亚马逊AWS官方博客
推出 Amazon Bedrock Managed Knowledge Base,助力企业人工智能应用程序更快速、更准确
今日,我们正式推出 Amazon Bedrock Managed Knowledge Base,这套拥有全新功能的产品可让开发人员在数分钟内,依托企业自己的专有数据搭建企业级生成式人工智能应用程序。构建代理式人工智能应用程序的组织需要安全、可靠且最新的企业级数据访问,以交付准确、快速且可信的结果。Managed Knowledge Base 简化构建、管理检索增强生成(RAG)管道的复杂流程,让开发人员可专注业务成果落地,无需投入精力管理基础设施。
当前,为代理构建知识库的开发人员主要面临三大关键挑战:
- 连接到企业数据 — 企业知识分散在不同系统中,这些系统具有不同的内容类型、访问控制列表和文档格式。针对每个源构建和维护自定义连接器会增加复杂性,拖慢开发速度。
- 优化 RAG 准确性 — 检索增强生成的最佳实践在不断演进。开发人员需要尝试不同的解析策略、分块方法、嵌入模型和代理检索行为,以便从其数据中获得准确的答案。
- 大规模管理基础设施 — 企业需要承载包含数百万文档的大型知识库,或是跨团队管理数千个小型知识库。两种模式都需要可靠的基础设施、安全管控与成本控制。
上述难题迫使开发人员反复执行同质化基础工作,无法聚焦应用程序本身的开发。
Amazon Bedrock Managed Knowledge Base 可解决这些痛点,将开发人员以往需自行搭建、维护的多类基础设施组件(存储、检索、嵌入、重排序、基础模型选型)统一集成为一套托管原语。默认情况下,该服务会自动代表您选择和管理默认的嵌入模型、重排序模型和基础模型,使您能够快速上手,无需自行挑选或维护。在此托管基础之上,三项核心创新进一步提升易用性和准确性:
