亚马逊AWS官方博客
Amazon Nova Multimodal Embeddings:最先进的代理 RAG 和语义搜索嵌入模型
今天,我们推出 Amazon Nova Multimodal Embeddings,这是一款用于代理式检索增强生成 (RAG) 和语义搜索应用的先进多模态嵌入模型,现已在 Amazon Bedrock 中提供。这是首个通过单一模型支持文本、文档、图像、视频和音频的统一嵌入模型,能够以领先准确率实现跨模态检索。
嵌入模型将文本、视觉和音频输入转换为称为嵌入的数值表示。这些嵌入以 AI 系统可以比较、搜索和分析的方式捕获输入的含义,为语义搜索和 RAG 等使用案例提供支持。
各组织日益寻求解决方案,以从遍布文本、图像、文档、视频和音频内容的海量非结构化数据中获取洞察。例如,一个组织可能拥有产品图像、包含信息图和文本的宣传册,以及用户上传的视频片段。嵌入模型能够从非结构化数据中释放价值,但是传统模型通常专门处理一种内容类型。此限制迫使客户要么构建复杂的跨模态嵌入解决方案,要么将自身限制在专注于单一内容类型的使用案例。此问题同样适用于混合模态内容类型,例如包含交错文本和图像的文档,或包含视觉、音频和文本元素的视频,现有模型难以有效捕获其中的跨模态关系。
Nova Multimodal Embeddings 为文本、文档、图像、视频和音频支持统一的语义空间,适用于跨混合模态内容的跨模态搜索、使用参考图像进行搜索以及检索视觉文档等使用案例。
评估 Amazon Nova Multimodal Embeddings 性能
我们根据广泛的基准对该模型进行了评估,结果如下表所示,该模型开箱即用,准确度遥遥领先。
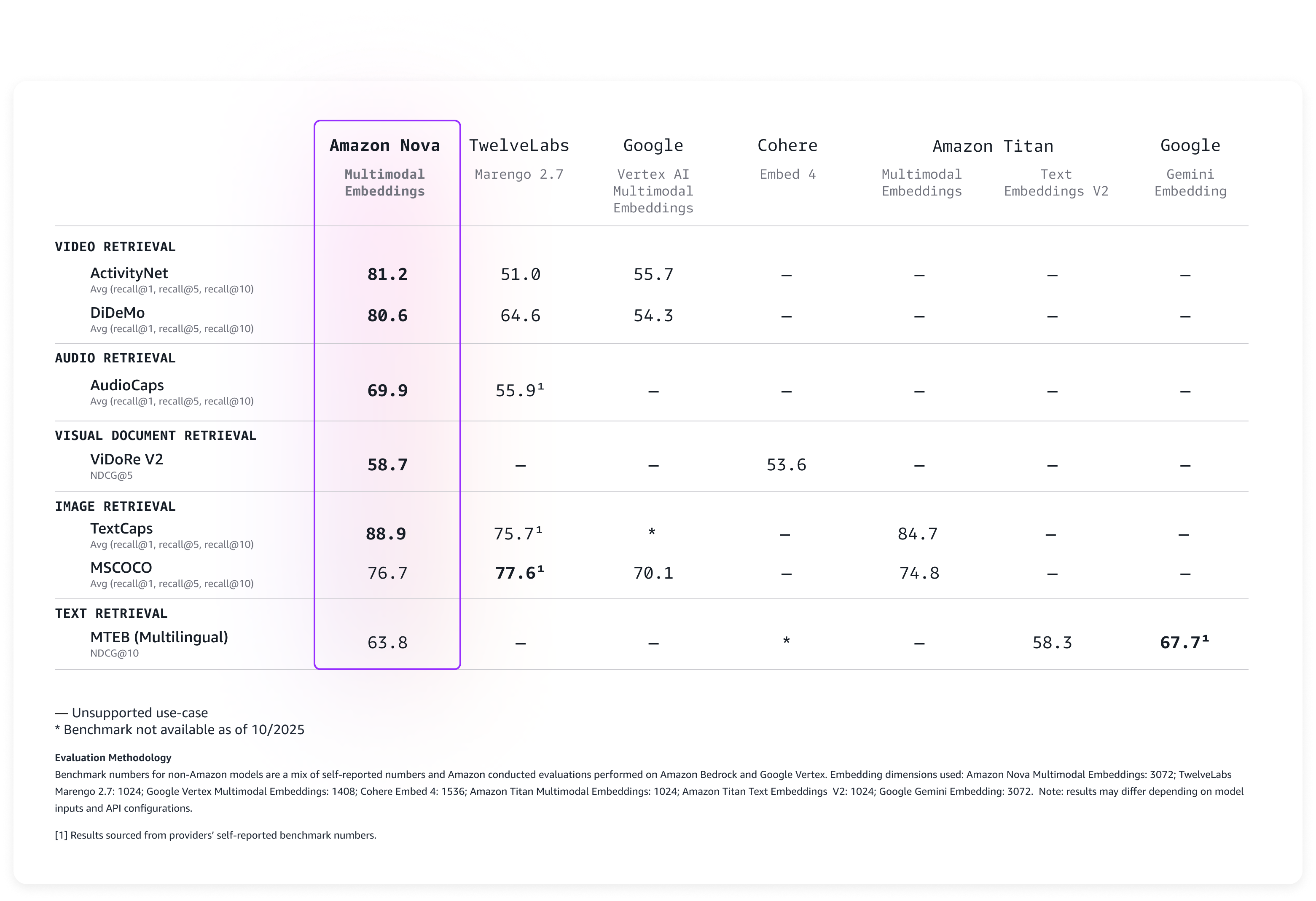
Nova Multimodal Embeddings 支持高达 8K 令牌的上下文长度、多达 200 种语言的文本,并通过同步和异步 API 接受输入。此外,它支持分段(也称为“分块”),可将长文本、视频或音频内容划分为可管理的片段,并为每个部分生成嵌入。最后,该模型提供四种输出嵌入维度,这些维度使用 Matryoshka Representation Learning (MRL) 进行训练,能够以最低的准确率变化实现低延迟端到端检索。
让我们看看这个新模型如何在实际中使用。
使用 Amazon Nova Multimodal Embeddings
Nova Multimodal Embeddings 启用遵循与 Amazon Bedrock 中其他模型相同的模式。该模型接受文本、文档、图像、视频或音频作为输入,并返回数值嵌入,您可将其用于语义搜索、相似性比较或 RAG。
以下是一个适用于 Python 的 Amazon SDK (Boto3) 的实际示例,展示了如何从不同内容类型创建嵌入并存储它们以供后续检索。为简便起见,我将使用 Amazon S3 Vectors(一种成本优化的存储,原生支持任意规模的向量存储和查询)来存储和搜索嵌入。
让我们从基础开始:将文本转换为嵌入。此示例展示了如何将简单的文本描述转换为捕获其语义含义的数值表示。以后可以将这些嵌入与文档、图像、视频或音频中的嵌入进行比较,以查找相关内容。
为使代码易于理解,我将一次展示脚本的一部分。完整脚本包含在本演练的末尾。
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# 初始化 Amazon Bedrock Runtime 客户端
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
