Amazon Web Services ブログ
AWS CDKでクラウドアプリケーションを開発するためのベストプラクティス
この記事では、AWS Cloud Development Kit (AWS CDK) を中心とした、大規模なチームで複雑なクラウドアプリケーションの開発を組織化するための戦略について説明します。AWS CDK では、開発者や管理者は、TypeScript、Python、Java、C#などの使い慣れたプログラミング言語を使ってクラウドアプリケーションを定義することができます。アプリケーションは、Stage、Stack、Constructに整理されており、ランタイムロジック (AWS Lambda コードやコンテナ化されたサービスなど) と、Amazon Simple Storage Service (Amazon S3) バケット、Amazon Relational Database Service (Amazon RDS) データベース、ネットワークなどのインフラストラクチャコンポーネントの両方において、モジュール化された設計手法を可能にしています。
この記事では、AWS CDKの基本的なコンセプトに関する簡単なチュートリアルではなく、より実践的な内容について説明します。ローカルでコードを書きテストする方法や、本番環境や様々なステージングアカウントにデプロイする方法、そしてチームのアプリを整理して、より大きな組織で活用する方法について説明します。
AWS CDKを初めてご利用になる方は、AWS CDK Intro Workshop から始めることを強くお勧めします。この記事では、いくつかの高度なトピックを扱っていますが、基礎を把握しておくと良いでしょう。詳細については、AWS CDKリファレンスドキュメントとGitHub リポジトリにある aws-cdk-examples のサンプルコードを参照してください。
CDKの哲学
前回の記事では、AWS CDKの歴史とモチベーションについて説明しました。AWS CDKを設計するにあたり、私たちはお客様や社内のチームのニーズを詳しく調査し、複雑なアプリケーションのデプロイや継続的なメンテナンスの際に発生する一般的な障害パターンを分析しました。例えば、本番環境でアプリケーションの設定ファイルを編集すると、テスト環境では見られなかったエラーが発生する、などです。AWS CDKは、アプリケーション全体をコードで定義し、ソースリポジトリへのプッシュによってのみデプロイされたアプリケーションへの変更をするというモデルを可能にしています。
組織では、インフラストラクチャを作成するチーム、ソフトウェア開発を行うチーム、設定とデプロイを行う運用チームなど、一つのアプリケーションを別々の役割で担当する複数のチームが存在する場合があります。あるいは “two-pizza-team” のような小さなチームであっても、アプリケーションは次の図のように、インフラストラクチャーとコードが別々のリポジトリで管理されていて、デプロイがすべて独立したCI/CDシステムで管理されている事があります。

AWS CDKを使用すると、これらすべてを一つにまとめて、単一のリポジトリに格納された単一のアプリケーションを作成することができます。このアプリケーションでは、VPC、S3バケット、Amazon Elastic Compute Cloud (Amazon EC2)インスタンス、セキュリティグループなどの基本的なコンポーネントを定義します。また Typescript で書かれた Lambda関数のコードや、Java で書かれたコンテナベースのサーバーなど、ランタイムロジックも含まれます。また継続的インテグレーション (CI) や継続的デリバリ/デプロイメント(CD)を可能にするデリバリーパイプラインも指定できます。ターゲットとなるすべてのデプロイ環境は、デプロイに必要な情報をパラメータ化して後で設定するのではなく、ソースコードの中で完全に設定されます。

