AWS Architecture Blog
Insights for CTOs: Part 3 – Growing your business with modern data capabilities
This post was co-wrtiten with Jonathan Hwang, head of Foundation Data Analytics at Zendesk.
In my role as a Senior Solutions Architect, I have spoken to chief technology officers (CTOs) and executive leadership of large enterprises like big banks, software as a service (SaaS) businesses, mid-sized enterprises, and startups.
In this 6-part series, I share insights gained from various CTOs and engineering leaders during their cloud adoption journeys at their respective organizations. I have taken these lessons and summarized architecture best practices to help you build and operate applications successfully in the cloud. This series also covers building and operating cloud applications, security, cloud financial management, modern data and artificial intelligence (AI), cloud operating models, and strategies for cloud migration.
In Part 3, I’ve collaborated with the head of Foundation Analytics at Zendesk, Jonathan Hwang, to show how Zendesk incrementally scaled their data and analytics capabilities to effectively use the insights they collect from customer interactions. Read how Zendesk built a modern data architecture using Amazon Simple Storage Service (Amazon S3) for storage, Apache Hudi for row-level data processing, and AWS Lake Formation for fine-grained access control.
Why Zendesk needed to build and scale their data platform
Zendesk is a customer service platform that connects over 100,000 brands with hundreds of millions of customers via telephone, chat, email, messaging, social channels, communities, review sites, and help centers. They use data from these channels to make informed business decisions and create new and updated products.
In 2014, Zendesk’s data team built the first version of their big data platform in their own data center using Apache Hadoop for incubating their machine learning (ML) initiative. With that, they launched Answer Bot and Zendesk Benchmark report. These products were so successful they soon overwhelmed the limited compute resources available in the data center. By the end of 2017, it was clear Zendesk needed to move to the cloud to modernize and scale their data capabilities.
Incrementally modernizing data capabilities
Zendesk built and scaled their workload to use data lakes on AWS, but soon encountered new architecture challenges:
- The General Data Protection Regulation (GDPR) “right to be forgotten” rule made it difficult and costly to maintain data lakes, because deleting a small piece of data required reprocessing large datasets.
- Security and governance was harder to manage when data lake scaled to a larger number of users.
The following sections show you how Zendesk is addressing GDPR rules by evolving from plain Apache Parquet files on Amazon S3 to Hudi datasets on Amazon S3 to enable row level inserts/updates/deletes. To address security and governance, Zendesk is migrating to AWS Lake Formation centralized security for fine-grained access control at scale.
Zendesk’s data platform
Figure 1 shows Zendesk’s current data platform. It consists of three data pipelines: “Data Hub,” “Data Lake,” and “Self Service.”

Figure 1. Zendesk data pipelines
Data Lake pipelines
The Data Lake and Data Hub pipelines cover the entire lifecycle of the data from ingestion to consumption.
The Data Lake pipelines consolidate the data from Zendesk’s highly distributed databases into a data lake for analysis.
Zendesk uses Amazon Database Migration Service (AWS DMS) for change data capture (CDC) from over 1,800 Amazon Aurora MySQL databases in eight AWS Regions. It detects transaction changes and applies them to the data lake using Amazon EMR and Hudi.
Zendesk ticket data consists of over 10 billion events and petabytes of data. The data lake files in Amazon S3 are transformed and stored in Apache Hudi format and registered on the AWS Glue catalog to be available as data lake tables for analytics querying and consumption via Amazon Athena.
Data Hub pipelines
The Data Hub pipelines focus on real-time events and streaming analytics use cases with Apache Kafka. Any application at Zendesk can publish events to a global Kafka message bus. Apache Flink ingests these events into Amazon S3.
The Data Hub provides high-quality business data that is highly available and scalable.
Self-managed pipeline
The self-managed pipelines empower product engineering teams to use the data lake for those use cases that don’t fit into our standard integration patterns. All internal Zendesk product engineering teams can use standard tools such as Amazon EMR, Amazon S3, Athena, and AWS Glue to publish their own analytics dataset and share them with other teams.
A notable example of this is Zendesk’s fraud detection engineering team. They publish their fraud detection data and findings through our self-manage data lake platform and use Amazon QuickSight for visualization.
You need fine-grained security and compliance
Data lakes can accelerate growth through faster decision making and product innovation. However, they can also bring new security and compliance challenges:
- Visibility and auditability. Who has access to what data? What level of access do people have and how/when and who is accessing it?
- Fine-grained access control. How do you define and enforce least privilege access to subsets of data at scale without creating bottlenecks or key person/team dependencies?
Lake Formation helps address these concerns by auditing data access and offering row- and column-level security and a delegated access control model to create data stewards for self-managed security and governance.
Zendesk used Lake Formation to build a fine-grained access control model that uses row-level security. It detects personally identifiable information (PII) while scaling the data lake for self-managed consumption.
Some Zendesk customers opt out of having their data included in ML or market research. Zendesk uses Lake Formation to apply row-level security to filter out records associated with a list of customer accounts who have opted out of queries. They also help data lake users understand which data lake tables contain PII by automatically detecting and tagging columns in the data catalog using AWS Glue’s PII detection algorithm.
The value of real-time data processing
When you process and consume data closer to the time of its creation, you can make faster decisions. Streaming analytics design patterns, implemented using services like Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Amazon Kinesis, create an enterprise event bus to exchange data between heterogeneous applications in near real time.
For example, it is common to use streaming to augment the traditional database CDC ingestion into the data lake with additional streaming ingestion of application events. CDC is a common data ingestion pattern, but the information can be too low level. This requires application context to be reconstructed in the data lake and business logic to be duplicated in two places, inside the application and in the data lake processing layer. This creates a risk of semantic misrepresentation of the application context.
