亚马逊AWS官方博客
将 Amazon DynamoDB 数据流式传输到集中式数据湖
原文链接:https://aws.amazon.com/blogs/big-data/streaming-amazon-dynamodb-data-into-a-centralized-data-lake/
对于逐渐基于无服务器技术来构建微服务体系的组织来说,Amazon DynamoDB 已成为首选的后端数据库,因为它是完全托管式,涵盖多region,本身支持多活的可用性,而且内置了安全控制、备份和还原功能以及高可扩展的内存缓存,您可以使用它来获取近乎实时的业务见解。数据湖使业务团队能够随时使用 BI 工具,使数据科学团队能够训练模型。
本文演示了使用 Amazon Kinesis Data Streams、Amazon Lambda 和 Amazon Kinesis Data Firehose 通过同一 AWS region中的 VPC 终端节点将 DynamoDB 表流式传输到 Amazon Simple Storage Service (Amazon S3) 存储桶的两个常见案例。我们根据账户配置探讨这两个案例:
- 同一个 Amazon Web Sevices 账户中的 DynamoDB 和 Amazon S3
- 不同 Amazon Web Sevices 账户中的 DynamoDB 和 Amazon S3
我们使用以下亚马逊云科技服务:
- 支持Amazon DynamoDB 的Amazon Kinesis Data Streams — 用于 Amazon DynamoDB 的 Amazon Kinesis Data Streams 可捕获任何 DynamoDB 表中的item级修改,并将其复制到您选择的 Kinesis 数据流中。您的应用程序能够以近乎实时的方式访问数据流并查看item级更改。这使您能够构建应用程序来支持实时控制面板、生成警报、实施动态定价和广告,以及执行复杂的数据分析,例如应用机器学习 (ML) 算法。
将Amazon DynamoDB 数据流式传输到数据流使您能够持续捕获和存储数据,每小时的数据量可达 TB 级。Amazon Kinesis Data Streams 使您能够充分利用更长的数据留存时间、增强的扇出功能(可同时用于两个以上的消费者应用程序),以及额外的审计和安全透明度。此外,Amazon Kinesis Data Streams 使您能够访问其他 Kinesis 服务,例如 Kinesis Data Firehose 和 Amazon Kinesis Data Analytics。
- Amazon Lambda —Amazon Lambda 让您无需预置或管理务器即可运行代码。它使您几乎能够运行任何类型的应用程序或后端服务的代码,而无需管理服务器或基础设施。您可以将代码设置为自动从其他 AWS 服务触发,也可以直接从任何 Web 或移动应用程序调用它。
- Amazon Kinesis Data Firehose — Amazon Kinesis Data Firehose 可以将流数据加载到数据湖、数据存储和分析服务中。它可以捕获、转换流数据并将其传输到 Amazon S3 和其他目标。这是一项完全托管式服务,可自动扩展以匹配您的数据吞吐量,无需管理。它还可以在加载之前批处理、压缩、转换和加密数据流,从而最大限度地减少使用的存储并提高安全性。
安全性是我们使用案例的主要关注点,因此两个使用案例中的服务都使用静态的服务器端加密和 VPC 终端节点来保护传输中的数据。