AWS CDKアプリケーションが合成 (Synthesis)されると、結果はクラウドアセンブリになります。このアセンブリには、すべてのデプロイ先アカウントとリージョン用に生成された AWS CloudFormationテンプレートとファイルアセットが含まれており、これらは後に AWS CDK CLI によってデプロイされます。
組織での取り組み
最新のアプリケーション開発プラクティスを採用する社内の取り組みの一環としてAWS CDKを採用する場合がありますが、これを実現するには、どのように組織化されているかを検討することが非常に重要です。すでに触れたように、”two-pizza-team” チームは、小規模で自律的なチームが、何かを変更したいときに複雑な承認プロセスを経ることなく、会社の利益の最大化のために迅速に行動できるようにします。これは理論的には素晴らしいことのように思えますが、実際には、それらのチームが運用すべき明確なガードレールを持っていない場合、混乱状態に陥る可能性があります。
AWS CDKやマイクロサービスの継続的なデプロイメントモデルへの移行は難しいため、社内の他のメンバーがAWS CDKを使い始める際のトレーニングや指導を担当する専門家チームを設置することが最善の方法です。私たちは、すべての中規模および大規模な組織が、アプリケーションの開発とデプロイに関するメンター、トレーナー、および会社のポリシーの保護者として機能するクラウドセンターオブエクセレンス (CCoE) を立ち上げることを強くお勧めします。
CCoEの最初の責務の1つは、AWS内の組織単位を定義するためのランディングゾーンを作成することです。ランディングゾーンは、ベストプラクティスの青写真に基づいた、事前に設定された安全でスケーラブルなマルチアカウントのAWS環境です。複数のAWSサービスを使用してランディングゾーンを実装し、それらを AWS Control Tower と連携させることができます。AWS Control Tower は、単一の画面からマルチアカウントシステム全体を設定および管理できるサービスです。開発チームは、アプリケーションのテストとデプロイに使用できる新しいアカウントを自由に作成できることが望ましいです。これにより、次の図に示すように、ベストプラクティスのもう1つの推奨事項である複数アカウントへの導入を採用できます。
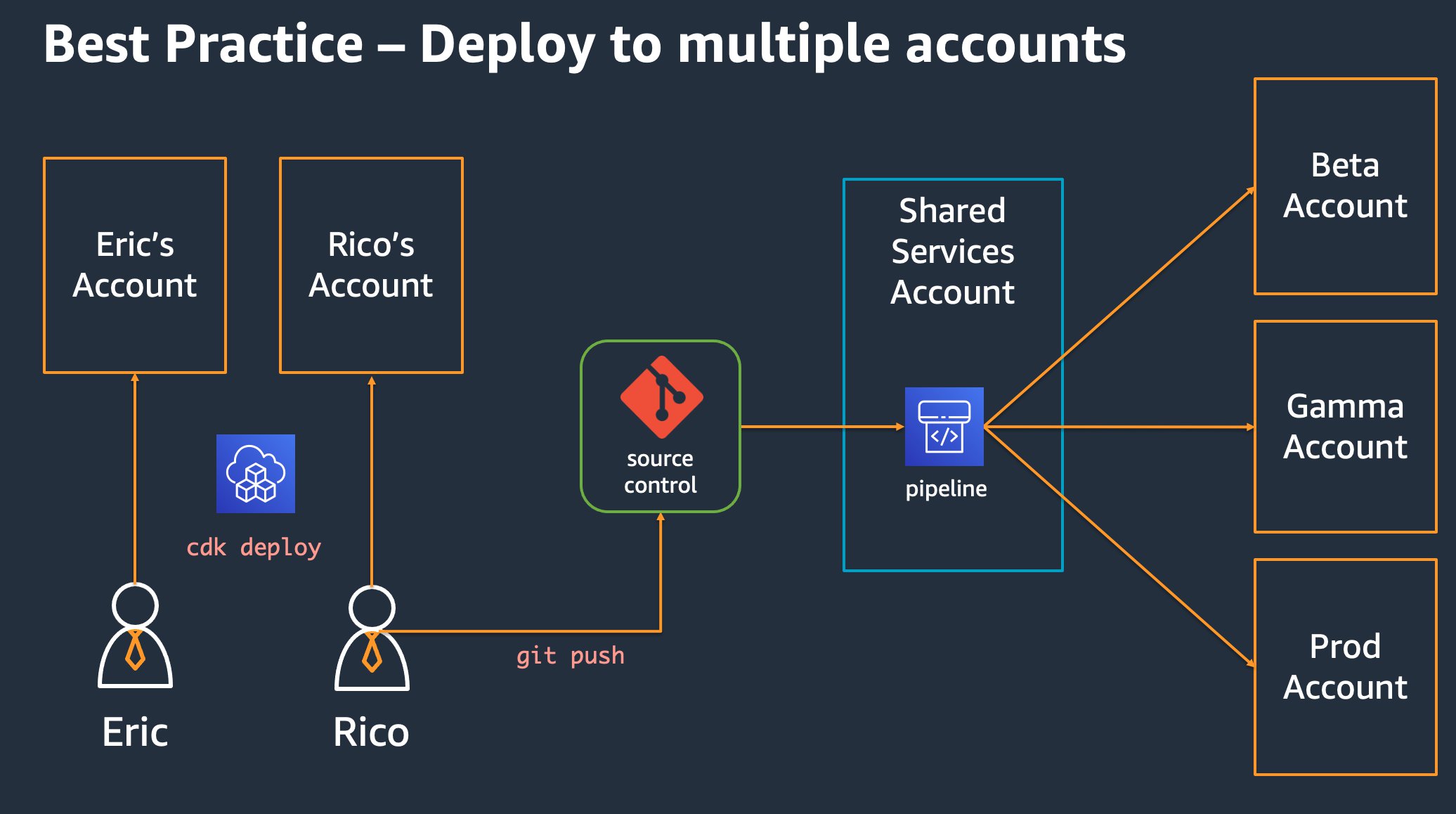
このアーキテクチャでは、開発者はそれぞれ自分用の開発アカウントを持っています。リポジトリにプッシュされたコードがレビューに通りマージされると、共有サービスアカウントで設定されたデプロイパイプラインが動き出します。この共有サービスアカウントでは、アプリケーションのビルド、テスト、各Stageへのデプロイを担当します。beta、gamma、prodなどの環境は、それぞれが独立したアカウントでホストされます。さらにアプリケーションの各StageをAWSリージョンごとに、別々のアカウントにデプロイすることもありますが、アカウントの数が膨大になってしまいます。AWS CDKは、これら全ての環境をコードでモデリングすることで、この複雑さを管理することができます。
コードを管理するためのベストプラクティス
このセクションでは、コードを管理するためのベストプラクティスを紹介します。下の図は、チーム、コードリポジトリ、パッケージ、CDKアプリケーション、Constructライブラリの関係を示しています。

シンプルな構成から始めて、必要に応じて複雑な構成に変更
これらのベストプラクティスのほとんどは、より複雑な設定を必要とする要件がない限り、シンプルに保つことが基本となります。コードは後からでも移動できるので、シンプルに始めて、必要なときだけ変更させるようにしましょう。
すべてのアプリケーションは、1つのリポジトリにある1つのパッケージから始める
1つのパッケージは、AWS CDKアプリのエントリーポイントとなります。ここでアプリケーションのさまざまなコンポーネントをどこに、どうやってデプロイするかを定義し、またアプリケーションをデプロイするためのCI / CDパイプラインを定義します。