- 原生数据连接器 — 六个预构建的摄取连接器,可从 SaaS 应用程序中原生拉取企业数据和权限,省去开发人员在管理应用程序特定需求方面的开销。发布时,我们支持 Amazon S3、SharePoint、Confluence、Web Crawler、Google Drive 和 OneDrive。
- 智能解析 — 不同的内容类型和来源需要差异化处理方案,以便实现精准检索。智能解析可以自动处理此类复杂场景,针对每种数据类型和连接器匹配最优解析策略,保障代理的准确性。
- 代理检索器 — 针对复杂查询进行优化,可在单个知识库或跨多知识库中完成多轮、多步骤检索。代理检索器可自动推断终端用户意图,并从分布在各类数据来源、多模态载体中的企业知识库提取相关上下文信息。
仅需几行代码,Amazon Bedrock Managed Knowledge Base 即可自动管理并扩展端到端 RAG 管线,为您的企业知识代理提供支持。面向代理开发人员,该功能在 Amazon Bedrock AgentCore 网关中以预制目标类型提供,仅需少量代码即可完成集成;系统自动生成基于角色的权限,并在 AgentCore 可观测性面板中提供可观测指标和评估指标。
Amazon Bedrock Managed Knowledge Base 入门
创建 Managed Knowledge Base 十分简单。导航到 Amazon Bedrock AgentCore 控制台或 Amazon Bedrock 控制台,打开知识库页面,然后选择创建 Managed KB。两个控制台的操作完全一致。您会看到,非结构化向量存储知识库现已设为推荐选项,同时提供您可能已熟悉的其他知识库类型:
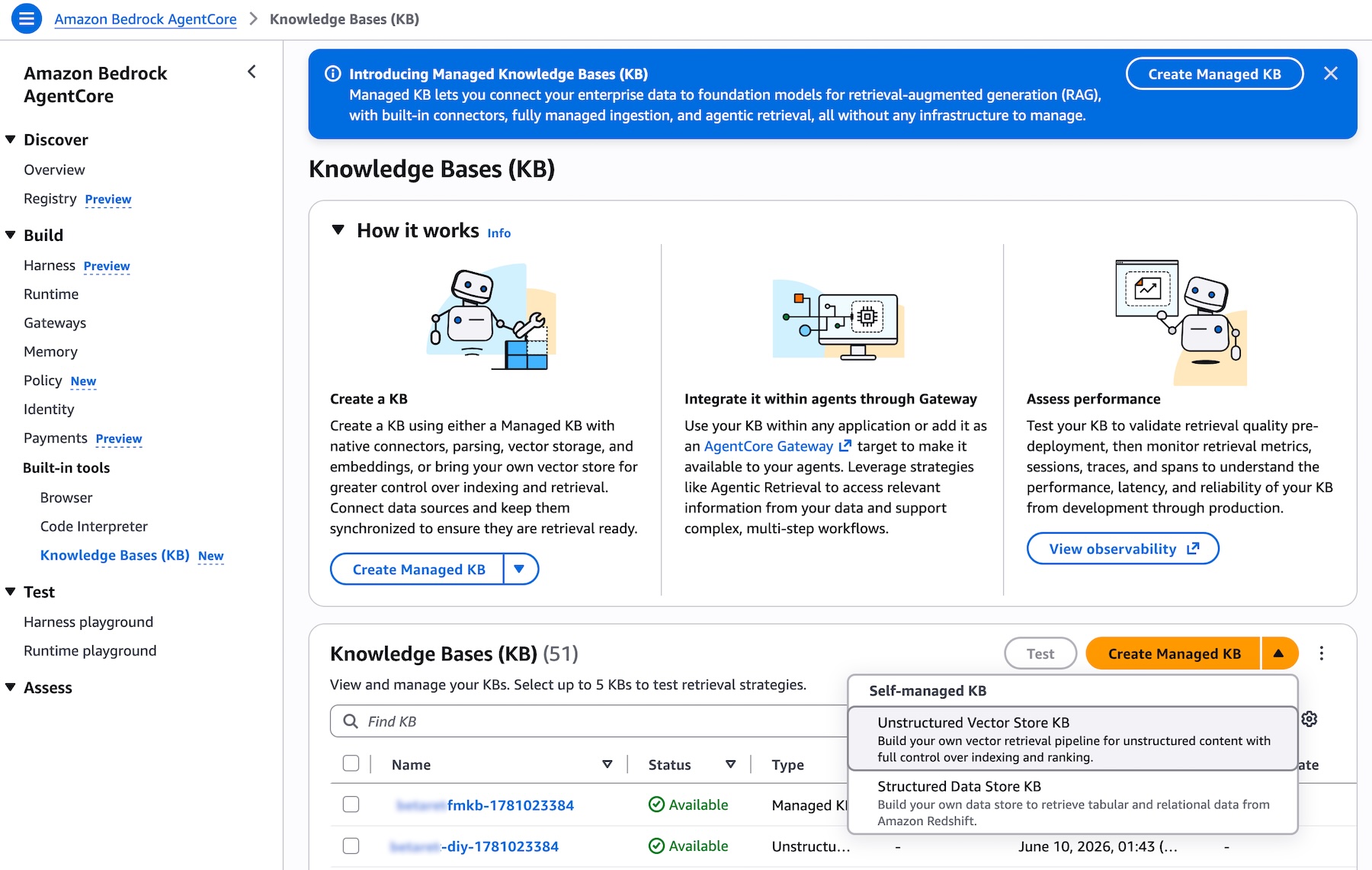
图 1 — Amazon Bedrock AgentCore 控制台知识库列表页面,展示类型列内各类知识库,以及创建 Managed KB 按钮
新建知识库时,您可直接在下拉菜单的支持连接器列表中,选择企业数据来源完成连接。AWS Identity and Access Management(IAM)角色会自动创建,您可以根据需要选择编辑这些权限:
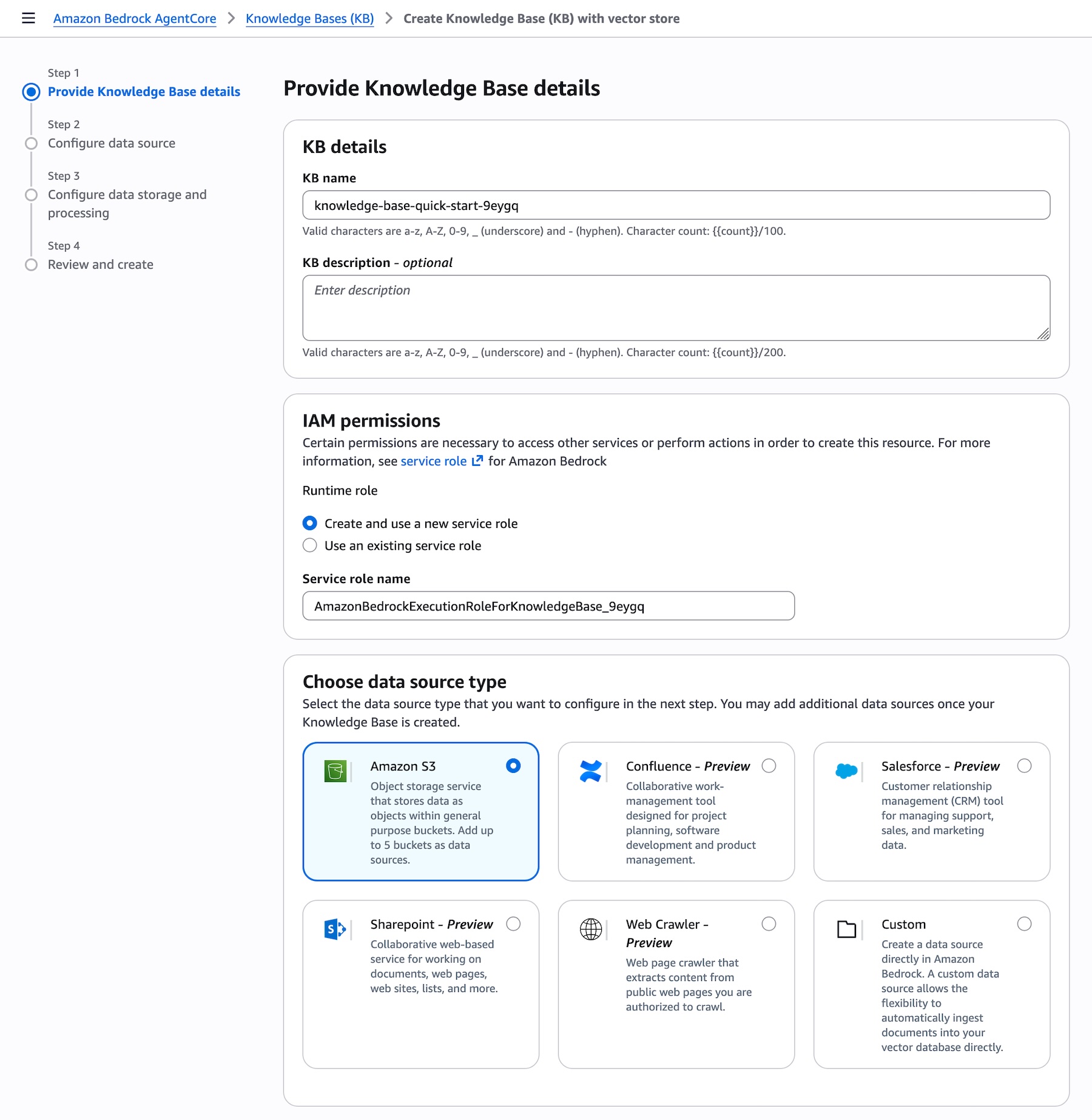
图 2 — 创建知识库页面,显示数据来源下拉菜单,包含所有支持的连接器:Amazon S3、Confluence、Custom、Google Drive、OneDrive、SharePoint 和 Web Crawler
系统会呈现一组经过优化的默认配置,使您仅需单击几次即可创建知识库。数据同步后,您可以将知识库与您的代理集成,或者将其作为基础模型的工具,开始用于查询。
智能解析,实现准确的数据摄取
构建知识库的主要挑战之一,是准备多样化的数据类型,以确保准确检索。当您将 Managed Knowledge Base 指向数据来源后,智能解析会自动为每种数据类型和连接器确定最优解析策略,无需额外配置。
智能解析融合多项技术:
- 连接器专属数据模型 — 针对每个数据来源进行优化处理。例如,Web Crawler 连接器会保留 HTML 结构,包括内嵌图片和表格,确保摄取过程中不会丢弃丰富内容。SharePoint 连接器保留文档层次结构和文件之间的关系。
- 多模态处理 — 自动检测并处理文档中的不同内容类型。系统会识别文档中的边界框,然后将其发送至基础模型,以便进行视频文件中的数据提取、字幕生成和场景描述。
- 优化分块 — 智能解析利用基础模型理解文档结构并提取有意义的内容,确保包含混合格式的复杂文档能够得到正确索引。智能默认设置会根据文档类型和内容结构,在检索准确性与性能之间取得平衡,同时高级用户也可以在需要时自定义分块策略。
这种自动化方案可省去以往为达到生产级检索精度所需的数周调试工作,同时保留在需要时进行自定义的灵活性。
使用代理检索器进行复杂查询
完成数据摄取后,即可开始查询您的知识库。生成式人工智能应用程序在处理复杂用户查询时经常遇到困难,这类查询需要推理、递归的多步检索以及中间结果评估。假设用户提出两个相关问题:“机器学习平台团队的云基础设施预算是多少?”以及“费用制度是否允许预付年度合约?” 单个检索步骤可能会显示机器学习平台团队相关文档,但无法关联预算信息与费用策略,难以完整解答问题。
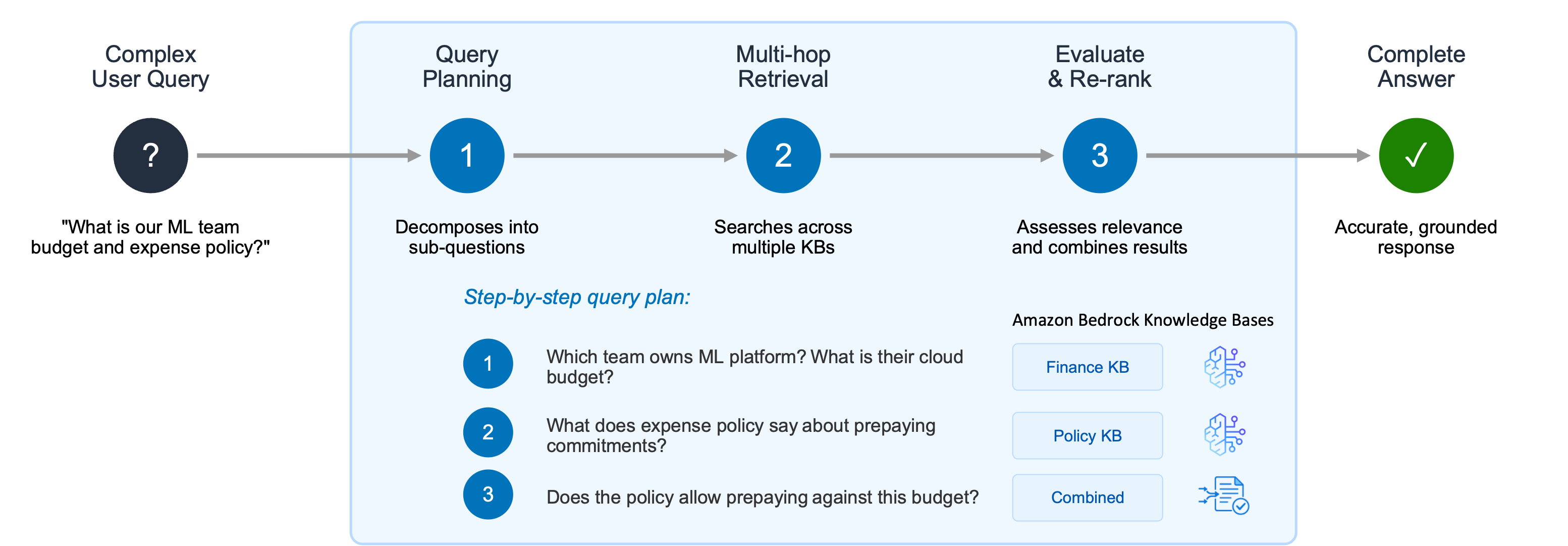
图 3 — 代理检索器将复杂用户查询分解为逐步计划,跨多个知识库执行多跳检索,并组合结果以输出准确且有依据的回复
代理检索器通过创建逐步查询计划以解决这一问题:1.哪个团队负责机器学习平台,其云基础设施预算是多少? 2.费用策略中关于预付年度合约的规定是什么? 3.该策略是否允许机器学习平台团队从这笔预算中进行预付?
