AWS News Blog
New – Export Amazon DynamoDB Table Data to Your Data Lake in Amazon S3, No Code Writing Required

|
Hundreds of thousands of AWS customers have chosen Amazon DynamoDB for mission-critical workloads since its launch in 2012. DynamoDB is a nonrelational managed database that allows you to store a virtually infinite amount of data and retrieve it with single-digit-millisecond performance at any scale.
To get the most value out of this data, customers had to rely on AWS Data Pipeline, Amazon EMR, or other solutions based on DynamoDB Streams. These solutions typically require building custom applications with high read throughput, resulting in expensive maintenance and operational costs.
Today we are launching a new functionality that allows you to export DynamoDB table data to Amazon Simple Storage Service (Amazon S3) – no code writing required.
This is a new native feature of DynamoDB, so it works at any scale without having to manage servers or clusters and allows you to export data across AWS Regions and accounts to any point-in-time in the last 35 days at a per-second granularity. Plus, it doesn’t affect the read capacity or the availability of your production tables.
Once your data is exported to S3 — in DynamoDB JSON or Amazon Ion format — you can query or reshape it with your favorite tools such as Amazon Athena, Amazon SageMaker, and AWS Lake Formation.
In this article, I’ll show you how to export a DynamoDB table to S3 and query it via Amazon Athena with standard SQL.
Exporting Your DynamoDB Table to an S3 Bucket
The export process relies on the ability of DynamoDB to continuously back up your data under the hood. This functionality is called continuous backups: It enables point-in-time recovery (PITR) and allows you to restore your table to any point in time in the last 35 days.
You can start by clicking Export to S3 in the Streams and exports tab.

Unless you’ve already enabled continuous backups, in the next page you must enable them by clicking Enable PITR.
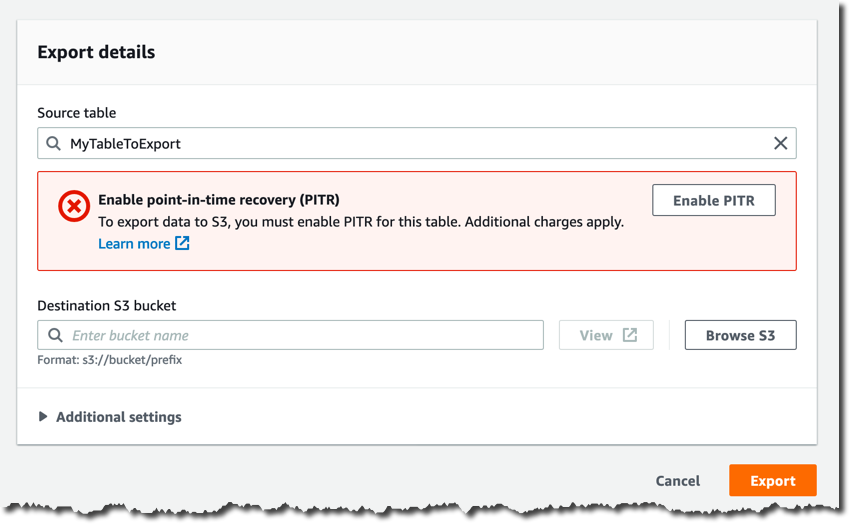
You provide your bucket name in Destination S3 bucket, for example s3://my-dynamodb-export-bucket. Keep in mind that your bucket could also be in another account or another region.
Feel free to have a look at the Additional settings, here’s where you can configure a specific point in time, the output format, and the encryption key. I’m going to use the default settings.

Now you can confirm the export request by clicking Export.
The export process begins and you can monitor its status in the Streams and exports tab.

Once the export process completes, you’ll find a new AWSDynamoDB folder in your S3 bucket and a sub-folder corresponding to the Export ID.
This is what the content of that sub-folder looks like.