これらのアプリケーションConstructは、再利用性に応じて、同じ AWS CDKのアプリパッケージに含めたり、別のパッケージに分かれていたりします。対象の Constructがアプリケーションに非常に固有のものであれば、それらを一般化して別のパッケージにすることはあまり意味がありません。一方で、複数のアプリケーションで再利用されている場合は、別のライフサイクルとテスト戦略を持つ別のパッケージに移すべきです。
同じリポジトリ内のパッケージ間の依存関係は、ビルドツールによって管理されます。
また一般的には、同じリポジトリに複数のアプリケーションを置くことはお勧めしません。特に自動化されたデプロイメントパイプラインを使用する場合は、デプロイ時の変更による影響範囲が大きくなるためです。複数のアプリケーションが1つのリポジトリにある場合、以下のような課題が発生しがちです。
- あるアプリケーションに変更を加えると、何も変わっていないのに他のアプリケーションがデプロイされてしまう
- 一方のアプリケーションに問題があってビルドができなくなると、もう一方のアプリケーションもデプロイできなくなる
コードのライフサイクルやチームの所有権に応じてリポジトリに分割する
以下のような状況になったら、パッケージを別のリポジトリに移すことを検討しましょう。
- パッケージが複数のアプリケーションで同時に使用されるようになる。すべてのアプリケーションのビルドシステムから参照される場所に置く必要がある。アプリケーションのライフサイクルとは独立したサイクルで変更する必要がある。
- 複数のチームが、アプリケーションを構成するパッケージの異なるセットに対するコミット権限を持っている。それらを別のコードリポジトリに分離することで、アクセスコントロールが可能になる。
リポジトリの境界を越えてパッケージを利用するためには以下のものが必要です。
- 内部的なパッケージリポジトリ – リポジトリは、組織内の他のアプリケーションチームが使用できる場所にパッケージをホストします。このようなパッケージリポジトリは、様々な言語用に多数存在します。AWS CodeArtifact は、ほとんどの一般的なプログラミング言語のパッケージリポジトリとして機能します。
- リリースプロセス – このプロセスは、パッケージのビルドと適切なテストを行い、パッケージリポジトリに新しいバージョンを公開します。リリースプロセスは通常、自動化されたパイプラインであり、必要に応じて実行されるか、毎日または毎週のように定期的に実行されます。例として、AWS CDKチームは delivlib と呼ばれる Constructライブラリを使ってリリースパイプラインを管理しています。
パッケージリポジトリにあるパッケージの依存関係は、パッケージマネージャによって管理されます。パッケージマネージャーは、アプリケーションが依存しているすべての依存パッケージの特定のバージョンをエンコードすることで、ビルドの再現性を確保する責任があります。
単一のアプリケーションであれば、テスト環境にデプロイして動作を確認すれば十分かもしれませんが、アプリケーション間で共有されているパッケージは、利用するアプリケーションとは別にテストする必要があります。
単一のConstructは、単純にも複雑にもでき、汎用型にも特化型にもできることを覚えておいてください。BucketもCameraShopWebsite も同じ Constructです。組織内のあるチームの責任は、CameraShopWebsite の Constructを開発、生産することかもしれません。
インフラストラクチャコードとアプリケーションコードを同じパッケージにする
AWS CDKはCloudFormationテンプレートを生成するだけではなく、Lambdaコードや Dockerイメージなどのデプロイを処理する強力なアセットバンドラーも含まれています。
