亚马逊AWS官方博客
Amazon Redshift 的新功能 – 数据湖导出和联合查询
数据仓库是经过优化的数据库,可以分析来自事务系统和业务线应用程序的关系数据。Amazon Redshift 是一个快速、完全托管的数据仓库,可帮助使用标准 SQL 和现有商业智能 (BI) 工具的数据分析过程变得简单且经济高效。
要从不适合数据仓库的非结构化数据中获取信息,可以构建一个数据湖。 数据湖是一种集中的存储库,可以存储任何规模的各种结构化和非结构化数据。 借助基于 Amazon Simple Storage Service (S3) 构建的数据湖,您可以轻松运行大数据分析,并使用机器学习来从半结构化(例如 JSON、XML)和非结构化数据集中获得深入见解。
今天,我们将推出两项新功能,以帮助您改善管理数据仓库和与数据湖集成的方式:
- 数据湖导出 以 Apache Parquet 格式将数据从 Redshift 集群卸载到 S3,这是一种进行了分析优化的高效开放列式存储格式。
- 联合查询能够查询 Redshift 集群、S3 数据湖以及一个或多个 PostgreSQL 和 Amazon Aurora PostgreSQL 数据库的 Amazon Relational Database Service (RDS) 中存储的数据。
该架构图简要概述了这些功能的工作方式以及如何将它们与其他 AWS 服务配合使用。
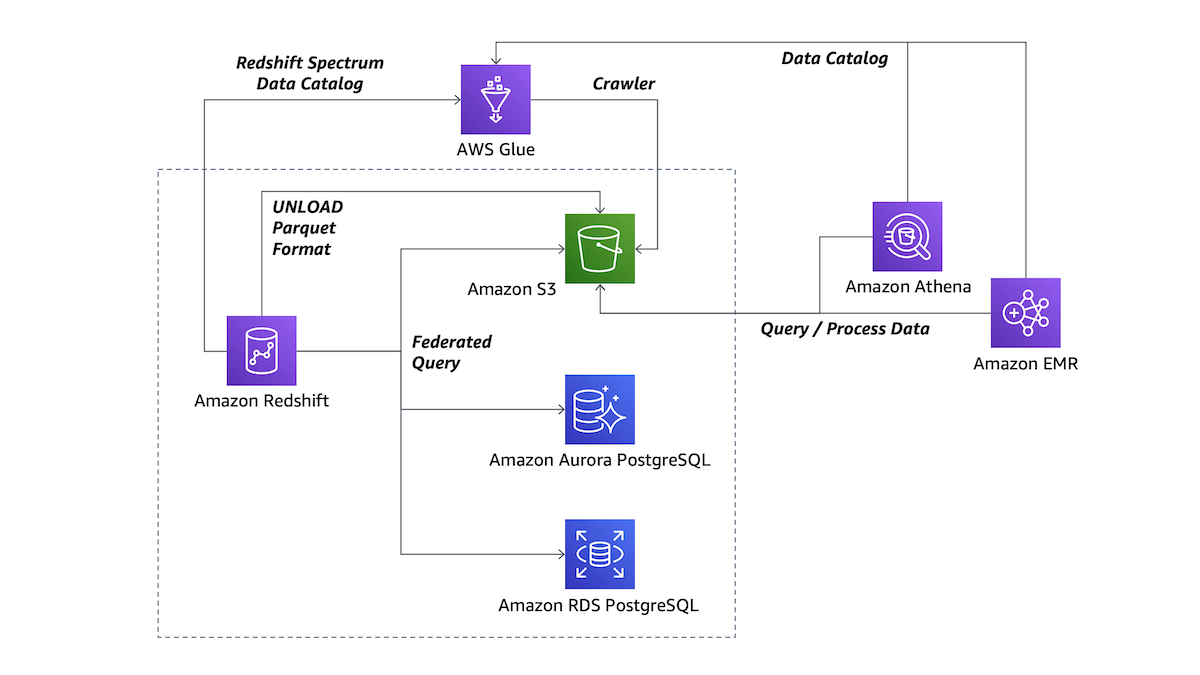
让我们从如何使用这些功能以及它们提供的优势开始,更好地说明您在图中看到的交互。
使用 Redshift Data Lake 导出
现在,您可以将 Redshift 查询的结果以 Apache Parquet 格式卸载到 S3 数据湖。与文本格式相比,Parquet 格式的卸载速度最多快 2 倍,而 S3 中的存储空间最多减少 6 倍。 这使您可以将 Redshift 中完成的数据转换和扩展保存到开放格式的 S3 数据湖中。
然后,您可以使用 Redshift Spectrum 分析数据湖中的数据,该功能允许您直接从 S3 上的文件中查询数据。或者,您可以使用其他工具,例如 Amazon Athena、Amazon EMR 或 Amazon SageMaker。
为了尝试这项新功能,我从 Redshift 控制台创建了一个新集群,并遵循本教程进行操作以加载示例数据,跟踪不同场所音乐时间的销售情况。我想将此数据与存储在我的数据湖中社交媒体对演出的评论相关联。要了解它们的相关性,每个事件都应该有一种将其相对销售额与其他事件进行比较的方法。
让我们在 Redshift 中构建一个查询,以将数据导出到 S3。 我的数据存储在多个表中。我需要创建一个查询,以便获得销售情况的单一视图。我想加入销售额和日期表的内容,添加有关演出总销售额的信息(查询中的 total_price),以及相比所有事件,占全时段总销售额的百分比。
我使用以下 SQL 命令,将查询结果以 Parquet 格式导出到 S3:
UNLOAD ('SELECT sales.*, date.*, total_price, percentile
FROM sales, date,
(SELECT eventid, total_price, ntile(1000) over(order by total_price desc) / 10.0 as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) as percentile_events
WHERE sales.dateid = date.dateid
AND percentile_events.eventid = sales.eventid')
