Artificial Intelligence
Simplify continuous learning of Amazon Comprehend custom models using Comprehend flywheel
Amazon Comprehend is a managed AI service that uses natural language processing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. The ability to train custom models through the Custom classification and Custom entity recognition features of Comprehend has enabled customers to explore out-of-the-box NLP capabilities tied to their requirements without having to take the approach of building classification and entity recognition models from scratch.
Today, users invest a significant amount of resources to build, train, and maintain custom models. However, these models are sensitive to changes in the real world. For example, since 2020, COVID has become a new entity type that businesses need to extract from documents. In order to do so, customers have to retrain their existing entity extraction models with new training data that includes COVID. Custom Comprehend users need to manually monitor model performance to assess drifts, maintain data to retrain models, and select the right models that improve performance.
Comprehend flywheel is a new Amazon Comprehend resource that simplifies the process of improving a custom model over time. You can use a flywheel to orchestrate the tasks associated with training and evaluating new custom model versions. You can create a flywheel to use an existing trained model, or Amazon Comprehend can create and train a new model for the flywheel. Flywheel creates a data lake (in Amazon S3) in your account where all the training and test data for all versions of the model are managed and stored. Periodically, the new labeled data (to retrain the model) can be made available to flywheel by creating datasets. To incorporate the new datasets into your custom model, you create and run a flywheel iteration. A flywheel iteration is a workflow that uses the new datasets to evaluate the active model version and to train a new model version.
Based on the quality metrics for the existing and new model versions, you set the active model version to be the version of the flywheel model that you want to use for inference jobs. You can use the flywheel active model version to run custom analysis (real-time or asynchronous jobs). To use the flywheel model for real-time analysis, you must create an endpoint for the flywheel.
This post demonstrates how you can build a custom text classifier (no prior ML knowledge needed) that can assign a specific label to a given text. We will also illustrate how flywheel can be used to orchestrate the training of a new model version and improve the accuracy of the model using new labeled data.
Prerequisites
To complete this walkthrough, you need an AWS account and access to create resources in AWS Identity and Access Management (IAM), Amazon S3 and Amazon Comprehend within the account.
- Configure IAM user permissions for users to access flywheel operations (
CreateFlywheel,DeleteFlywheel,UpdateFlywheel,CreateDataset,StartFlywheelIteration). - (Optional) Configure permissions for AWS KMS keys for AWS KMS keys for the datalake.
- Create a data access role that authorizes Amazon Comprehend to access the datalake.
For information about creating IAM policies for Amazon Comprehend, see Permissions to perform Amazon Comprehend actions.
In this post, we use the Yahoo corpus from Text Understanding from scratch by Xiang Zhang and Yann LeCun. The data can be accessed from AWS Open Data Registry. Please refer to section 4, “Preparing data,” from the post Building a custom classifier using Amazon Comprehend for the script and detailed information on data preparation and structure.
Alternatively, for even more convenience, you can download the prepared data by entering the following two command lines:
We will be using the custom-classifier-partial-dataset.csv (about 15,000 documents) dataset to create the initial version of the custom classifier. Next, we will create a flywheel to orchestrate the retraining of the initial version of the model using the complete dataset custom-classifier-complete-dataset.csv (about 100,000 documents). Upon retraining the model by triggering a flywheel iteration, we evaluate the model performance metrics of the two versions of the custom model and choose the better-performing one as the active model version and demonstrate real-time custom classification using the same.
Solution overview
Please find the following steps to set up the environment and the data lake to create a Comprehend flywheel iteration to retrain the custom models.
- Setting up the environment
- Creating S3 buckets
- Training the custom classifier
- Creating a flywheel
- Configuring datasets
- Triggering flywheel iterations
- Update active model version
- Using flywheel for custom classification
- Cleaning up the resources
1. Setting up the environment
You can interact with Amazon Comprehend via the AWS Management Console, AWS Command Line Interface (AWS CLI), or Amazon Comprehend API. For more information, refer to Getting started with Amazon Comprehend.
In this post, we use AWS CLI to create and manage the resources. AWS Cloud9 is a cloud-based integrated development environment (IDE) that lets you write, run, and debug your code. It includes a code editor, debugger, and terminal. AWS Cloud9 comes prepackaged with AWS CLI.
Please refer to Creating an environment in AWS Cloud9 to set up the environment.