AWS CDKの哲学のセクションで説明したように、インフラストラクチャのコンポーネントとビジネスロジックを実装するコードを同じ構成にまとめることは、全く問題なく、むしろ推奨されます。それらは別々のリポジトリにある必要はありませんし、別々のパッケージにある必要もありません。Constructとは、機能の一部を完全に記述した自己完結型のものです。
インフラストラクチャとランタイムのコードを一緒にしておけば、一緒に改善したり、分離してテストしたり、プロジェクト間で共有・再利用したり、同期をとって一緒にバージョン管理したりすることが容易になります。
Constructライブラリのベストプラクティス
このセクションでは、Construct (リソースをカプセル化した合成可能で再利用可能なモジュール) を開発する際に適用すべきベストプラクティスを説明します。
StackではなくConstructでアプリをモデル化する
アプリを分割する際は、各パーツはStack ではなく Constructのベースクラスを継承したクラスで表現することをお勧めします。Stackはデプロイの単位であり、個々のアプリケーションに特有のものになりがちです。Constructを使用することで、それぞれのデプロイシナリオに最も適した方法で Stackを構成する柔軟性を与えることができます。例えば、複数の Constructを開発環境用に設定したDevStackにまとめ、本番環境用には別のConstructを設定することができます。
環境変数ではなく、API (プロパティ、メソッド) で設定する
よく見られるアンチパターンのひとつに、ConstuctやStack内での環境変数の利用があります。デプロイに必要なパラメータは環境変数で設定するのではなく、コードに記述しましょう。環境変数を参照するとすれば、それはアプリケーションの最上位レベルに限られるべきで、ConstructやStackの中から参照するべきではありません。その場合であっても環境変数の利用はローカルでの開発に限定することが望ましいです。
インフラストラクチャのユニットテスト
AWS CDKのベストプラクティスである決定性のあるビルド (合成時の外部問い合わせを避け、すべてをコードでモデル化します。これについては後ほど説明します) に従うことの利点の 1つは、ビルド時にすべての環境で一貫してユニットテストを実行できることです。どの Git コミットでも常に同じテンプレートが生成されるのであれば、生成されたテンプレートが期待通りのものであることを確認するために書いたユニットテストを信頼することができます。
ステートフルリソースのスコープとIDを変更しない
リソースの論理IDを変更すると、AWS CloudFormationによってリソースの置き換えが行われますが、多くの場合、データベースのようなステートフルなリソースや VPC のような永続的なインフラストラクチャの置き換えはしたくないはずです。AWS CDKコードのリファクタリングで ID の変更が発生する場合は注意が必要です。ステートフルなリソースの論理ID が変更されていないことを保証するテストを書きましょう。
コンプライアンスのためにConstructを使わない
特にエンタープライズのお客様によく見られるもう一つのパターンとして、AWS CDKに含まれるL2 Constructをベースに、サブクラスを1対1でマッピングした Constructのコレクションを作成することがあります。例えば、s3.Bucketを継承したMyCompanyBucketというクラスや、lambda.Functionを継承したMyCompanyFunctionというクラスを作成する、などのケースです。これらのサブクラスの中には、データを暗号化したり、特定のセキュリティポリシーの使用を要求するなど、会社のセキュリティのベストプラクティスを実装します。このパターンはニーズに応えるものですが、重大な欠点があります。AWS Solutions Constructs のようなAWS CDK Constructのエコシステムが成長し、より便利になっていっても、ベースとなるL2 Constructが使用できない場合は開発者は恩恵を受けることが出来ません。