print(f"Generating text embedding with {MODEL_ID} ...")
# 要嵌入的文本
text = "Amazon Nova is a multimodal foundation model"
# 创建嵌入
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 提取嵌入
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")现在,我们将使用与脚本同一文件夹中的 photo.jpg 文件,在同一嵌入空间中处理视觉内容。这展示了多模态的强大能力:Nova Multimodal Embeddings 能够将文本和视觉上下文捕获到单个嵌入中,从而提供对文档的增强理解。
Nova Multimodal Embeddings 可以生成针对其使用方式进行优化的嵌入。在为搜索或检索使用案例建立索引时,embeddingPurpose 可设置为 GENERIC_INDEX。对于查询步骤,embeddingPurpose 可根据要检索的项类型进行设置。例如当检索文档时,embeddingPurpose 可设置为 DOCUMENT_RETRIEVAL。
# 读取和编码映像
print(f"Generating image embedding with {MODEL_ID} ...")
with open("photo.jpg", "rb") as f:
image_bytes = base64.b64encode(f.read()).decode("utf-8")
# 创建嵌入
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "jpeg",
"source": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 提取嵌入
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")为了处理视频内容,我使用异步 API。这是对于编码为 Base64 后大于 25MB 的视频的要求。首先,我将本地视频上传到同一 AWS 区域的 S3 存储桶。
aws s3 cp presentation.mp4 s3://my-video-bucket/videos/此示例展示了如何从视频文件的视觉和音频组件中提取嵌入。分段特征将较长的视频分解为可管理的块,使得高效搜索数小时的内容变得可行。
# 初始化 Amazon S3 客户端
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URI
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
S3_EMBEDDING_DESTINATION_URI = "s3://my-embedding-destination-bucket/embeddings-output/"
# 为带音频的视频创建异步嵌入作业
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # Segment into 15-second chunks
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job started: {invocation_arn}")
# Poll until job completes
print("\nPolling for job completion...")
