亚马逊AWS官方博客
新增功能 – 在 Amazon S3 中将 Amazon DynamoDB 表数据导出到您的湖内数仓,无需编写代码
自 2012 年推出以来,已有数十万 AWS 客户选择用 Amazon DynamoDB 处理任务关键型工作负载。DynamoDB 是一个非关系托管数据库,允许您存储几乎无限量的数据,并以任何规模的单数毫秒级性能检索数据。
为了从这些数据中获得最大价值,客户必须依靠 AWS Data Pipeline、Amazon EMR 或基于 DynamoDB 流的其他解决方案。这些解决方案通常需要构建具有高读取吞吐量的自定义应用程序,继而会产生高昂的维护和运营成本。
今天,我们将推出一项新功能,这项功能可使您将 DynamoDB 表数据导出 Amazon Simple Storage Service (S3)——无需编写代码。
它是 DynamoDB 的一项新的原生功能,可以以任何规模运行,无需管理服务器或集群,且该功能支持您跨 AWS 区域和账户以秒级粒度将数据导出到过去 35 天的任何时间点。此外,它不会影响生产表的读取容量或可用性。
当您将数据以 DynamoDB JSON 或 Amazon Ion 格式导出到 S3 后,您即可使用 Amazon Athena、Amazon SageMaker 和 AWS Lake Formation 等收藏夹工具查询或重新塑造它们。
在本文中,我将向您演示如何将 DynamoDB 表导出到 S3,然后使用标准 SQL 通过 Amazon Athena 进行查询。
将 DynamoDB 表导出到 S3 存储桶
导出过程依赖于 DynamoDB 在后台持续备份数据的能力。此功能称为连续备份:它支持时间点恢复 (PITR),并支持您将表恢复到过去 35 天内的任何时间点。
您可以通过点击 Streams and exports(流和导出)选项卡中的 Export to S3(导出到 S3)开始。

除非您已启用连续备份,否则您必须在下一页中通过点击 Enable PITR(启用 PITR)来启用它们。
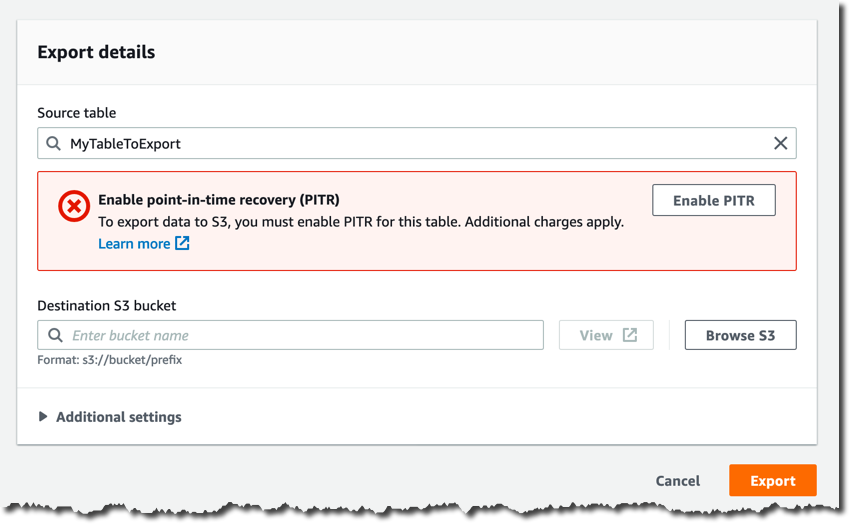
在目标 S3 存储桶中提供存储桶名称,例如 s3: //my-dynamodb-export-bucket。请记住,您的存储桶也可能位于其他账户或其他区域。
请随意查看其他设置,您可以在此处配置特定的时间点、输出格式和加密密钥。我将使用默认设置。

