Amazon Web Services ブログ
AI を活用したドローン画像による風力タービンの外観検査
本投稿は、Burak Gozluklu による記事 AI-Driven Visual Inspection of Wind Turbines Based on Drone Imaging を翻訳したものです。
はじめに
風力タービンを稼働状態に保つことは、適切にメンテナンスを続けることを意味します。メンテナンスのステップの1つは、定期的な外観検査です。 風力発電所の運用・保守を行う企業は、カメラ付きのドローンを利用した外観検査への取り組みを開始しています。 最近の調査によると、ドローンによる検査は、従来のロープを使った人間による検査と比較して、コストを最大70%削減し、ダウンタイムによる収益の損失を最大90%削減します。 さらに、ドローンでの作業は、ロープを利用した人間の高所作業よりもはるかに安全です。 これらの点から、お客様は検査プロセスの自動化に期待しています。 このブログ投稿では、検査プロセスを自動化するため、イベント駆動アーキテクチャの一部としての AI/ML ベースの画像認識について説明します。
このブログ投稿では、サーバーレステクノロジーで強化された AWS 機械学習サービスを外観検査に使用し、カスタムビジネスロジックに基づいた自動化プロセスを構築する方法を紹介します。AWS Rekognition カスタムラベルを使用して、お客様ごとに固有のオブジェクトやシーンを識別します。また、AI/ML ベースの検査に関する重要なメトリクスについても説明します。最後に、AWS サーバーレスアプリケーションモデル(AWS SAM) は、Amazon Rekognition の認識結果に基づいてビジネスロジックを構築するイベント駆動ソリューションのデプロイに役立ちます。
AI/ML ベースの画像認識
検査用画像認識タイプ
通常、画像認識には 3 つのタイプがあります。1 つ目は、マルチラベル画像分類です。マルチラベル画像分類では、画像を全体として扱い、シーンにラベルを付けます。たとえば、図1-a は、着氷したタービンの画像を示しています。したがって、ラベルの結果は「icing」となり、シーン全体に付与されます。このメソッドはシンプルで、他の方法に比べてトレーニングに必要なデータ量が最小限に抑えられます。2つ目は、バウンディングボックスによるオブジェクト検出です (図1-b)。このメソッドは、オブジェクトの識別だけでなくバウンディングボックスによるオブジェクトの位置情報を提供します。バウンディングボックスを使用したオブジェクト検出では、マルチラベル画像分類に比べて学習に必要なデータ量が増えます。3つ目の方法はセマンティックセグメンテーションです。これはピクセルレベルの分類です (図1-c)。セマンティックセグメンテーションは、他の方法と比較して最大のデータ量を必要としますが、より詳細な情報を提供します。現在、Amazon Rekognition はマルチラベル画像分類とバウンディングボックスによるオブジェクト検出のみをサポートしています。Amazon SageMaker を利用することで、セマンティックセグメンテーションを実現できます。

図1 – (a) マルチラベル分類、(b) バウンディングボックスによるオブジェクト検出、(c) セマンティックセグメンテーションの出力例
ドローンによって撮影されたタービンの写真は、常にタービンを写しているはずです。そのため、マルチラベル画像分類のように、画像シーン全体による画像認識は効果的なアプローチではありません。代わりに、タービンの問題を見分けて特定することが望まれます。このブログ記事では、2 つの理由からバウンディングボックスによるオブジェクト検出を選択しました。まず最初に、バウンディングボックスによるオブジェクト検出では、利用すべき十分な情報と学習に必要なデータ量のバランスが取れています。次に、Amazon Rekognition カスタムラベルを選択すると一行もコードを書く必要がありません。もし、ピクセルレベルでの識別が必要な場合には、セマンティックセグメンテーションを使用した Amazon SageMaker が適切なソリューションとなります。
ラベル識別と問題クラスのタイプ
このブログ記事では、風力タービンに関する 3 つの問題(ラベル)の例について考察します。これらは摩耗、着氷、腐食です (図 2-a、図2-b、図2-c)。ここでは、一般に公開されている画像を使用しました。ただし、Amazon Rekognition カスタムラベルでは3つの問題に限定されるわけではなく、最大 250 種類の問題 (ラベル) を作成できます。