while True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(15)
# 检查作业是否成功完成
if status == "Completed":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"\nSuccess! Embeddings at: {output_s3_uri}")
# 解析 S3 URI 以获取存储桶和前缀
s3_uri_parts = output_s3_uri[5:].split("/", 1) # Remove "s3://" prefix
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED 模式输出到 embedding-audio-video.jsonl
# output_s3_uri 已经包含作业 ID,因此只需添加文档名即可
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Reading embeddings from: s3://{bucket}/{embeddings_key}")
# 读取和解析 JSONL 文件
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content = response['Body'].read().decode('utf-8')
embeddings = []
for line in content.strip().split('\n'):
if line:
embeddings.append(json.loads(line))
print(f"\nFound {len(embeddings)} video segments:")
for i, segment in enumerate(embeddings):
print(f" Segment {i}: {segment.get('startTime', 0):.1f}s - {segment.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(segment.get('embedding', []))}")
else:
print(f"\nJob failed: {job.get('failureMessage', 'Unknown error')}")生成嵌入式后,我们需要一个地方来有效地存储和搜索嵌入。此示例演示了使用 Amazon S3 Vectors 设置向量存储,它提供了大规模相似性搜索所需的基础设施。可以将其视为创建一个可搜索的索引,其中语义相似的内容自然地聚集在一起。当向索引添加嵌入时,我使用元数据来指定原始格式和正在索引的内容。
# 初始化 Amazon S3 Vectors 客户端
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# Configuration
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# 创建向量存储桶和索引(如果它们不存在)
try:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
try:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"\nGenerating embeddings for {len(texts)} texts...")
# 使用 Amazon Nova 为每个文本生成嵌入内容
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"text:{text[:50]}", # Unique identifier
"data": {"float32": embedding},
"metadata": {"type": "text", "content": text}
})
print(f" ✓ Generated embedding for: {text}")
# 在一次调用中将所有向量添加到存储中
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"\nSuccessfully added {len(vectors)} vectors to the store in one put_vectors call!")最后一个示例演示了通过单个查询搜索不同内容类型的能力,无论其来源于文本、图像、视频还是音频,都能找到最相似的内容。距离分数帮助您理解结果与原始查询的关联紧密程度。
# 要查询的文本
query_text = "foundation models"
print(f"\nGenerating embeddings for query '{query_text}' ...")
# 生成嵌入
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": query_text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Searching for similar embeddings...\n")
# 搜索前 5 个最相似的向量
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# 显示结果
print(f"Found {len(response['vectors'])} results:\n")
for i, result in enumerate(response["vectors"], 1):
print(f"{i}. {result['key']}")
print(f" Distance: {result['distance']:.4f}")
if result.get("metadata"):
print(f" Metadata: {result['metadata']}")
print()交叉模态搜索是多模态嵌入跨模态搜索是多模态嵌入的关键优势之一。通过跨模态搜索,您可以使用文本查询并找到相关映像。您还可以使用文本描述搜索视频,查找与特定主题相匹配的音频片段,或根据其视觉和文本内容查找文档。完整的脚本与之前的所有示例合并在一起,供您参考:
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# 初始化 Amazon Bedrock Runtime 客户端
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
print(f"Generating text embedding with {MODEL_ID} ...")
# 要嵌入的文本
text = "Amazon Nova is a multimodal foundation model"
# 创建嵌入
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 提取嵌入
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# 读取和编码映像
print(f"Generating image embedding with {MODEL_ID} ...")
with open("photo.jpg", "rb") as f:
image_bytes = base64.b64encode(f.read()).decode("utf-8")
# 创建嵌入
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "jpeg",
"source": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 提取嵌入
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# 初始化 Amazon S3 客户端
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URI
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
# Amazon S3 输出存储桶和位置
S3_EMBEDDING_DESTINATION_URI = "s3://my-video-bucket/embeddings-output/"
# 为带音频的视频创建异步嵌入作业
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # Segment into 15-second chunks
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job started: {invocation_arn}")
# Poll until job completes
print("\nPolling for job completion...")