代わりに組織での SCP や permission boundary の使い方を調べて、セキュリティガードレールを適用しましょう。また aspects や CFN Guardのようなツールを使用して、デプロイ前にインフラストラクチャのプロパティに関するアサーションを行いましょう。aspectsを使うと、与えられたスコープ内の全ての Construct に、任意の操作を適用することが出来ます。例えば以下のような文で、stackに含まれる全てのS3 バケットがバージョニングされていることを確認することができます (aspectsの詳しい使い方についてはリンク先のドキュメントを参照して下さい)。
Aspects.of(stack).add(new BucketVersioningChecker());
AWS CDK アプリケーションのベストプラクティス
前のセクションでは、Constructライブラリのベストプラクティスについて説明しました。ここでは、1つから複数のConstructを組み合わせてリソースの特定の使用方法を定義し、それらをどのように構成してデプロイするかという、AWS CDKアプリケーションの書き方について説明します。
デプロイ時ではなく、合成時に決定する
AWS CloudFormationでは (Conditionsや{ Fn::If }、Parametersによって) デプロイ時に動的に挙動を決めることができます。AWS CDKでもこれらの仕組みはある程度扱えるようになっていますが、実際にはこれらを使わないことをお勧めします。
どのConstructを生成するかなど、すべての決定は合成 (cdk synth) する時に AWS CDKアプリケーションで行うようにしましょう。Fn.ifの代わりにプログラミング言語のifを使用したり、CfnParametersの代わりに関数のパラメータを使用したりすることができます。その理由は、AWS CloudFormationでは、値の種類や値に対して実行できる操作がかなり限定されているからです。例えば、リストの反復処理やリソースのインスタンス化は AWS CloudFormationの式ではできませんが、AWS CDKでは可能です (そして多く使われています)。これには、アプリをどこにデプロイするかを伝えることも含まれ、合成時に関連するコンテキスト情報を調べることができます。
AWS CloudFormationを目的の言語とするのではなく、堅牢なクラウドデプロイメントのために使用する実装として扱いましょう。
自動で生成されるリソース名を使用し、物理的な名前を使用しない
名前は貴重なリソースです。すべての名前は一度しか使えないので、テーブル名やバケット名をインフラやアプリケーションにハードコードしてしまうと、もうそのインフラの一部を2つ並べてデプロイすることはできません。
さらに悪いことに、リソースの置き換えを必要とする変更をこれ以上加えることができません。例えば Amazon DynamoDB テーブルのKeySchemaのように、作成後の変更ができないリソースを変更したい場合には、リソースを作り直す必要があります。AWS CDKはイミュータブルなプロパティへの変更に対応するために、古いテーブルが削除される前にまず新しいキースキーマを持つ新しいテーブルを作成しようとします。しかし、そのテーブルが固定された名前を持っている場合、古いテーブルがその名前を使用しているため、新しいテーブルを作成することができません。