図2 – (a) リーディングエッジに摩耗のあるタービンブレード (写真は Keegan et al. 2013)、(b) ブレードの着氷 (写真は Fakorede et al. 2016)、(c) 腐食 (写真は Cameron Venti on Unsplash)
Amazon Rekognition カスタムラベルモデルでは、「問題なし」の状態を表すベースラインとなるラベルクラスを含めることで検出の精度を上げることができます。ベースラインのクラスが存在しない場合、モデルは問題を検出することに偏り、偽陽性が増える可能性があります。ベースラインを含めることによって、機械学習モデルでは、タービンの通常の (問題なし) 状態に「問題」があるとは考えなくなり、タービン自体ではなくタービンに付着する「オブジェクト」が問題に起因することを学習します。ベースラインを含めることで、偽陰性を減らすのにも役立ちます。また、バイアスを減らすために、ベースラインのサンプル数を、「問題あり」のサンプル数に近づけ、バランスの取れた学習データを利用することをお勧めします。これはマルチラベル画像分類とバウンディングボックスによる物体検出に対する説明であることに注意してください。セマンティックセグメンテーションには異なるベストプラクティスがあります。Amazon SageMaker では、Amazon SageMaker Clarify を使用して、データセットの偏りと公平性を検出できます。
トレーニング結果を評価する
データセットの準備、ラベル付け、トレーニング、および Amazon Rekognition のデプロイは、このブログの対象外です。これらの手順を実行するには、Amazon Rekognition カスタムラベル入門ガイドをご覧ください。ここでは、重要となるモデルトレーニング結果の評価を外観検査の観点から説明します。
このモデルでは、ベースラインを含め、ラベルのカテゴリごとに約 20 ~ 30 個のサンプル画像を準備しました。一般公開されているタービンの写真の数と品質には限界があります。しかし、我々がこのブログを準備するときと違い、外観検査を実現しようとする企業では、良いサンプルとなる写真を自社で準備できると考えています。
図 3 は、トレーニング済みの Amazon Rekognition モデルの評価結果を示しています。全体的な再現率(Overall recall)が 0.964、適合率(Average precision)が 0.941 であることを示しています。要するに、すべてのラベル (問題とベースライン) の 96.4% がモデルによって正しくキャプチャされ、予測したラベルの 94.1% が正しい結果であったことを表します。また、モデルの全体的な再現率と適合率の調和平均である F1 スコアは 0.949 であることがわかりました。
ベースラインを準備しなかった場合、全体的な再現率は 0.869、全体の適合率は 0.833、F1スコアは 0.843 でした。このケースでは、ベースラインを追加することでこれらの主要なパフォーマンスパラメータが 10% 程度改善しました。
検査結果は安全性に関わるため、実際の問題を見逃すことは、安全に関わる問題を誤って検出するよりも大きな影響を与えます。このため、モデルのチューニングで再現率を最大化することが望まれます。
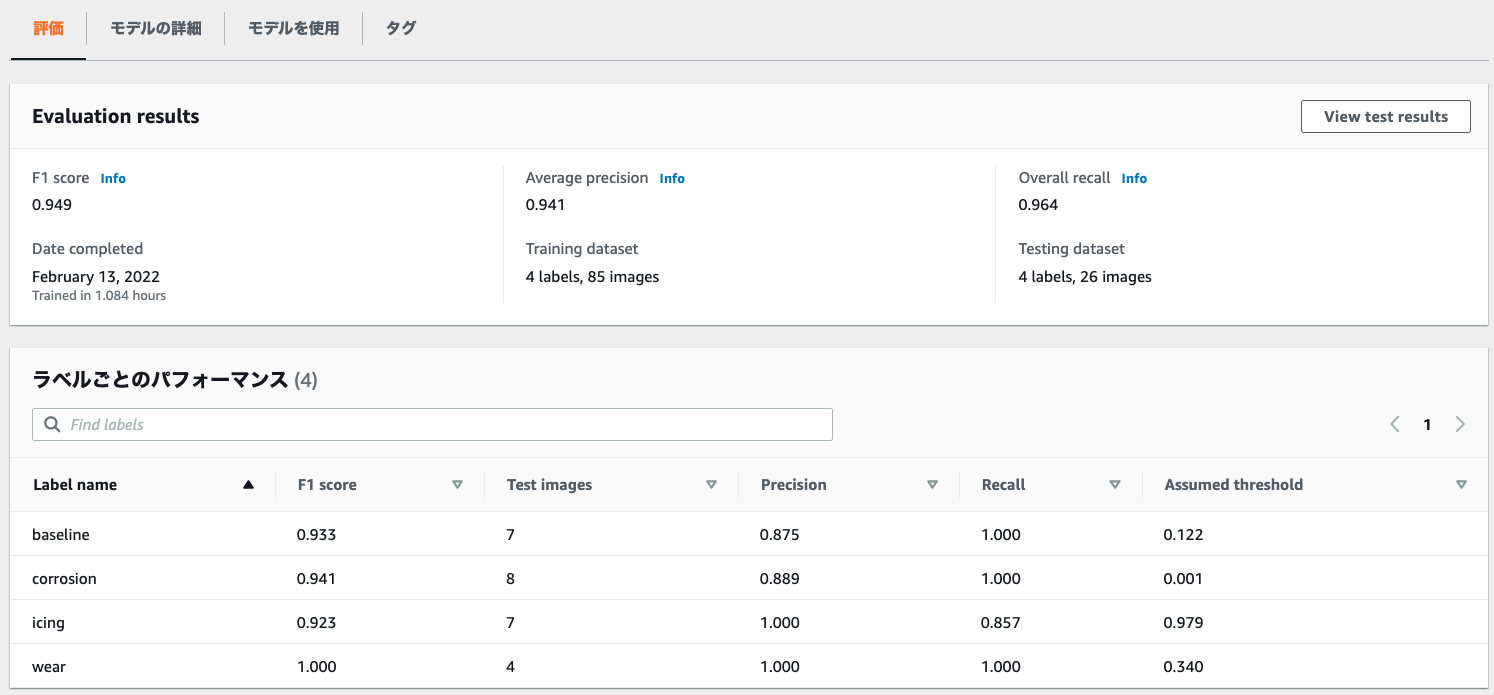
図3 評価結果
図3の「ラベルごとのパフォーマンス」では、“baseline”(ベースライン)、“corrosion“(腐食)、“wear”(摩耗)の再現率(Recall)は満点の 1.00 でした。ただし、“icing”(着氷)の再現率は 0.857 です。これは、テスト用のセットに含まれる着氷のケースの 14.3% (1 — 0.857 = 0.143) が検出されなかったことを意味します。この場合、再現率を高めるために Amazon Rekognition カスタムラベルモデルの改善に取り組むことができます。再現率を向上させる方法の 1 つは、信頼性のしきい値を下げることです。これは、信頼性が低くても着氷と識別されることが増えることを意味します。ただし、これにより精度は低下します。この閾値は、推論のステップで下げることができます。「学習済みモデルによるイメージの分析」の方法で ”–min-confidence“ により閾値を設定します。
ソリューション
アーキテクチャ