2. Creating S3 buckets
- Create two S3 buckets
- One for managing the datasets
custom-classifier-partial-dataset.csvandcustom-classifier-complete-dataset.csv. - One for the data lake for Comprehend flywheel.
- One for managing the datasets
- Create the first bucket using the following command (replace ‘123456789012’ with your account ID):
- Create the bucket to be used as the data lake for flywheel:
- Upload the training datasets to the “123456789012-comprehend” bucket:
3. Training the custom classifier
Use the following command to create a custom classifier: yahoo-answers-version1 using the dataset: custom-classifier-partial-dataset.csv. Replace the data access role ARN and the S3 bucket locations with your own.
The above API call results in the following output:
CreateDocumentClassifier starts the training of the custom classifier model. In order to further track the progress of the training, use DescribeDocumentClassifier.
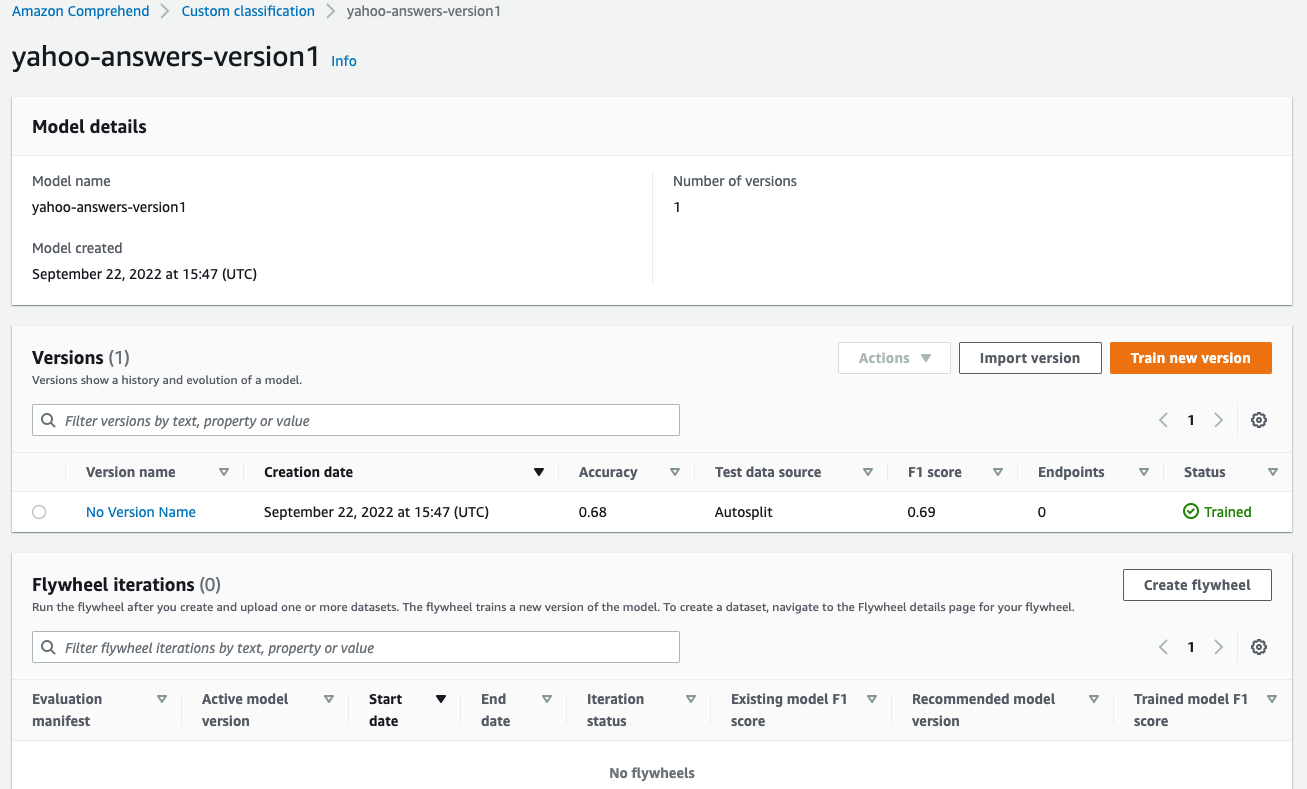
Console view of the initial version of the custom classifier as a result of the create-document-classifier command previously described
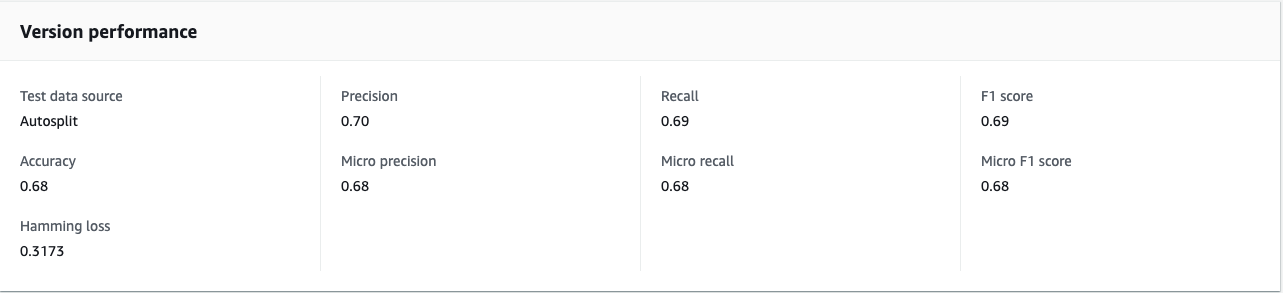
Model Performance
Once Status shows TRAINED, the classifier is ready to use. The initial version of the model has an F1-score of 0.69. F1-score is an important evaluation metric in machine learning. It sums up the predictive performance of a model by combining two otherwise competing metrics—precision and recall.
4. Create a flywheel
As the next step, create a new version of the model with the updated dataset (custom-classifier-complete-dataset.csv). For retraining, we will be using Comprehend flywheel to help orchestrate and simplify the process of retraining the model.