より良い方法は、できるだけ名前を指定しないことです。リソース名を省略すると、一意の新しい名前が生成されるので、この種の問題は発生しません。次にアプリケーションをパラメータ化します。例えば実際に生成されたテーブル名 (AWS CDKアプリケーションではtable.tableNameとして参照できます) を環境変数としてLambda関数に渡したり、EC2インスタンスの起動時にコンフィグファイルを生成したり、実際のテーブル名を AWS Systems Manager Parameter Store に書き込み、アプリケーションがそこから読み込んで実際のテーブルを把握したりします。これはリソースのための依存性の注入のようなものです。
デプロイ要件に応じて、アプリケーションのStageを複数のStackに分割する
アプリケーションのStack数を決める際に、すべてのリソースを1つのStackにまとめたり、各リソースをそれぞれのStackにまとめたりするような厳密なルールはありません。最終的には、お客様のデプロイパターンに基づいて、柔軟に判断をすることになります。以下のガイドラインを参考にしてください。
- 一般的には、できるだけ多くのリソースを同じ Stack に入れておくのが最も簡単です。あらかじめ分離したいと分かっている場合を除いて、同じStackに入れます。
- ステートフルなリソース (データベースなど) は、ステートレスなリソースから分離しておくとよいでしょう。ステートフルリソースのあるStackの削除保護をオンにしていれば、ステートレスなリソースのある Stack を自由に破壊したり、複数のコピーを作成したりしても、データ損失のリスクはありません。
- ステートフルなリソースはConstructの名前の変更の影響を受けやすく。名前の変更はリソースの置き換えにつながるので、移動したり名前が変更される可能性のある他の Constructの中にはあまり入れない方が良いでしょう (キャッシュのように失われても問題のないデータは除きます) 。
cdk.context.jsonをコミットして、外部的な要因で合成結果が変わってしまうことを避ける
AWS CDKアプリには、cdk synthする時に外部問い合わせを必要とするコードを入れないようにしましょう。不適切なタイミングで呼び出しが失敗する可能性があるだけでなく、その呼び出しは状況によって毎回異なる答えを返す可能性があります。これにより以下の例のように、意図しない副作用が生じる可能性があります。
- VPC を利用可能なすべての Availability Zone にプロビジョニングし、その日は2つだったので、2つのIPアドレス領域に分かれてデプロイされました。次の日にAWSで新しいAvailability Zone が追加されると、AWS CDKは次のデプロイでIPアドレス領域を3つに分割しようとするので、すべてのサブネットを再作成する必要があります。これは稼働しているインスタンスがあると不可能であり、手作業での修正が必要になります。
- 最新のAmazon Linux AMI を参照してインスタンスをデプロイし、翌日に新しい AMI がリリースされた場合、翌日のデプロイではすぐに新しい AMI がピックアップされます。結果、想定しないデプロイが発生しすべてのインスタンスが置き換えられる可能性があります。
AWS CDKには、非決定性情報のソースを記録する仕組み (cdk.context.json) があり、明示的にファイルからエントリを消去しない限り(cdk context)、将来のcdk synthでも同じテンプレートが生成されるようになっています。これらの情報はコンテキストプロバイダと呼ばれるAWS CDKのメカニズムを使用して、.fromLookup()などの呼び出しで参照できます。
コンテキストプロバイダが存在しない情報を使用する必要がある場合は、AWS CDKとは別にこの情報を生成するスクリプトを書き、それをJSONファイルに書き込み、AWS CDKアプリケーションからそのファイルを読み込んで使用することをお勧めします。
AWS CDKでロールとセキュリティグループを管理できるようにする