TO 's3://MY-BUCKET/DataLake/Sales/'
FORMAT AS PARQUET
CREDENTIALS 'aws_iam_role=arn:aws:iam::123412341234:role/myRedshiftRole';我将使用 AWS Identity and Access Management (IAM) 角色,授予 Redshift 对我的 S3 存储桶的写入访问权限。我可以使用 AWS 命令行界面 (CLI) 查看 UNLOAD 命令的结果。如预期的那样,使用 Parquet 列数据格式导出查询输出:
$ aws s3 ls s3://MY-BUCKET/DataLake/Sales/
2019-11-25 14:26:56 1638550 0000_part_00.parquet
2019-11-25 14:26:56 1635489 0001_part_00.parquet
2019-11-25 14:26:56 1624418 0002_part_00.parquet
2019-11-25 14:26:56 1646179 0003_part_00.parquet
为了优化对数据的访问,我可以指定一个或多个分区列,以便将卸载数据自动分区到 S3 存储桶内的文件夹中。例如,我可以卸载按年、月和日分区的销售数据。这使我的查询可以利用分区修剪功能,并跳过扫描不相关的分区,从而提高查询性能和最大程度地降低成本。
要使用分区,我需要在前面的 SQL 命令中添加 PARTITION BY 选项,然后添加将数据分区到不同目录中要使用的列。在本例中,我想根据销售的年份和日历日期(查询中的caldate)对输出进行分区。
UNLOAD ('SELECT sales.*, date.*, total_price, percentile
FROM sales, date,
(SELECT eventid, total_price, ntile(1000) over(order by total_price desc) / 10.0 as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) as percentile_events
WHERE sales.dateid = date.dateid
AND percentile_events.eventid = sales.eventid')
TO 's3://MY-BUCKET/DataLake/SalesPartitioned/'
FORMAT AS PARQUET
PARTITION BY (year, caldate)
CREDENTIALS 'aws_iam_role=arn:aws:iam::123412341234:role/myRedshiftRole';
这次,查询输出存储在多个分区中。例如,特定年份和日期的文件夹内容如下:
$ aws s3 ls s3://MY-BUCKET/DataLake/SalesPartitioned/year=2008/caldate=2008-07-20/
2019-11-25 14:36:17 11940 0000_part_00.parquet
2019-11-25 14:36:17 11052 0001_part_00.parquet
2019-11-25 14:36:17 11138 0002_part_00.parquet
2019-11-25 14:36:18 12582 0003_part_00.parquet
另外,我还可以使用 设置一个爬网程序,该爬网程序(按需或按计划)通过在我的 S3 存储桶中查找数据更新 Glue 数据目录。数据目录更新后,我可以使用 Redshift Spectrum、Athena 或 EMR 轻松查询数据。