使用案例 1:同一个 Amazon Web Sevices账户中的 Amazon DynamoDB 和 Amazon S3
在我们的第一个使用案例中,Amazon DynamoDB 表和 Amazon S3 存储桶在同一个账户中。我们提供了以下资源:
- Kinesis 数据流的配置为使用 10 个分片,您可以根据需要进行更改。
- 启用Kinesis streaming功能的Amazon DynamoDB 表作为Kinesis data stream的源,并且Amazon Kinesis data stream被配置为 Firehose 传输流的源。
- Firehose 传输流的配置为使用 Lambda 函数进行转换并将数据传输到 S3 存储桶中。Firehose 传输流的配置为批处理记录 2 分钟或 1 MiB(以先到达者为准),然后将数据传输到 Amazon S3。可根据您的使用案例配置批处理时间窗口。有关更多信息,请参阅配置设置。
- 用于此解决方案的 Lambda 函数将Amazon DynamoDB 项目的多层级 JSON 结构转换为单层级 JSON 结构。它的配置为在 Amazon VPC 的私有子网中运行,不能访问互联网。您可以扩展该函数,以支持更复杂的业务转型。
下图展示了该解决方案的架构。
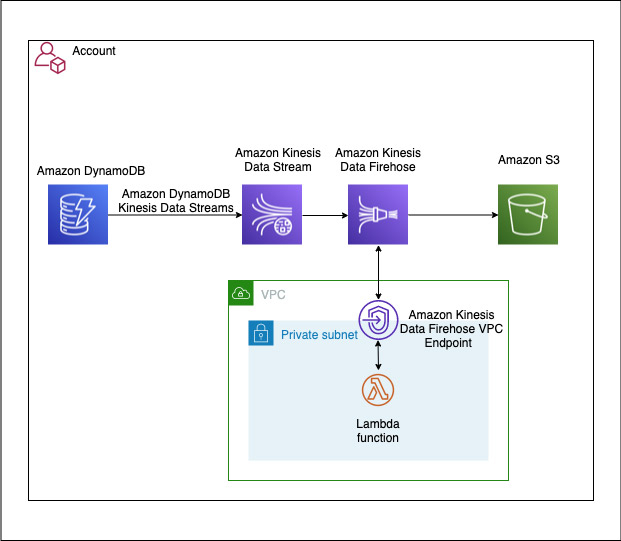
该架构使用Amazon DynamoDB 功能和 Amazon Kinesis Data Streams 来捕获 Amazon DynamoDB 表中的item级更改。通过这个功能,您可以安全地流式传输增量更新,而无需任何自定义代码或组件。
先决条件
要实施此架构,您需要:
- 一个 Amazon Web Sevices账户
- 管理员访问权限,以部署所需的资源
部署解决方案
在此步骤中,我们将创建一个新的 Amazon VPC 和其余组件。
我们还将创建具有以下功能的 S3 存储桶:
您可以根据自己的要求扩展模板,以启用 S3 存储桶的其他功能。
在本文中,我们使用 Amazon CloudFormation 模板来部署资源。
我们使用 Amazon Key Management Service (Amazon KMS) 密钥进行服务器端加密,从而对Amazon Kinesis Data Streams、Amazon Kinesis Data Firehose、Amazon S3 和Amazon DynamoDB 中的数据进行加密。
CloudWatch Logs 中的 Amazon CloudWatch 日志组数据始终是加密的。如果需要,您可以扩展此堆栈来使用 KMS CMK 对日志组进行加密。
1.点击下面的 Launch Stack(启动堆栈)按钮创建 CloudFormation:

2.在 CloudFormation 控制台上,接受参数的默认值。
3.选择我确认 Amazon CloudFormation 可以使用自定义名称创建 IAM 资源。
4.选择Create stack(创建堆栈)。
堆栈创建完成后,注意堆栈的输出选项卡中的 BucketName 输出变量的值。它是作为堆栈的一部分创建的 S3 存储桶的名称。我们稍后将使用此值来测试解决方案。
测试解决方案
为测试解决方案,我们插入一个新项目,然后使用 Amazon CloudShell 和 Amazon Command Line Interface (Amazon CLI) 更新 DynamoDB 表中的项目。我们还将使用 AWS 管理控制台监控和验证解决方案。