Zendesk faced this challenge with their CDC data lake ingestion from their Aurora clusters. They created an enterprise event bus built with Apache Kafka to augment their CDC with higher-level application domain events to be exchanged directly between heterogeneous applications.
Zendesk’s streaming architecture
A CDC database ticket table schema can sometimes contain unnecessary and complex attributes that are application specific and do not capture the domain model of the ticket. This makes it hard for downstream consumers to understand and use the data. A ticket domain object may span several database tables when modeled in third normal form, which makes querying for analysts difficult downstream. This is also a brittle integration method because downstream data consumers can easily be impacted when the application logic changes, which makes it hard to derive a common data view.
To move towards event-based communication between microservices, Zendesk created the Platform Data Architecture (PDA) project, which uses a standard object model to represent a higher level, semantic view of their application data. Standard objects are domain objects designed for cross-domain communication and do not suffer from the lower level fragmented scope of database CDC. Ultimately, Zendesk aims to transition their data architecture from a collection of isolated products and data silos into a cohesive unified data platform.
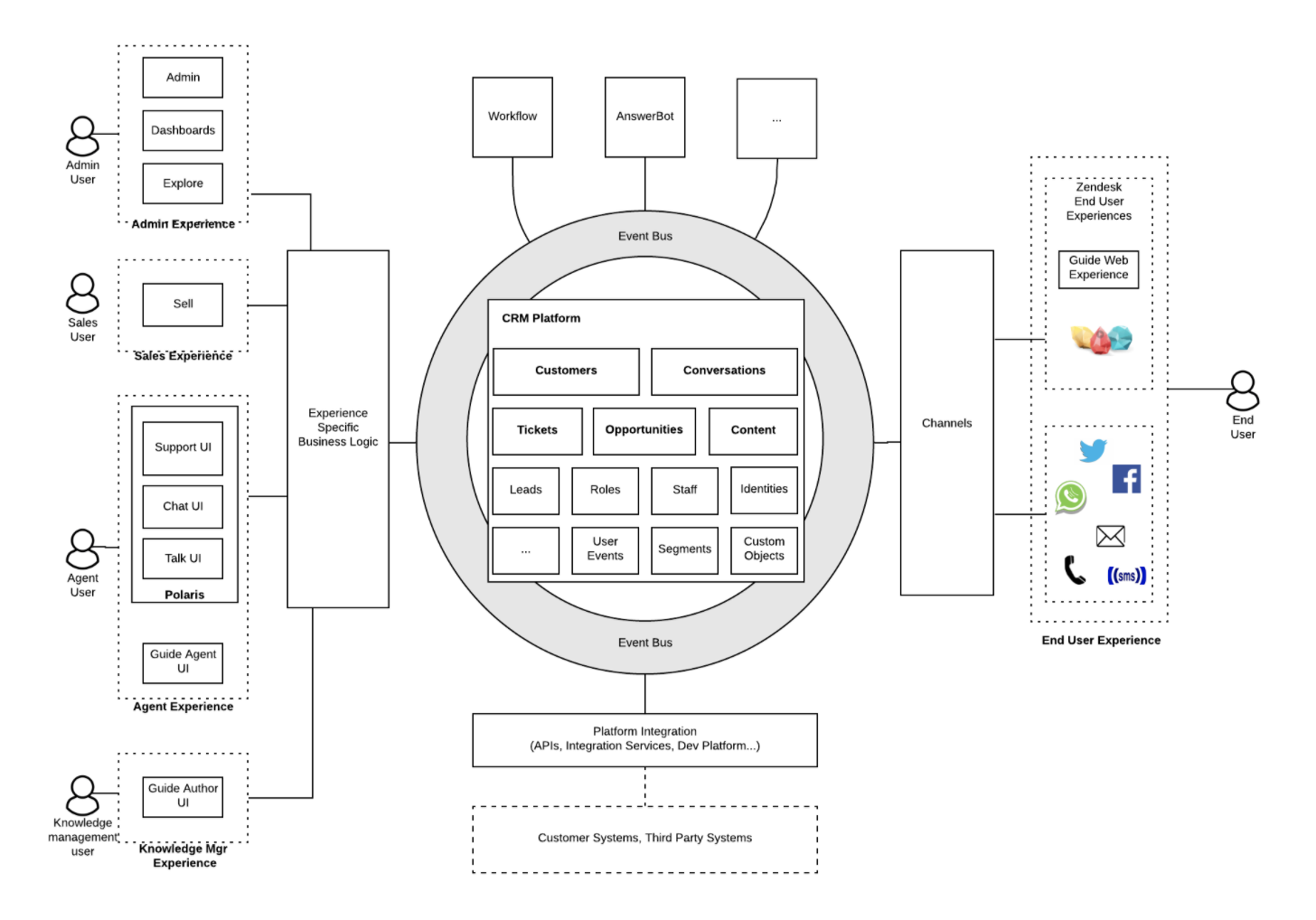
Figure 2. An application view of Zendesk’s streaming architecture
Figure 3 shows how all Zendesk products and users integrate through common standard objects and standard events within the Data Hub. Applications publish and consume standard objects and events to/from the event bus.
For example, a complete ticket standard object will be published to the message bus whenever it is created, updated, or changed. On the consumption side, these events get used by product teams to enable platform capabilities such as search, data export, analytics, and reporting dashboards.
Summary
As Zendesk’s business grew, their data lake evolved from simple Parquet files on Amazon S3 to a modern Hudi-based incrementally updateable data lake. Now, their original coarse-grained IAM security policies use fine-grained access control with Lake Formation.
We have repeatedly seen this incremental architecture evolution achieve success because it reduces the business risk associated with the change and provides sufficient time for your team to learn and evaluate cloud operations and managed services.
Looking for more architecture content? AWS Architecture Center provides reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more!