図 4 に示すように、ドローンで撮影した画像は最初に Amazon S3 (my-pictures-bucket) にアップロードされ(ステップ①)、 AWS Lambda (推論用 Lambda) が呼び出されます (ステップ②)。推論用 Lambda 関数は、Amazon Rekognition カスタムラベル API を呼び出して(ステップ ③)、my-pictures-bucket S3 バケットに保存されている画像を推論します (ステップ④)。そのため、Amazon Rekognition には、S3 バケットから GetObject などのアクションを実行するための IAM アクセス権限やバケットポリシーの設定が必要です。ラベル付けされた推論結果を含む JSON レスポンスを推論用 Lambda が受け取り(ステップ⑤)、Amazon DynamoDB テーブルの項目として追加します(ステップ⑥)。DynamoDB テーブルには、パーティションキーとして IDと、ソートキーとしてタイムスタンプを持ちます。この項目には、S3 バケットの画像ファイルに対するオブジェクトキーと、Amazon Rekognition からの推論結果の 2 つの属性を持ちます。Amazon DynamoDB Streams は、別の Lambda 関数である評価用 Lambda を呼び出します(ステップ⑦)。この Lambda 関数が、意思決定ロジックとして機能します。評価用 Lambda が、 DynamoDB テーブルの推論結果を評価します。推論結果が条件を満たす場合、Lambda 関数はそれに応じてアクションを起こします。実装を簡単にするため、評価用 Lambda は、通知対象のラベルのリストをデプロイテンプレートで MyLabelListToBeNotified として定義しています。このビジネスロジックは自由に定義することが可能です。推論結果から通知対象のラベルが見つかった場合、評価用 Lambda は最初に my-pictures-bucket 画像に対して署名付き URL を生成し(ステップ⑧)、次に Amazon SNS を呼び出します (ステップ⑨)。Amazon SNS は、問題 (ラベル)、詳細 (信頼性)、および画像へのリンクとして署名付き URL を含む E メールを送信します(ステップ ⑩)。

図4 AWS SAM でデプロイしたアーキテクチャは上の破線で囲まれた部分
次のセクションでは、最初に Amazon S3 バケット (my-training-bucket) をデプロイし、次に Amazon Rekognition カスタムラベルのエンドポイントをデプロイします。最後に、AWS SAM を使用して他のサービスをデプロイできます。
デプロイメント
前提条件
AWS CLI と AWS SAM の両方を使用するため、AWS CLI と AWS SAM CLI のインストールと設定を行なってください。アプリケーションのビルドプロセスでは、Docker と Python のインストールも必要です。
前のセクションで説明したように、このブログ投稿では Amazon Rekognition エンドポイントがデプロイされていることを前提としています。「Amazon Rekognition カスタムラベルの使用を開始する」を参照してください。
導入手順
まず、サンプルの SAM フォルダを GitHub リポジトリからダウンロードします。次のコマンドを使用して、リポジトリをクローンし、SAM テンプレートと 2 つの Lambda 関数が存在するフォルダに移動します。
git clone https://github.com/aws-samples/ai-based-windturbine-inspection-blogpost.git
cd ai-based-windturbine-inspection-blogpost/SAM-repoフォルダに移動したら、以下のように AWS SAM デプロイメントを開始します。
sam build
sam deploy --guidedガイド付きデプロイメントでは、いくつかのパラメータに対してプロンプトが表示されます。
- Stack Name に “my-stack-for-recognition-turbines” と入力します。
- MyDynamoDBTable には任意の名前を付けることができます(デフォルト MyRekognitioNResultTable)。
- InputBucketNamePrefix には一意なバケット名を入力する必要があります。入力した名前に接尾辞“-get-photo“を付けた S3 バケットが作成されます。
- CustomLabelSendPoint に事前に作成した Amazon Rekognition カスタムラベルのエンドポイント ARN (開始したモデルの ARN) をコピーし貼り付けます。
- Amazon SNS で通知メールを受け取る場合、myEmailAddress にメールアドレスを入力します。
- MyLabelListToBeNotificed には、通知対象の問題ラベルを定義できます。デフォルトは“icing”(着氷)、“wear”(摩耗)、“corrosion“(腐食)です。