You can create a flywheel for an existing trained model (as in our case) or train a new model for the flywheel. When you create a flywheel, Amazon Comprehend creates a data lake to hold all the data that the flywheel needs, such as the training data and test data for each version of the model. When Amazon Comprehend creates the data lake, it sets up the following folder structure in the Amazon S3 location.
Warning: Amazon Comprehend manages the data lake folder organization and contents. If you modify the datalake folders, your flywheel may not operate correctly.
How to create a flywheel (for the existing custom model):
Note: If you create a flywheel for an existing trained model version, the model type and model configuration are preconfigured.
Be sure to replace the model ARN, data access role, and data lake S3 URI with your resource’s ARNs. Use the second S3 bucket 123456789012-comprehend-flywheel-datalake created in the “Setting up S3 buckets” step as the data lake for flywheel.
The above API call results in a FlyWheelArn.
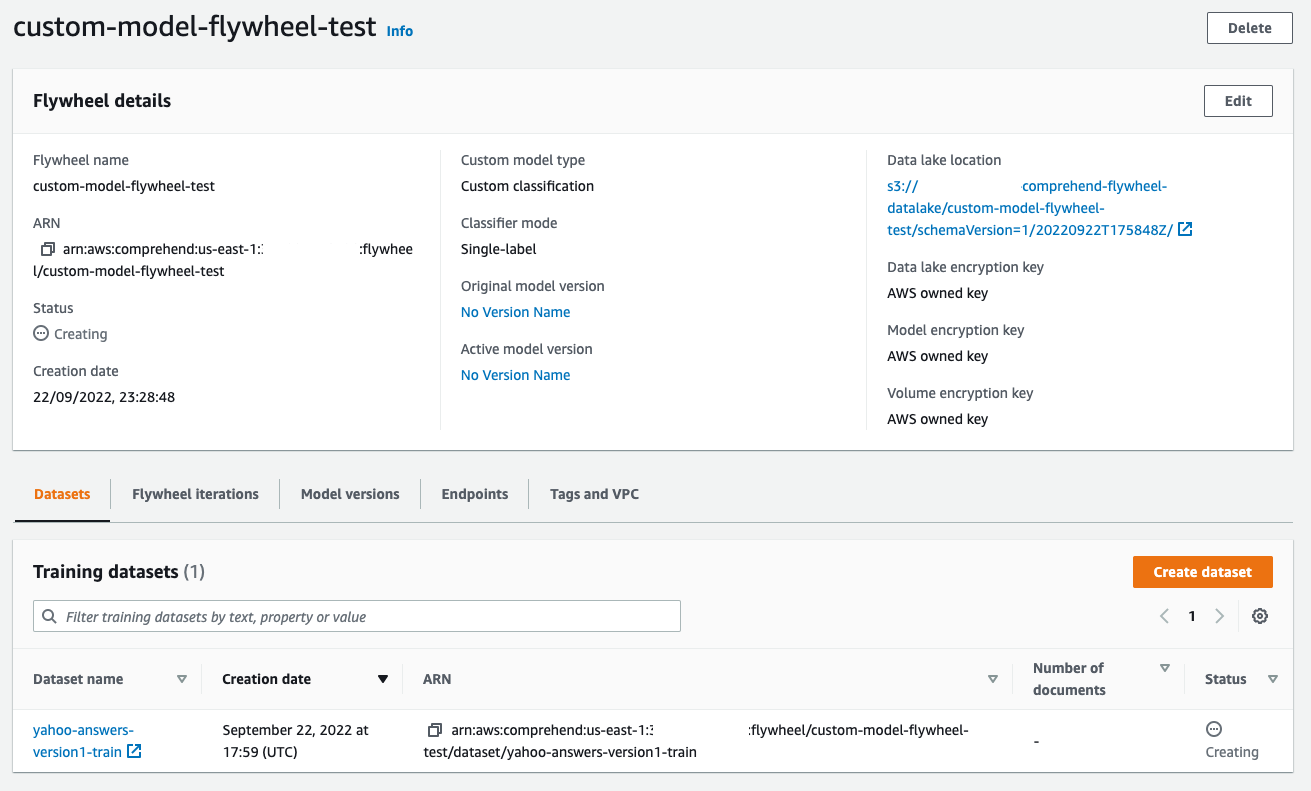
Console view of the flywheel
5. Configuring datasets
To add labeled training or test data to a flywheel, use the Amazon Comprehend console or API to create a dataset.
- Create an
inputConfig.jsonfile containing the following content: - Use the relevant flywheel ARN from your account to create the dataset.
- This results in the creation of a dataset:
6. Triggering flywheel iterations
Use flywheel iterations to help you create and manage new model versions. Users can also view per-dataset metrics in the “model stats” folder in the data lake in S3 bucket. Run the following command to start the flywheel iteration:
The response contains the following content :
When you run the flywheel, it creates a new iteration that trains and evaluates a new model version with the updated dataset. You can promote the new model version if its performance is superior to the existing active model version.
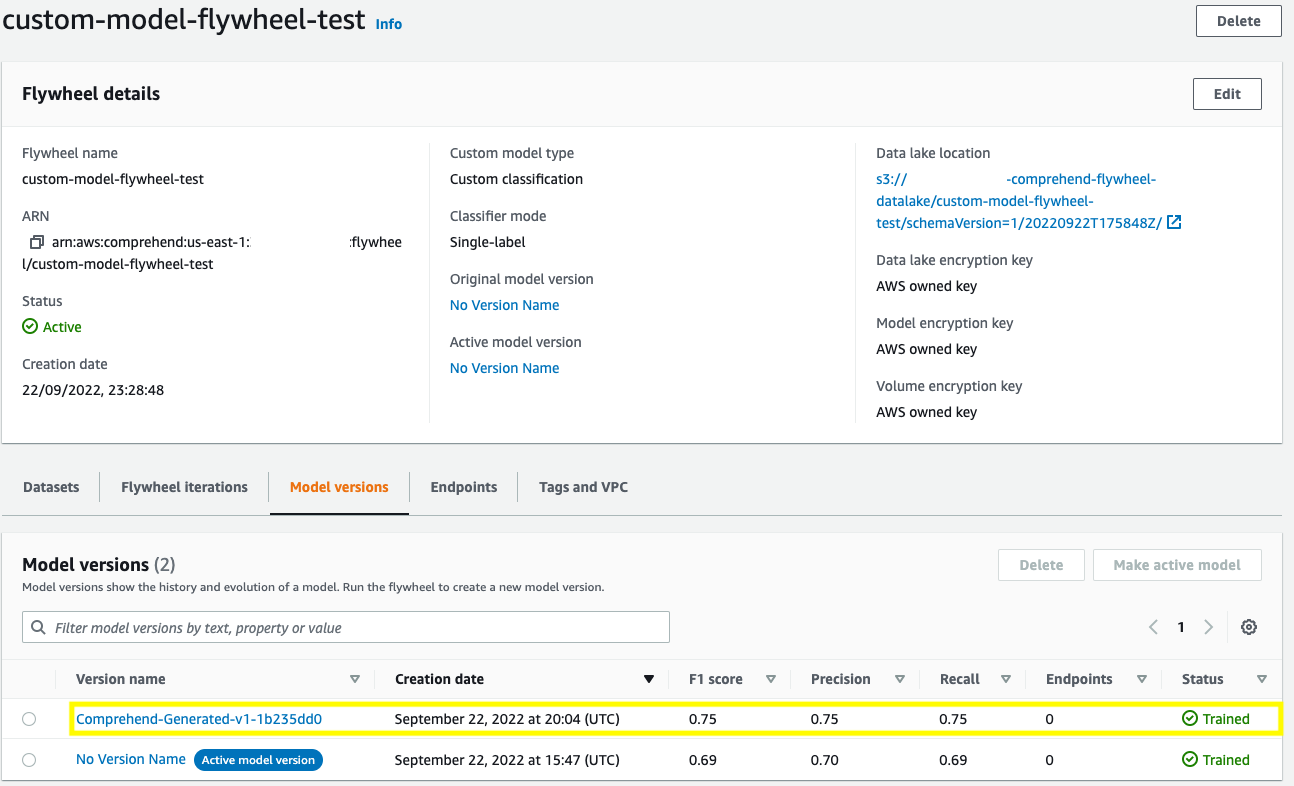
Result of the flywheel iteration
7. Update active model version
