AWS Database Blog
Cross-Region Automatic Disaster Recovery on Amazon RDS for Oracle Database Using DB Snapshots and AWS Lambda
Sameer Malik is a specialist solutions architect and Christian Williams is an enterprise solutions architect at Amazon Web Services.
Many AWS users are taking advantage of the managed service offerings that are available in the AWS portfolio to remove much of the undifferentiated heavy lifting from their day-to-day activities. Amazon Relational Database Service (Amazon RDS) is one of the managed services for your relational database deployments. With Amazon RDS, you can significantly reduce the administrative overhead of managing and maintaining a relational database.
There are multiple ways to implement disaster recovery (DR) solutions, depending on the Recovery Time Objective (RTO) and Recovery Point Objective (RPO), costing, and the administrative tasks involved in setting up and maintaining the DR site. This post covers setting up cross-region DR with the “backup and restore” method, which is a cost-effective DR strategy that meets less stringent RTO/RPOs. (For more information, see the RTO and RPO considerations at the end of this post.)
Backup and restore DR solution overview
In this post, we describe how to automate the cross-region DR process for Amazon RDS for Oracle Database using the backup and restore DR method. This strategy uses the Amazon EBS snapshot mechanism (both Amazon RDS system-generated automated and manual snapshots). It also uses a small set of AWS tools, such as Amazon RDS events, Amazon SNS topics, and AWS Lambda functions. The final state is an automated architecture that does the following:
- Takes snapshots based on a user-defined schedule.
- Copies the snapshots to a second DR Region (frequency of snapshot copying is determined based on the RPO requirement).
- Restores the latest snapshot to spin up another Amazon RDS for Oracle Database instance on the DR Region in the event of a failure in the primary Region.
The process is shown in the following diagram:
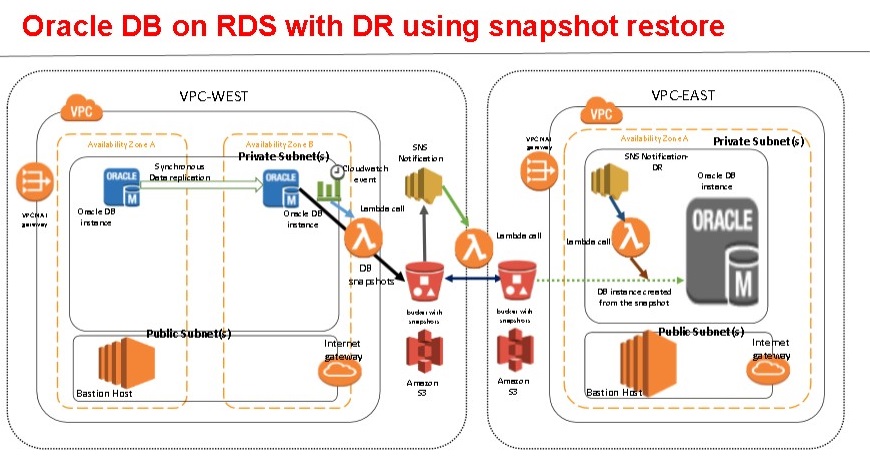
The following are the necessary steps described in this post:
- Create Amazon SNS topics to subscribe to the Amazon RDS event notifications (in the next step).
- Enable Amazon RDS event notifications on the primary database.
- Create Lambda functions to do the following:
- Initiate snapshot creation of the primary database.
- Copy the newly created snapshot to the DR Region.
- Restore the copied snapshot in the DR Region in the event of a failure.
- Enable Amazon CloudWatch Events to schedule the initial snapshot creation based on your RTO requirements.
- Optional: Create an additional Lambda function to delete old snapshots.
Step 1: Creating Amazon SNS topics
Start off by creating two Amazon SNS topics that you can then use to subscribe to specific Amazon RDS events (in step 2). Make sure that you are in the Region in which your primary database is located. Create an Amazon SNS topic named DB_Snapshot_initiated_primary_region and a second topic named DB_availability_error_primary_region.
Step 2: Enabling Amazon RDS event notifications
Now it’s time to enable Amazon RDS event notifications. We are interested in backup events and availability events that relate to the operational status of the primary DB.
The following screenshot illustrates how to select specific events for your Amazon RDS instance. Make sure that you use the topics created under step 1 to subscribe to the availability and backup event categories for your specific DB instance.
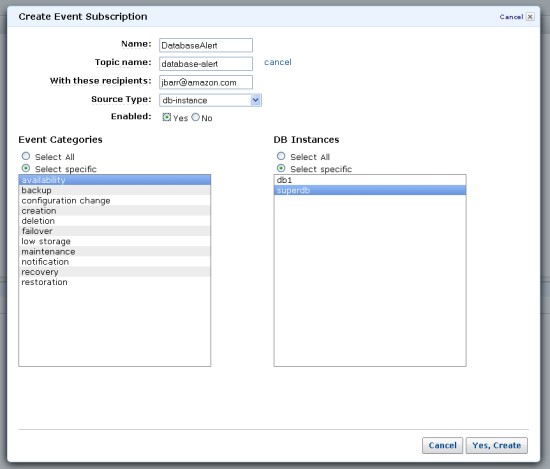
Note: You can choose the DR event from any of the existing Amazon RDS event notifications to trigger your DR. In this example, we chose this event as a trigger to simulate the DR event. This event is generally fired when Amazon RDS can’t resolve an issue with a database automatically
Step 3: Creating Lambda functions
Now you can use the Amazon SNS topic to initiate the Lambda functions automatically. Before you do this, make sure that you create a role with sufficient IAM permissions to start, copy, and restore Amazon RDS snapshots. The following is an example policy. Be sure to use security’s “least privilege” principle when granting permissions. This example uses "Resource": "*".