AWS CDK Construct library の大きな特徴の一つに、AWS Identity and Access Management (IAM)ロールを迅速かつ簡単に作成できるようにリソースに組み込まれた便利なメソッドがあります。このメソッドは、アプリケーションのコンポーネントが相互に作用するための最小限のスコープのパーミッションを許可するように設計されています。例えば、以下のような典型的なコードの行を考えてみましょう。
myBucket.grantRead(myLambda)
この1行で、Lambda関数のロールにポリシーが追加されることになりますが、このロールは裏で暗黙的に作成されています。このロールとそのポリシーは、CloudFormationテンプレート内では十数行になりますが、あなたが書く必要はありません。ベストプラクティスを考慮したコードが自動で生成されます。
セキュリティチームによって定義された事前に作成されたロールを常に使用することを開発者に強制すると、AWS CDKのコーディングは非常に複雑になり、チームはアプリケーションを設計する方法において多くの柔軟性を失うことになります。より良い選択肢は、SCP や permission boundary を使用して、開発者がガードレールの範囲内にいることを保証することです。
全てのStageをコードでモデル化する
AWS CDKアプリケーションは、デプロイパイプラインの設計方法が従来と大きく異なります。従来の方法では、設定値をパラメータ化したデプロイのためのアーティファクトを1つ作成し、それぞれの環境の固有の設定値を適用することで、さまざまな環境にデプロイを行います。AWS CDK では、それらの設定をソースコードに直接埋め込むことができます。本番環境用のコードファイルと、その他のStage用のコードファイルを別々に作成し、設定値をそのままソースに入れることができます。ソースコードに含めたくない機密性の高い値については AWS Secrets Manager や Systems Manager Parameter Store などのサービスを利用して、それらのリソースの名前やARNに置き換えます。アプリケーションを合成すると cdk.out フォルダーに作成されるクラウドアセンブリには、各環境用の個別のテンプレートが含まれます。このようにして、ビルド全体がデプロイ時に変わるものではなく、確定したものになります。アプリケーションが外部からの変更の影響を受けることなくGitのコミットごとに常に同じ CloudFormationテンプレートと付随するアセットが生成されるため、ユニットテストの信頼性が向上します。
全てを測定する
人の介入を必要としない完全な継続的デプロイメントという目標を達成するには高度な自動化が必要ですが、その自動化は膨大な量のモニタリングなしには不可能です。メトリクス、アラーム、ダッシュボードを作成して、デプロイされたリソースをあらゆる面から測定しましょう。また、CPU使用率やディスク容量などの単純な測定だけでなく、ビジネスメトリクスを記録し、それらの測定値を利用してロールバックなどの自動化を行いましょう。AWS CDKのL2 Constructの多くは dynamodb.Tableクラスの metricUserErrors() メソッドのように、メトリクスの作成に役立つ便利なメソッドを備えています。
まとめ
この記事では、AWS CDKを使って堅牢で運用性に優れたアプリケーションを開発するためのベストプラクティスを紹介しました。AWS CDKの設計や発展の元になっている哲学を理解し、リポジトリのGitコミットに基づいた、完全に自動化されたデプロイパイプラインに向かって進んでいきましょう。このシリーズのパート2では、これらのベストプラクティスの多くを実証するサンプルアプリケーションを紹介します。
楽しいコーディングを!
本記事は、Eric Z. BeardとRico Huijbers による “Best practices for developing cloud applications with AWS CDK“を翻訳したものです。
翻訳はPrototyping Solution Architect の 工藤 朋哉が担当しました。