You will find two manifest files that allow you to verify the integrity and discover the location of the S3 objects in the data sub-folder, which have been compressed and encrypted for you automatically.
How to Automate the Export Process via AWS CLI
If you want to automate the export process, for example to create a new export every week or every month, you can create a new export request via the AWS Command Line Interface (AWS CLI) or AWS SDKs by invoking the ExportTableToPointInTime API.
Here’s an example with the CLI.
aws dynamodb export-table-to-point-in-time \
--table-arn TABLE_ARN \
--s3-bucket BUCKET_NAME \
--export-time 1596232100 \
--s3-prefix demo_prefix \
-export-format DYNAMODB_JSON
{
"ExportDescription": {
"ExportArn": "arn:aws:dynamodb:REGUIB:ACCOUNT_ID:table/TABLE_NAME/export/EXPORT_ID",
"ExportStatus": "IN_PROGRESS",
"StartTime": 1596232631.799,
"TableArn": "arn:aws:dynamodb:REGUIB:ACCOUNT_ID:table/TABLE_NAME",
"ExportTime": 1596232100.0,
"S3Bucket": "BUCKET_NAME",
"S3Prefix": "demo_prefix",
"ExportFormat": "DYNAMODB_JSON"
}
}After requesting an export, you’ll have to wait until the ExportStatus is “COMPLETED”.
aws dynamodb list-exports
{
"ExportSummaries": [
{
"ExportArn": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/TABLE_NAME/export/EXPORT_ID",
"ExportStatus": "COMPLETED"
}
]
}Analyzing the Exported Data with Amazon Athena
Once your data is safely stored in your S3 bucket, you can start analyzing it with Amazon Athena.
You’ll find many gz-compressed objects in your S3 bucket, each containing a text file with multiple JSON objects, one per line. These JSON objects correspond to your DynamoDB items wrapped into an Item field, and with a different structure based on which export format you chose.
In the export process above, I’ve chosen DynamoDB JSON, and items in my sample table represent users of a simple game, so a typical object looks like the following.
{
"Item": {
"id": {
"S": "my-unique-id"
},
"name": {
"S": "Alex"
},
"coins": {
"N": "100"
}
}
}In this example, name is a string and coins is a number.
I’d recommend using AWS Glue crawlers to autodiscover the schema of your data and to create a virtual table in your AWS Glue catalog.
But you could also define a virtual table manually with a CREATE EXTERNAL TABLE statement.
CREATE EXTERNAL TABLE IF NOT EXISTS ddb_exported_table (
Item struct <id:struct<S:string>,
name:struct<S:string>,
coins:struct<N:string>>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://my-dynamodb-export-bucket/AWSDynamoDB/{EXPORT_ID}/data/'
TBLPROPERTIES ( 'has_encrypted_data'='true');Now you can query it with regular SQL, or even define new virtual tables with Create Table as Select (CTAS) queries.
With the DynamoDB JSON format, your query looks like this.
SELECT
Item.id.S as id,
Item.name.S as name,
Item.coins.N as coins
FROM ddb_exported_table
ORDER BY cast(coins as integer) DESC;And you get a result set as output.

Performance and Cost Considerations
The export process is serverless, it scales automatically and it’s a lot faster than custom table-scan solutions.
The completion time depends on the size of your table and how uniform data is distributed in the table. The majority of exports complete in under 30 minutes. For small tables up to 10 GiB, it should take just a few minutes; for very large tables on the order of terabytes, it might take a few hours. This shouldn’t be an issue because you wouldn’t use a data lake export for real-time analytics. Typically, data lakes are used to aggregate data at scale and generate daily, weekly, or monthly reports. So in most cases you can afford to wait a few minutes or hours for the export process to complete before you proceed with your analytics pipeline.
Thanks to the serverless nature of this new functionality, there is no hourly cost: You pay only for the gigabytes of data exported to Amazon S3 – for example, $0.10 per GiB in the US East region.
Because data is exported to your own S3 bucket and continuous backups are a prerequisite of the export process, remember that you’ll incur additional costs related to DynamoDB PITR backups and Amazon S3 data storage. All the cost components involved only depend on the amount of data you’re exporting. So the overall cost is easy to estimate, and much lower than the total cost of ownership of building custom solutions with high-read throughput and expensive maintenance.
Available Now
This new feature is available in every AWS Region where continuous backups are available.
You can make export requests using the AWS Management Console, the AWS Command Line Interface (AWS CLI) and the AWS SDKs. This feature allows developers, data engineers and data scientists to easily extract and analyze data from DynamoDB tables without designing and building custom and expensive applications for ETL (extract, transform, load).
You can now connect your in-house analytical tools to DynamoDB data, leveraging services like Amazon Athena for ad hoc analysis, Amazon QuickSight for data exploration and visualization, Amazon Redshift and Amazon SageMaker for predictive analysis, and much more.
Learn all the details about Amazon DynamoDB and get started with the new feature today.
— Alex