1.在 Amazon CloudShell 控制台上,验证您是否与Amazon DynamoDB 表(默认值为 us-east-1)位于同一个区域。
2.输入以下 Amazon CLI 命令插入item:
3.输入以下命令来更新项目:We are updating the Designation from “Architect” to ” Senior Architect”
Amazon DynamoDB 表中的所有item级修改将被发送到 Amazon Kinesis data stream(blog-srsa-ddb-table-data-stream),该数据流将数据传输到 Firehose 传输流(blog-srsa-ddb-table-delivery-stream)。
您可以通过传输流的监控选项卡来监控 Firehose 传输流中已更新记录的处理情况。
您可以通过检查 S3 存储桶中的对象(堆栈输出选项卡中的 BucketName 值)来验证向数据湖传输更新的情况。
Firehose 传输流的配置为使用自定义前缀向 Amazon S3 写入记录,该前缀基于记录被传输至传输流的日期。将按日期对传输的记录进行分区,这有助于通过限制查询引擎为返回特定查询结果而需扫描的数据量来提高查询性能。有关更多信息,请参阅 Amazon S3 对象的自定义前缀。
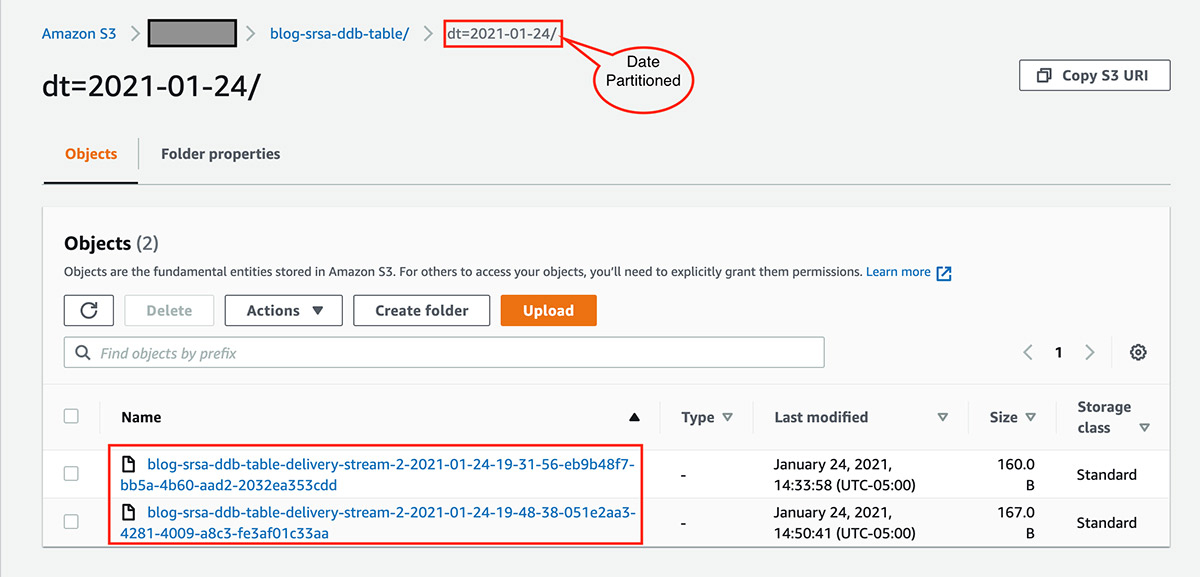
该文件采用 JSON 格式。您可以通过以下方式验证数据:
- 下载文件
- 通过运行 AWS Glue的爬虫程序创建一个可使用 Amazon Athena 查询的表
- 使用 Amazon S3 Select查询数据
使用案例 2:不同 Amazon Web Sevices账户中的 Amazon DynamoDB 和 Amazon S3
此使用案例的解决方案使用两个 CloudFormation 堆栈:创建者堆栈(部署在账户 A 中)和消费者堆栈(部署在账户 B 中)。
创建者堆栈(账户 A)进行以下部署:
- Kinesis 数据流的配置为使用 10 个分片,您可以根据需要进行更改。
- 启用Amazon Kinesis streaming功能的Amazon DynamoDB 表作为Kinesis data stream的源,并且Kinesis data stream被配置为 Firehose 传输流的源。
- Firehose 传输流的配置为使用 Lambda 函数进行记录转换,同时将数据传输到账户 B 的 S3 存储桶中。传输流的配置为批处理记录 2 分钟或 1 MiB(以较早者为准),然后将数据传输到 Amazon S3。可根据您的使用案例配置批处理窗口。
- Lambda 函数的配置为在 Amazon VPC 的私有子网中运行,不能访问互联网。对于此解决方案,该函数将多层级 JSON 结构转换为单层级 JSON 结构。您可以扩展该函数,以支持更复杂的业务转型。
消费者堆栈(账户 B)部署一个 S3 存储桶,其配置为接收来自账户 A 中的 Firehose 传输流的数据。
下图展示了该解决方案的架构。

该架构使用Amazon DynamoDB 功能和Amazon Kinesis Data Streams 来捕获 Amazon DynamoDB 表中的item级更改。通过这个功能,您可以安全地流式传输增量更新,而无需任何自定义代码或组件。
先决条件
对于此使用案例,您需要:
- 两个 Amazon Web Sevices账户(面向创建者和消费者)