系统在每一步执行多跳检索和推理,收集到充足相关文本片段后,终止检索流程并返回最优结果。通过消除搭建独立多跳推理管线的复杂流程,此方法大幅提升复杂查询的准确率,同时让开发人员可专注开发代理检索应用,无需编排逻辑。
您可以直接在 Amazon Bedrock AgentCore 控制台的知识库测试面板中试用代理检索器。选择仅代理检索作为检索类型,系统将自动在您的知识库中规划和执行多步查询:
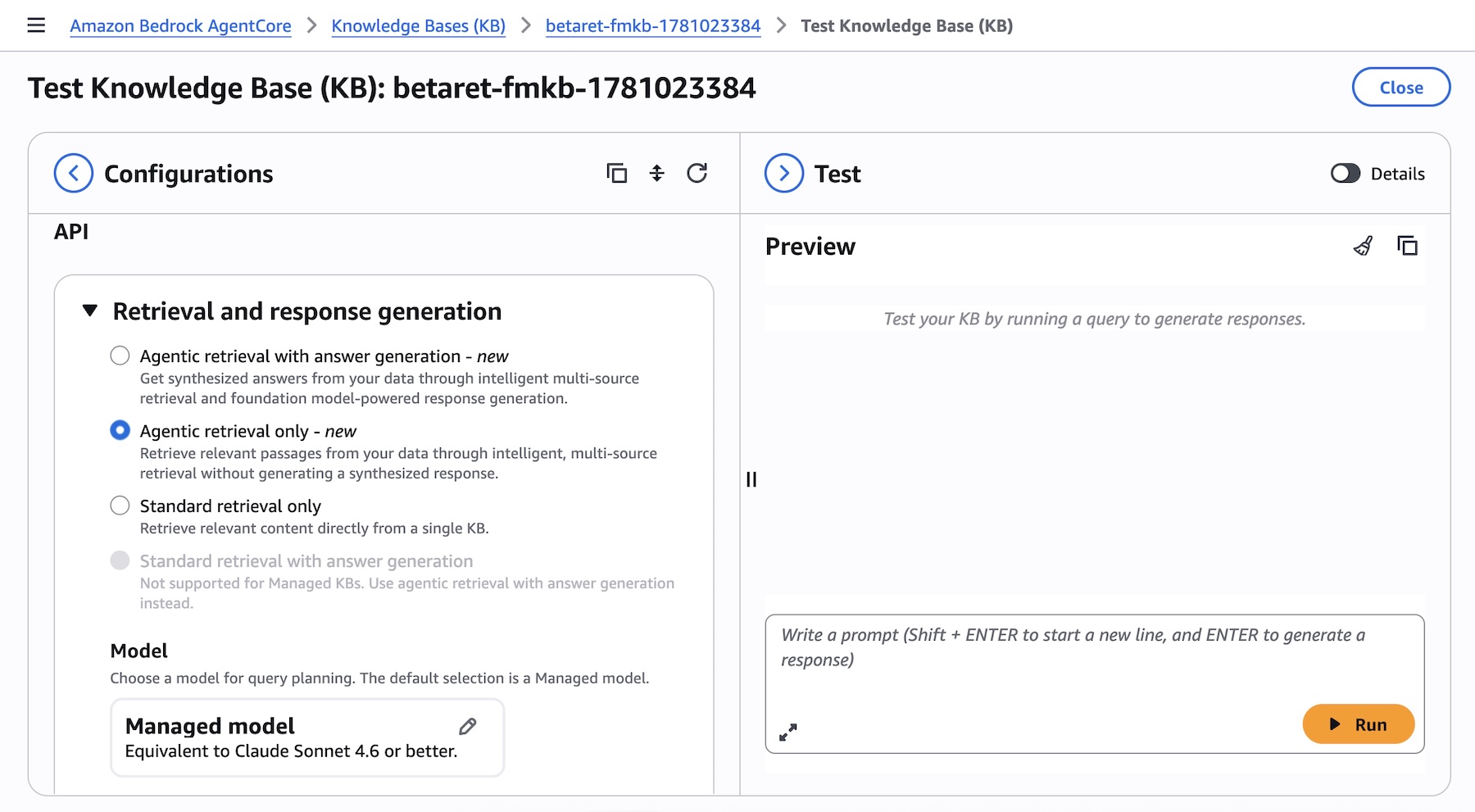
图 4 — 测试知识库面板,显示已选择“带答案生成的代理检索”作为检索类型,同时显示模型选择及最大代理迭代次数选项
使用 Bedrock AgentCore 启用 MCP
Amazon Bedrock Managed Knowledge Base 作为原生目标类型与 AgentCore 网关无缝集成。该集成无需手动集成,提供内置的可观测性、策略执行机制和自动权限管理。
您可以导航到 Amazon Bedrock AgentCore 控制台或 SDK,创建 AgentCore 网关,也可选择已有网关。向网关添加目标时,您会发现知识库是一种新的预构建目标类型,与 MCP 服务器、Lambda ARN、REST API 及其他集成选项并列展示。只需选择知识库 ID,即可通过网关公开该知识库:
图 5 — AgentCore 网关中的添加目标页面,将知识库显示为新的预构建目标类型,附带知识库 ID 选择器和运行时检索模式选项
AgentCore 网关中的添加目标页面,将知识库显示为新的预构建目标类型,附带知识库 ID 选择器和运行时检索模式选项
网关对外提供标准模型上下文协议(MCP),各类兼容 MCP 的框架客户端可自动识别知识库工具,涵盖 Strands Agents、LangChain、CrewAI、LlamaIndex、LangGraph。无需自定义集成代码。
模型选择和灵活性
Amazon Bedrock Managed Knowledge Base 保留 Amazon Bedrock 为开发人员提供的灵活性。Bedrock 上所有可用基础模型均可支持生成步骤,开发人员可选用各类嵌入模型与重排序模型,针对自身特定使用案例优化检索。团队无需改动基础设施,即可微调检索准确性和成本效益。