We notice that the model performance has improved as a result of the recent iteration (highlighted above). To promote the new model version as the active model version for inferences, use UpdateFlywheel API call:
The response contains the following contents, which shows that the newly trained model is being promoted as the active version:
8. Using flywheel for custom classification
You can use the flywheel’s active model version to run analysis jobs for custom classification. This can be for both real-time analysis or for asynchronous classification jobs.
- Asynchronous jobs: Use the StartDocumentClassificationJob API request to start an asynchronous job for custom classification. Provide the FlywheelArn parameter instead of the DocumentClassifierArn.
- Real-time analysis: You use an endpoint to run real-time analysis. When you create the endpoint, you configure it with the flywheel ARN instead of a model ARN. When you run the real-time analysis, select the endpoint associated with the flywheel. Amazon Comprehend runs the analysis using the active model version of the flywheel.
Run the following command to create the endpoint:
Warning: You will be charged for this endpoint from the time it is created until it is deleted. Ensure you delete the endpoint when not in use to avoid charges.
For API, use the ClassifyDocument API operation. Provide the endpoint of the flywheel for the EndpointArn parameter OR use the console to classify documents in real time.


Pricing details
Flywheel APIs are free of charge. However, you will be billed for custom model training and management. You are charged $3 per hour for model training (billed by the second) and $0.50 per month for custom model management. For synchronous custom classification and entities inference requests, you provision an endpoint with the appropriate throughput. For more details, please visit Comprehend Pricing.