- 如果您已经部署了第一个使用案例中的架构而且想使用相同的帐户,请先删除上一个使用案例中的堆栈。再继续阅读本节内容
- 管理员访问权限,以部署所需的资源
部署账户 B(消费者)的组件
此步骤将创建具有以下功能的 S3 存储桶:
- 使用 CMK 进行静态加密
- 阻止公共访问
- 存储桶版本控制
您可以根据需要扩展模板,以启用 S3 存储桶的其他功能。
我们将使用 CloudFormation 模板部署资源。作为最佳实践的一部分,可考虑根据需要按生命周期和所有权组织资源。
我们将使用 KMS 密钥进行服务器端加密,从而加密 Amazon S3 中的数据。
CloudWatch Logs 中的 CloudWatch 日志组数据始终是加密的。如果需要,您可以扩展此堆栈来使用 KMS CMK 对组数据进行加密。
1.选择 Launch Stack(启动堆栈),在您的账户中创建 CloudFormation 堆栈:
2.对于 DDBProducerAccountID,请输入账户 A 的账户 ID。
3.对于 KMSKeyAlias,将默认填充服务器端加密的 KMS 密钥,该密钥用于加密 Amazon S3 中的数据。
4.选择Create stack(创建堆栈)。
堆栈创建完成后,注意 BucketName 输出变量的值。我们稍后将使用此值来测试解决方案。
部署账户 A(创建者)的组件
在此步骤中,我们将使用账户 A 登录 Amazon Web Sevices 管理控制台来部署创建者堆栈。我们使用 KMS 密钥进行服务器端加密,从而对 Kinesis Data Streams、Kinesis Data Firehose、Amazon S3 和 DynamoDB 中的数据进行加密。与其他堆栈一样,CloudWatch Logs 中的 CloudWatch 日志组数据始终是加密的,但您可以扩展堆栈,以使用 KMS 密钥加密日志组数据。
1.选择 Launch Stack(启动堆栈),在您的账户中创建 CloudFormation 堆栈:
2.对于 ConsumerAccountID,输入账户 B 的 ID。
3.对于 CrossAccountDatalakeBucket,输入您在上一步中创建的账户 B 的存储桶的名称。
4.对于 ArtifactBucket,将默认填充包含部署所需的构件的 S3 存储桶。
5.对于 KMSKeyAlias,将默认填充服务器端加密的 KMS 密钥,该密钥用于加密 Amazon S3 中的数据。
6.对于 BlogTransformationLambdaFile,将默认填充用于执行 Amazon Firehose 数据转换的 Lambda 函数代码的 Amazon S3 密钥。
7.选择我确认 Amazon CloudFormation 可以使用自定义名称创建 IAM 资源。
8.选择Create stack(创建堆栈)。
测试解决方案
要测试解决方案,请以账户 A 身份登录,在 DynamoDB 表中插入一个新项目,然后更新该项目。确保您与该表位于同一个区域。
1. 在 CloudShell 控制台上,输入以下 AWS CLI 命令以插入项目:
2. 使用以下代码更新现有项目:
3. 退出账户 A 并以账户 B 身份登录,以验证将记录传输到数据湖的情况。
Amazon DynamoDB 表中的所有item级修改将被发送到 Kinesis 数据流(blog-srca-ddb-table-data-stream),该数据流将数据传输到账户 A 中的 Firehose 传输流(blog-srca-ddb-table-delivery-stream)。