不同于会限定您使用特定模型服务商的托管方案,Amazon Bedrock Managed Knowledge Base 将基础设施管理(连接器、解析、存储、检索编排)与模型选择分离开来。这意味着您可以:
- 充分利用最新模型 — 当全新嵌入、重排序、基础模型上线后,您可直接选用以优化应用程序的准确性、延迟与成本,无需重构 RAG 管线。
- 优化性价比 — 简单查询选用轻量高速模型,复杂推理任务选用高性能模型,全部使用相同的知识库基础设施。
- 使用 Bedrock 嵌入模型 — 智能解析内置优化默认配置,如果业务领域需要专业语义解析,您可自行配置 Bedrock 嵌入模型。
- 与现有应用保持一致性 — 如果您已在使用 Bedrock 知识库 API(
Retrieve、StartIngest、StopIngest、IngestKnowledgeBaseDocuments),Managed Knowledge Base 使用相同的 API,因此迁移无需更改代码,只需指向新的知识库 ID 即可。
此方法让您可专注开发生成式人工智能应用程序,同时能够根据业务需求变化、新模型功能灵活更换模型,不受限制。
立即开始
Amazon Bedrock Managed Knowledge Base 现已在以下区域推出:美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太(悉尼、东京)、欧洲(都柏林、法兰克福、伦敦)以及 AWS GovCloud(美国西部)区域。有关区域可用性和未来路线图,请访问按区域列出的 AWS 功能。
借助 Bedrock Managed Knowledge Base,您可以按使用量付费,无需预先承诺。定价基于两个维度:存储的索引数据容量、按需执行的检索调用次数。有关详细定价信息,请访问 Amazon Bedrock 定价页面。Bedrock 也是 AWS 免费套餐的一部分,可供新的 AWS 客户用于免费开始使用并探索关键 AWS 服务。
这些功能适用于任何开源框架,例如 CrewAI、LangGraph、LlamaIndex 和 Strands Agents 以及任何基础模型。Bedrock 服务可以一起使用,也可以单独使用,您可以首先在自己喜欢的人工智能辅助开发环境中使用 AgentCore 开源 MCP 服务器。
要了解更多信息并快速入门,请访问《Bedrock Knowledge Bases Developer Guide》。
Daniel Abib