一步处理数据,考虑到技术上的可能性,并不一定需要这样做。
如今,从技术的角度来看,听不到反对将后期处理转移到云的声音了,只要它符合操作模式即可。
Atos 已支持客户将整个计算机辅助工程(CAE,Computer-Aided Engineering)工作站(包括具有许多内核、大量内存、快速本地存储和功能强大的显卡的桌面)迁移到 Amazon Cloud 中,以便在居家办公场景中尽最大所能提供灵活性。
通过应用 HPC 云支持技术(例如 Nimbix,现在属于 Atos),可以进一步提高灵活性,该技术通过 JARVICE 等软件来提供实现高级计算工作流的能力,同时为其他资源提供分流到公有云的选择。