您可以通过 Firehose 传输流的监控选项卡来监控已更新记录的处理情况。
您可以通过检查为账户 B 创建的 S3 存储桶中的对象来验证向数据湖传输更新的情况。
Firehose 传输流的配置与之前的使用案例类似。

您可以通过相同的方式验证数据(JSON 格式):
- 下载文件
- 运行 AWS Glue 爬网程序来创建一个表,用于在 Athena 中查询
- 使用 Amazon S3 Select 查询数据。
清理
为避免将来产生费用,请清理您使用 AWS CloudFormation 创建的所有 AWS 资源。您可以通过控制台或 AWS CLI 删除这些资源。在本文中,我们将讲解通过控制台删除资源的各个步骤。
清理使用案例 1 中的资源
要清理同一账户中的 Amazon DynamoDB 和 Amazon S3 资源,请完成以下步骤:
- 在 Amazon S3 控制台上,清空 S3 存储桶并删除 S3 对象的任何先前版本。
- 在 Amazon CloudFormation 控制台上,删除堆栈 bdb1040-ddb-lake-single-account-stack。
在删除堆栈之前,必须先删除 Amazon S3 资源,否则删除操作将失败。
清理使用案例 2 中的资源
要清理不同账户中的 DynamoDB 和 Amazon S3 资源,请完成以下步骤:
- 登录账户 A
- 在 Amazon CloudFormation 控制台上,删除堆栈 bdb1040-ddb-lake-multi-account-stack。
- 登录账户 B.
- 在 Amazon S3 控制台上,清空 S3 存储桶并删除 S3 对象的任何先前版本。
- 在 Amazon CloudFormation 控制台上,删除堆栈 bdb1040-ddb-lake-multi-account-stack。
扩展解决方案
您可以扩展此解决方案,将Amazon DynamoDB 表数据流式传输到跨区域的 S3 存储桶,具体方法是在Amazon Kinesis Data Firehose 传输数据的存储桶上设置跨区域复制(使用受保护的 Amazon 私有渠道)。
在设置 DynamoDB Kinesis streams 之前,您还可以在某个时间点将 DynamoDB 表初始加载到数据湖。Amazon DynamoDB 提供了执行这一操作所需的功能,无需编码。有关更多信息,请参阅在 Amazon S3 中将 Amazon DynamoDB 表数据导出到您的数据湖,无需编写代码。
要扩展Amazon S3 存储桶中 DynamoDB 数据的可用性范围,可以对该位置进行爬取,以创建 Amazon Glue Data Catalog 数据库表。使用 Amazon Lake Formation 注册位置有助于简化权限管理,使您能够执行精细的访问控制。您还可以使用 Athena、Amazon Redshift、 Amazon SageMaker 和 Amazon QuickSight 进行数据分析、机器学习和报告服务。
结论
在本文中,我们演示了将Amazon DynamoDB 表数据流式传输到 Amazon S3 的两种解决方案,以使用安全的私有渠道构建数据湖。
Amazon CloudFormation 模板为您提供了一种设置流程的简单方法,您可以根据具体的使用案例需求进一步修改该模板。
如果您对本文有任何意见和建议,请与我们分享!