现在,您可以通过点击 Export(导出)来确认导出请求。
导出过程开始,您可以在 Streams and exports(流和导出)选项卡中监测其状态。

导出过程完成后,您将在 S3 存储桶中找到一个新的 AWSDynamoDB 文件夹以及与导出 ID 对应的子文件夹。
这就是该子文件夹的内容。

您将发现两个清单文件,它们将支持您验证完整性和发现 data 子文件夹中 S3 对象的位置,而这些对象已为您自动压缩和加密。
如何通过 AWS CLI 自动执行导出过程
如果您想自动执行导出过程,例如每周或每月创建一次新导出,则可以通过 AWS 命令行界面 (CLI) 或 AWS 开发工具包、调用 ExportTableToPointInTime API 来创建新的导出请求。
下面是使用 CLI 的示例。
aws dynamodb export-table-to-point-in-time \
--table-arn TABLE_ARN \
--s3-bucket BUCKET_NAME \
--export-time 1596232100 \
--s3-prefix demo_prefix \
-export-format DYNAMODB_JSON
{
"ExportDescription": {
"ExportArn": "arn:aws:dynamodb:REGUIB:ACCOUNT_ID:table/TABLE_NAME/export/EXPORT_ID",
"ExportStatus": "IN_PROGRESS",
"StartTime": 1596232631.799,
"TableArn": "arn:aws:dynamodb:REGUIB:ACCOUNT_ID:table/TABLE_NAME",
"ExportTime": 1596232100.0,
"S3Bucket": "BUCKET_NAME",
"S3Prefix": "demo_prefix",
"ExportFormat": "DYNAMODB_JSON"
}
}请求导出后,您必须等待 ExportStatus 变为“COMPLETED”。
aws dynamodb list-exports
{
"ExportSummaries": [
{
"ExportArn": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/TABLE_NAME/export/EXPORT_ID",
"ExportStatus": "COMPLETED"
}
]
}使用 Amazon Athena 分析导出的数据
一旦数据安全地存储在 S3 存储桶中,您就可以使用 Amazon Athena 开始对其进行分析。
您将在 S3 存储桶中找到很多 gz 压缩对象,每个对象都包含拥有多个 JSON 对象的文本文件,每行一个对象。这些 JSON 对象与包装在 Item 字段中的 DynamoDB 项目相对应,并根据您选择的导出格式具有不同的结构。
在上面的导出过程中,我选择了 DynamoDB JSON,而示例表中的项目代表简单游戏的用户,因此典型对象如下所示。
{
"Item": {
"id": {
"S": "my-unique-id"
},
"name": {
"S": "Alex"
},
"coins": {
"N": "100"
}
}
}在本示例中,name 是字符串,而 coins 是数字。
我建议使用 AWS Glue 爬网程序自动发现数据的 Schema 并在 AWS Glue 目录中创建虚拟表。
但是,您还可以使用 CREATE EXTERNAL TABLE 语句手动定义虚拟表。
CREATE EXTERNAL TABLE IF NOT EXISTS ddb_exported_table (
Item struct <id:struct<S:string>,
name:struct<S:string>,
coins:struct<N:string>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://my-dynamodb-export-bucket/AWSDynamoDB/{EXPORT_ID}/data/'
TBLPROPERTIES ( 'has_encrypted_data'='true');现在,您可以使用常规 SQL 查询它,甚至可以使用 Create Table as Select (CTAS) 查询来定义新的虚拟表。
使用 DynamoDB JSON 格式时,您的查询如下所示。
SELECT
Item.id.S as id,
Item.name.S as name,
Item.coins.N as coins
FROM ddb_exported_table
ORDER BY cast(coins as integer) DESC;您将获得一个结果集作为输出。

性能和成本注意事项
导出过程是无服务器的,它会自动扩展,而且比自定义表扫描解决方案快得多。
完成时间取决于表的大小以及统一数据在表中的分布方式。大多数导出在 30 分钟内完成。对于不超过 10GiB 的小型表,导出应该只需几分钟;对于 TB 级的超大表,可能需要几个小时。由于您不使用湖内数仓导出来进行实时分析,这应该不是问题。通常,湖内数仓用于大规模聚合数据并生成每日、每周或每月报告。因此,大多数情况下,在继续使用分析管道之前,您可以等待几分钟或几小时让导出过程完成。
由于这项新功能的无服务器性质,因此没有小时成本:您只需为导出到 Amazon S3 的 GB 数据付费,例如,在美国东部区域,每 GiB 的费用为 0.10 美元。
由于数据会导出至您自己的 S3 存储桶且连续备份是导出过程的先决条件,请记住,您将会产生与 DynamoDB PITR 备份和 S3 数据存储相关的额外费用。涉及的所有成本组成部分仅取决于您要导出的数据量。因此,总体成本很容易估计,且远低于构建具有高读取吞吐量和高昂维护成本的自定义解决方案的总体拥有成本。
现已推出
这项新功能现已在提供连续备份的所有 AWS 区域推出。
您可以使用 AWS 管理控制台、AWS 命令行界面 (CLI) 和 AWS 开发工具包提出导出请求。此功能可使开发人员、数据工程师和数据科学家轻松地从 DynamoDB 表中提取和分析数据,而无需为 ETL(提取、转换、加载)设计和构建昂贵的自定义应用程序。
您现在可以将内部分析工具连接到 DynamoDB 数据,利用 Amazon Athena 等服务进行临时分析、利用 Amazon QuickSight 进行数据探索和可视化、利用 Amazon Redshift 和 Amazon SageMaker 进行预测分析等等。
— Alex