while True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(15)
# 检查作业是否成功完成
if status == "Completed":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"\nSuccess! Embeddings at: {output_s3_uri}")
# 解析 S3 URI 以获取存储桶和前缀
s3_uri_parts = output_s3_uri[5:].split("/", 1) # Remove "s3://" prefix
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# AUDIO_VIDEO_COMBINED 模式输出到 embedding-audio-video.jsonl
# output_s3_uri 已经包含作业 ID,因此只需添加文档名即可
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Reading embeddings from: s3://{bucket}/{embeddings_key}")
# 读取和解析 JSONL 文件
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content = response['Body'].read().decode('utf-8')
embeddings = []
for line in content.strip().split('\n'):
if line:
embeddings.append(json.loads(line))
print(f"\nFound {len(embeddings)} video segments:")
for i, segment in enumerate(embeddings):
print(f" Segment {i}: {segment.get('startTime', 0):.1f}s - {segment.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(segment.get('embedding', []))}")
else:
print(f"\nJob failed: {job.get('failureMessage', 'Unknown error')}")
# 初始化 Amazon S3 Vectors 客户端
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# Configuration
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# 创建向量存储桶和索引(如果它们不存在)
try:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
try:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"\nGenerating embeddings for {len(texts)} texts...")
# 使用 Amazon Nova 为每个文本生成嵌入内容
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"text:{text[:50]}", # Unique identifier
"data": {"float32": embedding},
"metadata": {"type": "text", "content": text}
})
print(f" ✓ Generated embedding for: {text}")
# 在一次调用中将所有向量添加到存储中
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"\nSuccessfully added {len(vectors)} vectors to the store in one put_vectors call!")
# 要查询的文本
query_text = "foundation models"
print(f"\nGenerating embeddings for query '{query_text}' ...")
# 生成嵌入
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": query_text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Searching for similar embeddings...\n")
# 搜索前 5 个最相似的向量
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# 显示结果
print(f"Found {len(response['vectors'])} results:\n")
for i, result in enumerate(response["vectors"], 1):
print(f"{i}. {result['key']}")
print(f" Distance: {result['distance']:.4f}")
if result.get("metadata"):
print(f" Metadata: {result['metadata']}")
print()对于生产应用程序,嵌入可以存储在任何向量数据库中。Amazon OpenSearch Service 在发布时即提供与 Nova Multimodal Embeddings 嵌入的原生集成,使得构建可扩展的搜索应用变得简单直接。如之前示例所示,Amazon S3 Vectors 提供了一种将嵌入与您的应用数据一起存储和查询的简单方法。
注意事项
Nova Multimodal Embeddings 提供四种输出维度选项:3,072、1,024、384 和 256。较大维度提供更详细的表示,但需要更多存储和计算。较小维度在检索性能和资源效率之间提供了实用的平衡。这种灵活性帮助您针对特定应用和成本要求进行优化。
该模型可处理可观的上下文长度。对于文本输入,它一次最多可以处理 8,192 个令牌。视频和音频输入支持长达 30 秒的片段,并且该模型可以对更长的文件进行分段。此分段功能在处理大型媒体文件时特别有用——模型将其拆分为可管理的部分并为每个片段创建嵌入。
该模型包含内置于 Amazon Bedrock 的负责任的人工智能功能。提交用于嵌入的内容会经过 Amazon Bedrock 内容安全过滤器,并且该模型包含减少偏向的公平性措施。
如代码示例所述,该模型可以通过同步和异步 API 调用。同步 API 适用于需要即时响应的实时应用,例如在搜索界面中处理用户查询。异步 API 更高效地处理对延迟不敏感的工作负载,使其适用于处理视频等大型内容。
可用性和定价
Amazon Nova Multimodal Embeddings 现已在 Amazon Bedrock 的美国东部(弗吉尼亚州北部)AWS 区域正式推出。有关详细定价信息,请访问 Amazon Bedrock 定价页面。
要了解更多信息,请参阅包含全面文档的 Amazon Nova 用户指南和包含实用代码示例的 GitHub 上的 Amazon Nova 模型手册。
如果您使用 AI 驱动的软件开发助手,例如 Amazon Q Developer 或 Kiro,您可以设置 AWS API MCP 服务器来帮助 AI 助手与 AWS 服务和资源交互,并设置 AWS Knowledge MCP 服务器以提供最新文档、代码示例、有关 AWS API 和 CloudFormation 资源的区域可用性知识。
立即开始使用 Nova Multimodal Embeddings 构建多模态 AI 驱动的应用程序,并通过 AWS re:Post for Amazon Bedrock 或您常用的 AWS Support 联系人分享您的反馈。
— Danilo
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