9. Cleaning up the resources
As discussed, you are charged from the time that you start your endpoint until it is deleted. Once you no longer need your endpoint, you should delete it so that you stop incurring costs from it. You can easily create another endpoint whenever you need it from the Endpoints section. For more information, refer to Deleting endpoints.
Conclusion
In this post, we walked through the capabilities of Comprehend flywheel and how it simplifies the process of retraining and improving custom models over time. As part of the next steps, you can explore the following:
- Create and manage Comprehend flywheel resources from other mediums such as SDK and console.
- In this blog, we created a flywheel for an already trained custom model. You can explore the option of creating a flywheel and training a model for it from scratch.
- Use flywheel for custom entity recognizers.
There are many possibilities, and we are excited to see how you use Amazon Comprehend for your NLP use cases. Happy learning and experimentation!
About the Author
 Supreeth S Angadi is a Greenfield Startup Solutions Architect at AWS and a member of AI/ML technical field community. He works closely with ML Core , SaaS and Fintech startups to help accelerate their journey to the cloud. Supreeth likes spending his time with family and friends, loves playing football and follows the sport immensely. His day is incomplete without a walk and playing fetch with his ‘DJ’ (Golden Retriever).
Supreeth S Angadi is a Greenfield Startup Solutions Architect at AWS and a member of AI/ML technical field community. He works closely with ML Core , SaaS and Fintech startups to help accelerate their journey to the cloud. Supreeth likes spending his time with family and friends, loves playing football and follows the sport immensely. His day is incomplete without a walk and playing fetch with his ‘DJ’ (Golden Retriever).