现在可以在我的数据湖中合并处理销售数据与非结构化和半结构化(JSON、XML、Parquet)数据。例如,我现在可以将 Apache Spark 与 EMR 或任何 Sagemaker 内置算法配合使用,以此访问数据并获得新见解。
使用 Redshift 联合查询
现在,您还可以直接从 Redshift 数据仓库访问 RDS 和 Aurora PostgreSQL 存储中的数据。这样,您可以立即访问可用的数据。您现在可以直接在 Redshift 中对数据仓库、事务数据库和数据湖中的数据执行查询处理,而无需 ETL 作业将数据传输到数据仓库。
Redshift 利用其先进的优化功能,将大量计算直接下推,并将其分配到事务数据库中,从而最大限度地减少了通过网络传输的数据量。
使用以下语法,可以将外部模式从 RDS 或Aurora PostgreSQL 数据库添加到 Redshift 集群:
CREATE EXTERNAL SCHEMA IF NOT EXISTS online_system
FROM POSTGRES
DATABASE 'online_sales_db' SCHEMA 'online_system'
URI ‘my-hostname' port 5432
IAM_ROLE 'iam-role-arn'
SECRET_ARN 'ssm-secret-arn';架构和端口在此处可选。如果未指定,则 Schema 将默认为public,而 PostgreSQL 数据库的默认端口为 5432。Redshift 正在使用 AWS Secrets Manager 来管理连接到外部数据库的凭证。
借助此命令,外部架构式中的所有表格均可用,并且 Redshift 可以使用这些表格对集群中的数据,或使用 Redshift Spectrum 对 S3 数据湖中的数据,执行任何复杂的 SQL 查询处理。
回到我之前使用的销售数据示例,现在我可以将音乐事件的历史数据趋势与实时销售额相关联。通过这种方式,我可以了解事件是否按预期执行,并可以无延迟地调整营销活动。
例如,我在 Redshift 集群中将在线商务数据库定义为 online_system 外部架构,随后,我可以通过以下简单查询比较以前的销售额与在线商务系统中的销售额:
SELECT eventid,
sum(pricepaid) total_price,
sum(online_pricepaid) online_total_price
FROM sales, online_system.current_sales
GROUP BY eventid
WHERE eventid = online_eventid;Redshift 不会完全导入数据库或架构目录。运行查询时,它将本地化查询中的 Aurora 和RDS 表(以及视图)的元数据。然后,使用此类本地化元数据编译查询和生成计划。
现已推出
Amazon Redshift 数据湖导出是改善数据处理管道的一种新工具,Redshift发行版 1.0.10480 或更高版本均支持该工具。请参阅 AWS 区域表 以了解 Redshift 可用性,并查看集群的版本。
Amazon Redshift 中新的联合身份验证功能是作为公开预览版发布,使您可以将存储在Redshift、S3 和一个或多个 RDS 和 Aurora PostgreSQL 数据库中的数据汇总在一起。在 Amazon Redshift 管理控制台中创建集群时,您可以选择三个维护追踪:当前、跟踪或预览。在“预览”追踪内,应选择 preview_features 以参与联合查询的公开预览。例如:

这些功能简化了数据处理和分析,为您提供了更多快速响应工具和单一数据视图。快来告诉我您打算怎么使用它们吧!
– Danilo