Important: This example is for demonstration only, and a more granular resource identifier should be used in production environments.
Step 3a: Initiating snapshot creation
The next step is to deploy the Lambda functions to facilitate the invocation of snapshot creation, snapshot copying, and snapshot restoration in Region 2. This specific deployment uses Python 2.7 as the language for the Lambda functions.
The following is the sample code for the snapshot creation function:
Step 3b: Copying the snapshot to the DR Region.
Next, you create a Lambda function to copy the newly created snapshot to Region 2. In this step, you follow the same configuration settings as in the previous Lambda function and use the same language (Python 2.7), in addition to selecting the same settings for the Lambda role.
Step 3c: Restoring the snapshot in the DR Region in case of failure
Next, you have to deploy the restore Lambda function to create a DB that is based on the snapshot that was copied from Region 1 to Region 2. You can deploy this function in the DR Region since Amazon SNS topics can be used to trigger Lambda functions in other Regions.
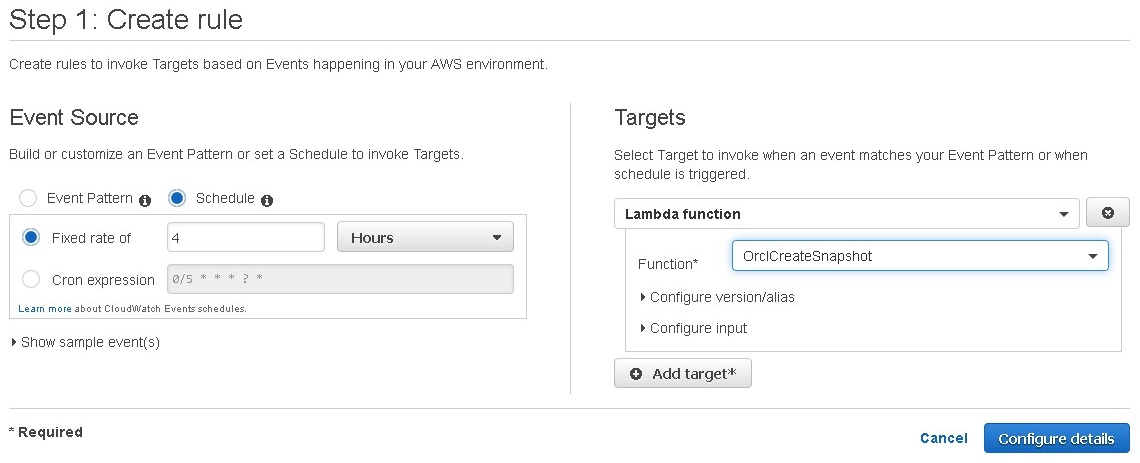
Step 4: Scheduling snapshot creation
Finally, specify a schedule for your recurring snapshot creation.
As expected, databases that are relatively large may require additional time to create a snapshot and to copy that snapshot to the second Region. To execute the initial snapshot creation Lambda function on a recurring schedule, you can use CloudWatch Events. The following is an example of setting up a recurring schedule for every four hours to invoke the snapshot creation Lambda function (OrclCreateSnapshot).
Step 5: Deleting old snapshots (optional)
If you want to keep only a certain number of snapshots within each Region, you can use the following Lambda function to delete old snapshots based on your retention requirements. This example deletes snapshots that are older than six days.
RPO and RTO considerations
RPO – It’s important to mention that the initial snapshot creation needs to finish before the database instance can return to the “available state“ again. This “available state” is the required state for the DB instance to accept a new snapshot creation request. So we recommend that you choose a schedule in CloudWatch Events that allows for the completion of the snapshot creation request before invoking another Lambda function with CloudWatch Events. We highly recommend that you time the creation of a manual snapshot on your primary instance to get a metric for the minimum RPO value possible in your environment.
RTO – This is determined by many factors within your architecture, such as the size of your database, the distance between the two Regions, the instance type that you chose to restore your database, etc. Because of the sheer number of variables at play when calculating the “average” RTO, we highly recommend testing your DR solution to get a valid estimate that is specific to your use case.
Cost considerations:
The two primary factors that contribute to the cost of this solution are storage cost for the snapshots and data transfer cost to copy the snapshots between the two Regions.
As far as storage cost is concerned, there is no additional charge for backup storage of up to 100 percent of your total database storage for a Region. Since we don’t have an Amazon RDS instance in the secondary (DR) Region, you incur backup storage cost for the snapshots in Amazon S3, which are billed at standard Amazon S3 rates. Additionally, you also incur data transfer cost to copy the snapshot from Amazon S3 in Region 1 to Region 2.
For a comprehensive cost estimate, use the free Simple Monthly Calculator.
Summary
As you can see from the steps described in this post, it’s fairly easy to deploy an automated DR solution for Amazon RDS for Oracle Database on AWS. It is important to mention that creating a DB snapshot on a Single-AZ DB instance results in a brief I/O suspension that can last from a few seconds to a few minutes, depending on the size and class of your DB instance. If you plan to use a very small RPO and take multiple backups during the day, we highly recommend that you use high-availability (Multi-AZ) DB instances. They are not affected by this I/O suspension since the backup is taken on the standby.
Finally, take a look at the current limits on manual snapshots for Amazon RDS, which is currently 100 manual snapshots per account. To avoid maintaining too many snapshots, use the Lambda function under step 5 and run it with CloudWatch Events on a predetermined schedule.
We hope you found this blog post useful, and we’re looking forward to learning how you implemented these suggestions in your specific workload.