Artificial Intelligence
Introducing Dynamic Training for deep learning with Amazon EC2
Today we are excited to announce the availability of Dynamic Training (DT) for deep learning models, or DT for short. DT allows deep learning practitioners to reduce model training cost and time by leveraging the cloud’s elasticity and economies of scale. Our first reference implementation of DT is based on Apache MXNet, and is open sourced under Dynamic Training with Apache MXNet. This blog post introduces the concept of DT, showcases training results achieved, and demonstrates how you can get started leveraging it for your model training jobs.

Distributed Training of deep learning models
Training neural networks is a repetitive process in which the network is fed with batches of training data, the loss and the gradient are calculated, and model parameters are updated iteratively until a sufficient accuracy is achieved. For state-of-the-art deep learning models, the process becomes extremely computationally intensive as both the number of model parameters and the number of training samples becomes extremely large. For example, ResNet-50 [1], a modern image classification model, contains around 25 million parameters, and the IMAGENET labeled dataset, often used to train models such as ResNet-50, contains more than 14 million images, while industry datasets are often 10 times larger. Indeed, training a network such as ResNet-50 with the IMAGENET dataset on a single host can take days. To reduce the training time of deep networks, practitioners typically use distributed training, which distributes the training job across multiple hosts, thus reducing the overall training time. Distributed multi-host training is supported in modern deep learning frameworks such as Apache MXNet and TensorFlow. It can be used to reduce training time significantly: The team at Sony recently demonstrated training ResNet50 on IMAGENET in 224 seconds using 2176 Nvidia Tesla V100 GPUs.
Introducing Dynamic Training
Traditional distributed training requires a fixed number of hosts that are actively participating in the training job throughout the training process. With DT, this requirement is relaxed: the number of hosts in the training cluster is allowed to fluctuate, growing and shrinking throughout the training process. This relaxed property of DT enables training jobs to leverage key advantages of the cloud: compute elasticity and cost reduction. The AWS Cloud provides rapid access to flexible and low-cost IT resources such as compute, and allows customers to benefit from the cloud’s massive economies of scale through products such as Amazon Elastic Compute Cloud (EC2) Spot Instances. Spot Instances offer spare compute capacity in the AWS Cloud at steep discounts, up to 90 percent, compared to standard On-Demand Instances.
With DT, practitioners running compute-intensive training jobs can benefit from these economies of scale, and reduce training costs by pulling in Spot Instances when available, and releasing them when they are interrupted, all without stopping the training job. DT allows practitioners to cut down on model training cost significantly, as well as reduce training time by increasing the training cluster size when possible.
In addition, DT enables practitioners to better utilize their organization’s pool of Amazon EC2 Reserved Instances. Practitioners can pull Reserved Instances into the training job when available, and release instances back to the Reserved Instances pool when instances are required for other, more critical applications, all while allowing the training job to continue without interruption. The following diagram shows the DT process using the Reserved Instances pool.

Dynamic Training of ResNet-50 with Apache MXNet
Now let’s go over some results. With our implementation of Dynamic Training with Apache MXNet, we were able to train ResNet-50 v1 [1], a deep convolutional model for image classification, on the IMAGENET dataset, without loss of accuracy. The elastic training job used a pool of P3.16xlarge instances, each consisting of 8 Tesla V100 GPUs. Throughout the 90 epochs training process, the number of hosts in the training cluster fluctuated up and down between 8 GPUs and 96 GPUs.
Because the number of hosts may be changed across training epochs, DT fixes the total batch size, while dynamically adjusting the mini-batch size per GPU based on the number of hosts participating in the given epoch. The following chart illustrates how the DT process utilized a dynamic training cluster, and how it performed compared to the baseline fixed cluster training. Note that both training sessions converged on the same target validation accuracy by the 90th epoch.