- ThresholdForNotification には通知の閾値を指定します。デフォルトは 75% です。
最後に、残りの質問に “y” と入力するかデフォルト値を受け入れ、すべてのデプロイが完了するまで待ちます。デプロイの途中で、no-reply@sns.amazonaws.com からサブスクリプションを確認するメールが届きます。クリックしてサブスクリプションを確認してください。
ソリューションのテスト
検証用のデータセットから写真を一つ選択します。この例では、図2-a(example-picture.png)を選択しました。ローカルディスクにダウンロードし、外部からのアップロードプロセスをシミュレートします。以下のコマンドを使用できます。
aws s3api put-object --bucket my-pictures-bucket --key example-picture.png --body ./example-picture.png写真がアップロードされると、推論結果、信頼性、Amazon S3 の写真オブジェクトに対する署名付き URL を含むメールを受信します(図-5)。デプロイ中に作成された DynamoDB テーブルから推論結果を参照できます。

図-5 写真のアップロード後に受信した電子メール通知
クリーンアップ
- Amazon Rekognition カスタムラベルのエンドポイント(モデルバージョン)を停止します。CLI コマンドは、マネジメントコンソール Amazon Rekognition カスタムラベルのモデルのページから「モデルを使用」タブで確認できます。(モデルバージョンは aws rekognition describe-project-versions –project-arn “<Project ARN>” で確認できます。)
aws rekognition stop-project-version --project-version-arn "<Project Version ARN>" - トレーニングデータセットとテストデータセットを削除します。(データセットは aws rekognition describe-projects で確認できます。)
aws rekognition delete-dataset --dataset-arn "<Train Dataset ARN>" aws rekognition delete-dataset --dataset-arn "<Test Dataset ARN>" - モデルバージョンを削除します。(モデルバージョンは aws rekognition describe-project-versions –project-arn “<Project ARN>” で確認できます。)
aws rekognition delete-project-version --project-version-arn "<Project Version ARN>" - Amazon Rekognition プロジェクトを削除します。(プロジェクトは aws rekognition describe-projectsで確認できます。)
aws rekognition delete-project --project-arn "<Project ARN>" - CloudFormation スタックを削除する前に、画像をアップロードした Amazon S3 バケットが空になっていることを確認してください。
aws s3 rm s3://windturbine-pictures-get-photo --recursive - その後、CloudFormation スタックを削除します。
aws cloudformation delete-stack --stack-name my-stack-for-recognition-turbines - 不要な場合には、最後にトレーニング画像を含む S3 バケットを削除します。
aws s3 rm s3://my-training-bucket --recursive aws s3api delete-bucket --bucket my-training-bucket
結論
このブログ記事では、風力タービン検査のための画像認識にビジネスロジックを組み込む、イベント駆動サーバーレスアーキテクチャについて説明しました。また、より良い自動外観検査のために、画像認識における重要な機械学習の概念について説明しました。最終的に、AWS SAM によりサーバーレスアーキテクチャをデプロイしました。合わせて、AWS エネルギーで詳細をご確認ください。
翻訳はソリューションアーキテクトの 鈴木健吾 が担当しました。原文はこちらです。