Amazon Web Services ブログ
Amazon Kinesis アップデート – Amazon Elasticsearch Service との統合、シャード単位のメトリクス、時刻ベースのイテレーター
Amazon Kinesis はストリーミングデータをクラウド上で簡単に扱えるようにします。
Amazon Kinesis プラットフォームは3つのサービスから構成されています:Kinesis Streams によって、開発者は独自のストリーム処理アプリケーションを実装することができます;Kinesis Firehose によって、ストリーミングデータを保存・分析するための AWS へのロード処理がシンプルになります;Kinesis Analytics によって、ストリーミングデータを標準的な SQL で分析できます。
多くの AWS のお客様が、ストリーミングデータをリアルタイムに収集・処理するためのシステムの一部として Kinesis Streams と Kinesis Firehose を利用しています。お客様はこれらが完全なマネージドサービスであるがゆえの使い勝手の良さを高く評価しており、ストリーミングデータのためのインフラストラクチャーを独自に管理するかわりにアプリケーションを開発するための時間へと投資をしています。
本日、私たちは Amazon Kinesis Streams と Amazon Kinesis Firehose に関する3つの新機能を発表します。
- Elasticsearch との統合 – Amazon Kinesis Firehose は Amazon Elasticsearch Service へストリーミングデータを配信できるようになりました。
- 強化されたメトリクス – Amazon Kinesis はシャード単位のメトリクスを CloudWatch へ毎分送信できるようになりました。
- 柔軟性 – Amazon Kinesis から時間ベースのイテレーターを利用してレコードを受信できるようになりました。
Amazon Elasticsearch Service との統合
Elasticsearch はポピュラーなオープンソースの検索・分析エンジンです。Amazon Elasticsearch Service は AWS クラウド上で Elasticsearch を簡単にデプロイ・実行・スケールさせるためのマネージドサービスです。皆さんは、Kinesis Firehose のデータストリームを Amazon Elasticsearch Service のクラスターへ配信することができるようになりました。この新機能によって、サーバーのログやクリックストリーム、ソーシャルメディアのトラフィック等にインデックスを作成し、分析することが可能になります。
受信したレコード(Elasticsearch ドキュメント)は指定した設定に従って Kinesis Firehose 内でバッファリングされたのち、複数のドキュメントに同時にインデックスを作成するバルクリクエストを使用して自動的にクラスターへと追加されます。なお、データは Firehose へ送信する前に UTF-8 でエンコーディングされた単一の JSON オブジェクトにしておかなければなりません(どのようにこれを行うかを知りたい方は、私の最近のブログ投稿 Amazon Kinesis Agent Update – New Data Preprocessing Feature を参照して下さい)。
こちらが、AWS マネージメントコンソールを使用したセットアップの方法です。出力先(Amazon Elasticsearch Service)を選択し、配信ストリームの名を入力します。次に、Elasticsearch のドメイン(この例では livedata)を選択、インデックスを指定し、インデックスのローテーション(なし、毎時、日次、週次、月次)を選択します。また、全てのドキュメントもしくは失敗したドキュメントのバックアップを受け取る S3 バケットも指定します:
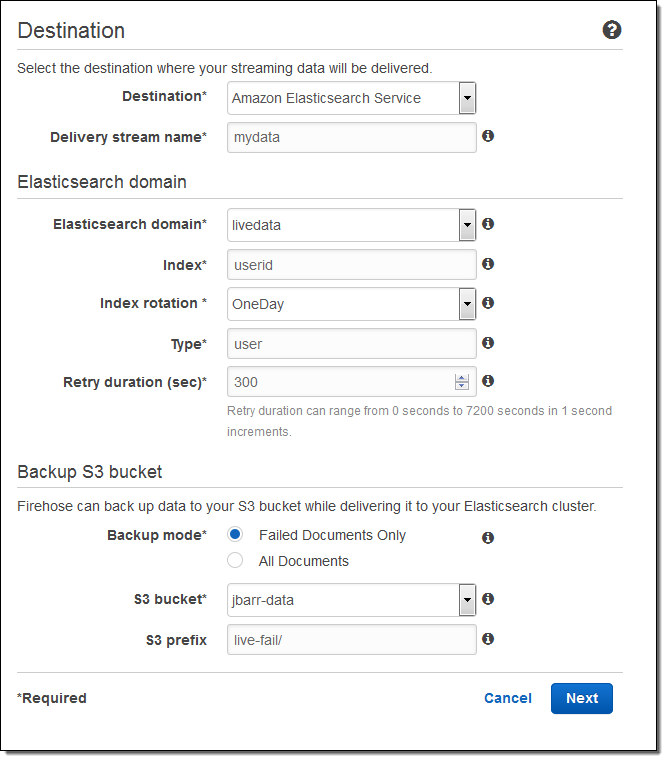
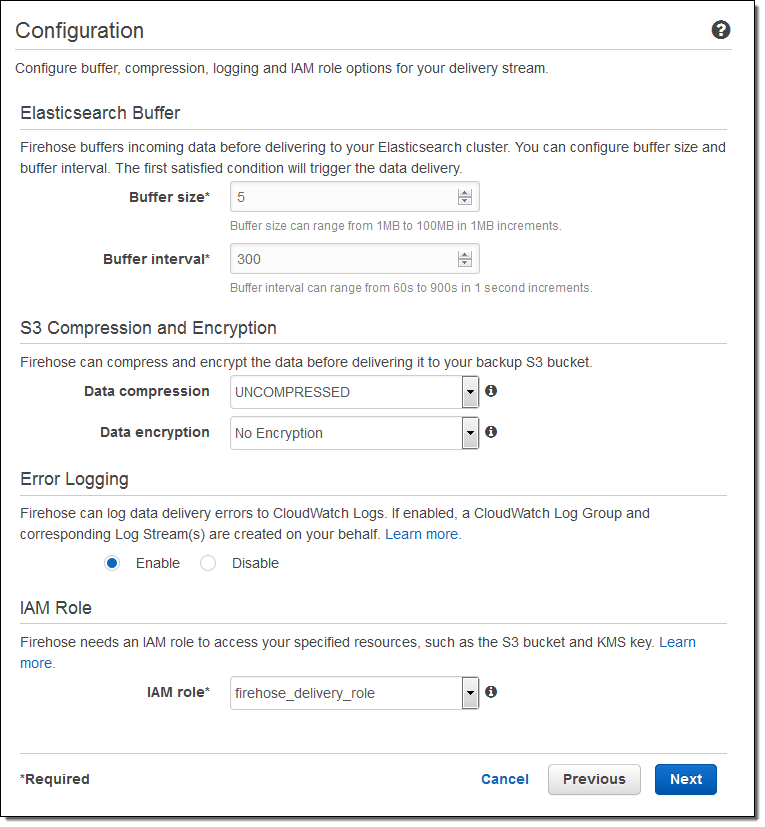
そして、バッファーのサイズを指定し、S3 バケットに送信されるデータの圧縮と暗号化のオプションを選択します。必要に応じてログ出力を有効にし、IAM ロールを選択します:
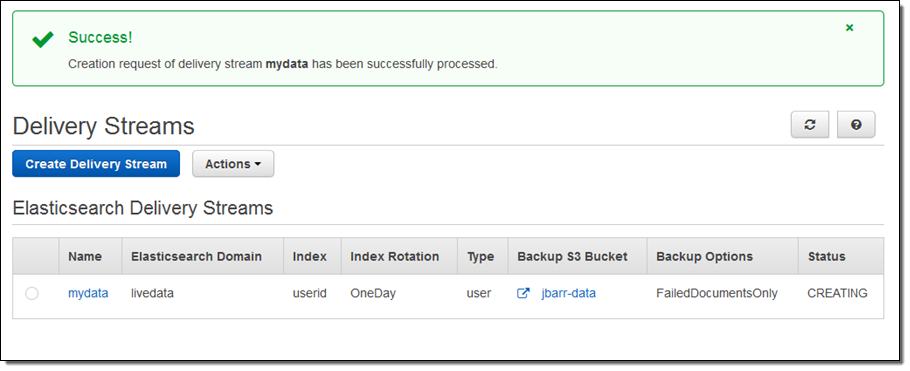
一分程度でストリームの準備が整います:
コンソールで配信のメトリクスを見ることもできます:
データが Elasticsearch へ到達した後は、Kibana や Elasticsearch のクエリー言語による視覚的な検索ができます。
総括すると、この統合によって、皆さんのストリーミングデータを収集し、Elasticsearch に配信するための処理は実にシンプルになります。もはや、コードを書いたり、独自のデータ収集ツールを作成したりする必要はありません。
シャード単位のメトリクス
全ての Kinesis ストリームは、一つ以上のシャードによって構成されており、全てのシャードは一定量の読み取り・書き込みのキャパシティを持っています。ストリームにシャードを追加することで、ストリームのキャパシティは増加します。
皆さんは、それぞれのシャードのパフォーマンスを把握する目的で、シャード単位のメトリクスを有効にすることができるようになりました。シャードあたり6つのメトリクスがあります。それぞれのメトリクスは一分間に一回レポートされ、通常のメトリクス単位の CloudWatch 料金で課金されます。この新機能によって、ある特定のシャードに負荷が偏っていないかを他のシャードと比較して確認したり、ストリーミングデータの配信パイプライン全体で非効率な部分を発見・一掃したりすることが可能になります。例えば、処理量に対して受信頻度が高すぎるシャードを特定したり、アプリケーションから予想よりも低いスループットでデータが読まれているシャードを特定したりできます。
こちらが、新しいメトリクスです:
IncomingBytes – シャードへの PUT が成功したバイト数。
IncomingRecords – シャードへの PUT が成功したレコード数。
IteratorAgeMilliseconds – シャードに対する GetRecords 呼び出しが戻した最後のレコードの滞留時間(ミリ秒)。値が0の場合、読み取られたレコードが完全にストリームに追いついていることを意味します。
OutgoingBytes – シャードから受信したバイト数。
OutgoingRecords – シャードから受信したレコード数。
ReadProvisionedThroughputExceeded – 秒間5回もしくは2MBの上限を超えてスロットリングされた GetRecords 呼び出しの数。
WriteProvisionedThroughputExceeded – 秒間1000レコードもしくは1MBの上限を超えてスロットリングされたレコードの数。
EnableEnhancedMetrics を呼び出すことでこれらのメトリクスを有効にすることができます。いつもどおり、任意の期間で集計を行うために CloudWatch の API を利用することもできます。
時刻ベースのイテレーター
任意のシャードに対して GetShardIterator を呼び出し、開始点を指定してイテレーターを作成することで、アプリケーションは Kinesis ストリームからデータを読み取ることができます。皆さんは、既存の開始点の選択肢(あるシーケンス番号、あるシーケンス番号の後、最も古いレコード、最も新しいレコード)に加え、タイムスタンプを指定できるようになりました。指定した値(UNIX 時間形式)は読み取って処理しようとする最も古いレコードのタイムスタンプを表します。
— Jeff;
翻訳は SA 内海(@eiichirouchiumi)が担当しました。原文はこちらです。