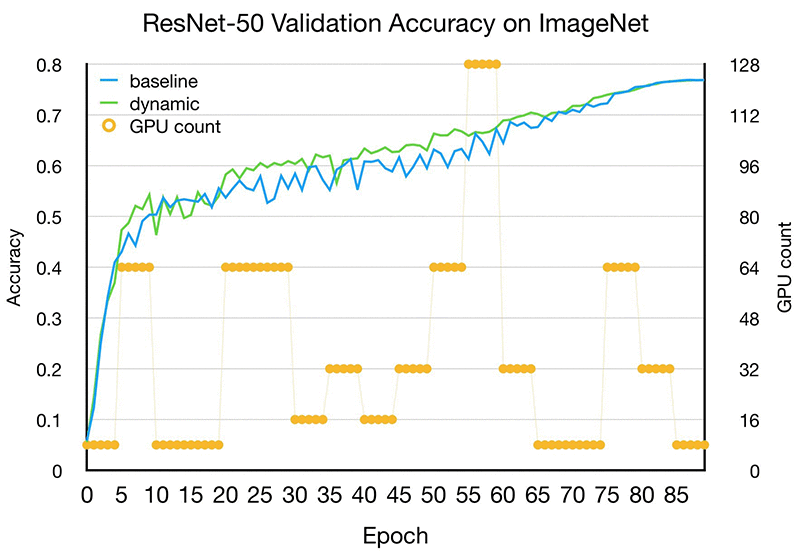
This example, alongside other experiments that we ran, demonstrated that DT reduces cost to train by 15 to 50 percent, and reduces time to train by 15 to 30 percent. The actual time and cost reductions vary because they depend on the model architecture, the training cluster setup, and the type of instances used.
“We are running computer vision models developed in MXNet to measure the freshness of waffle fries. To reduce the training time of neural networks, we wanted to use distributed training,” said Jay Duff, Management Consultant, Chick-Fil-A. “Dynamic Training with Apache MXNet on AWS allows us to better utilize the AWS infrastructure by elastically adding EC2 Spot and Reserved Instances to training jobs. We expect to reduce training costs by up to 20 percent.”
Getting started with Dynamic Training
To get started with DT with Apache MXNet, visit the GitHub repository, and follow the example. Currently, the implementation supports only Apache MXNet and EC2 Reserved Instances. We plan to add support for Spot Instances, as well as additional deep learning frameworks, in the future.
We’d love to hear your feedback and experience using DT to train your models. Your feedback on issues and your contributions on the GitHub repository are welcomed!
[1] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
About the authors
 Vikas Kumar – Vikas is Senior Software Engineer for AWS Deep Learning, focusing on building scalable deep learning systems. Prior to this Vikas has worked on building service discovery systems for microservices and databases. In his spare time he enjoys reading and music.
Vikas Kumar – Vikas is Senior Software Engineer for AWS Deep Learning, focusing on building scalable deep learning systems. Prior to this Vikas has worked on building service discovery systems for microservices and databases. In his spare time he enjoys reading and music.
 Haibin Lin – Haibin is a Software Development Engineer for AWS Deep Learning, focusing on distributed optimization and natural language processing. In his spare, he enjoys hiking and traveling.
Haibin Lin – Haibin is a Software Development Engineer for AWS Deep Learning, focusing on distributed optimization and natural language processing. In his spare, he enjoys hiking and traveling.
 Andrea Olgiati – Andrea is a Principal Engineer for AWS Deep Learning, focusing on building scalable machine learning systems. Prior to this, he worked on databases, compilers, and microchips. In his spare time he enjoys playing the piano and lifting heavy things.
Andrea Olgiati – Andrea is a Principal Engineer for AWS Deep Learning, focusing on building scalable machine learning systems. Prior to this, he worked on databases, compilers, and microchips. In his spare time he enjoys playing the piano and lifting heavy things.
 Mu Li – Mu Li is a principal scientist for machine learning at AWS. Before joining AWS, he was the CTO of Marianas Labs, an AI start-up. He also served as a principal research architect at the Institute of Deep Learning at Baidu. He obtained his PhD in computer science from Carnegie Mellon University. He enjoys spending time with his family.
Mu Li – Mu Li is a principal scientist for machine learning at AWS. Before joining AWS, he was the CTO of Marianas Labs, an AI start-up. He also served as a principal research architect at the Institute of Deep Learning at Baidu. He obtained his PhD in computer science from Carnegie Mellon University. He enjoys spending time with his family.
 Hagay Lupesko – Hagay is an Engineering Leader for AWS Deep Learning. He focuses on building deep learning systems that enable developers and scientists to build intelligent applications. In his spare time, he enjoys reading, hiking, and spending time with his family.
Hagay Lupesko – Hagay is an Engineering Leader for AWS Deep Learning. He focuses on building deep learning systems that enable developers and scientists to build intelligent applications. In his spare time, he enjoys reading, hiking, and spending time with his family.