Amazon Web Services ブログ
Plugsurfing が目的別データベースと AWS Graviton でパフォーマンスを 2 倍にし、コストを 70% 削減した方法とは?
この記事は How Plugsurfing doubled performance and reduced cost by 70% with purpose-built databases and AWS Graviton を翻訳したものです。
Plugsurfing は、ドライバー、充電スタンド運営会社、自動車メーカーという自動車の充電エコシステム全体を単一のプラットフォームで提供しています。Plugsurfing は、充電ポイント運営会社に、国ごとの規制から顧客への多様な支払いオプションまで、すべてを管理するためのバックエンドのクラウドソフトウェアを提供しています。Plugsurfing の充電プラットフォームを利用する 100 万人以上のドライバーは、欧州全域に 30 万カ所以上存在する充電スタンドを日々快適に利用しています。このプラットフォームベースのエコシステムは、すでに 1,800 万回を超える充電セッションを処理しています。Plugsurfing は、2018 年に Fortum Oyj によって完全買収されました。
Plugsurfing は、30 万件の充電ステーションの情報を保存し、モバイル、ウェブ、コネクテッドカー・ダッシュボード・クライアントといった様々なデバイスから送られてくる検索やフィルタリングといったリクエストを捌くために中央データストアとして Amazon OpenSearch Service を使用しています。
利用者の増加に伴い、Plugsurfing は需要と規模に対応するため、OpenSearch Service のクラスタに複数の読み取り用レプリカを作成しました。しかし時間の経過と需要の増加に伴い、このソリューションはコストがかさむようになり、コストパフォーマンスの面でも限界がありました。
AWS EMEA Prototyping Labs はこの問題を解決するために Plugsurfing チームと 4 週間ハンズオンプロトタイピングで協力し、現在のソリューションと比較して 70% のコスト削減と 2 倍のパフォーマンスメリットを得ることができました。この投稿では、Plugsurfing と共にテストした様々なアプローチとアイデアを紹介します。
課題:コストを抑えながら、より高いトランザクションを秒単位でスケーリングすること
レガシーソリューションの重要な課題の 1 つは、コストを抑えながら、API からの高いトランザクション/秒(TPS) に対応することでした。モバイル、ウェブ、電気自動車内ダッシュボードはそれぞれ異なるユースケースで異なる API を使用していますが、すべて同じクラスタを照会しています。そのため、コストの大部分は OpenSearch Service クラスタから発生していました。レガシーソリューションでより高い TPS を達成するための解決策は、OpenSearch Service クラスターを拡張することでした。
次の図は、レガシーアーキテクチャを示したものです。

Plugsurfing APIは、4つの異なるユースケースのためのデータを提供する役割を担っています。
- 半径検索 – 目的地(またはGPS上の現在地)から半径x km以内にあるすべてのEV充電ステーション(緯度/経度)を検索します。
- 矩形検索 – 目的地(またはGPS上の現在地)を中心とした縦×横のボックス内にあるすべてのEV充電ステーションを検索します。
- ジオクラスタリング検索 – 指定されたエリア内に集中しているEV充電ステーションをすべてクラスター化(グループ化)して検索します。例えば、ドイツ全土のすべてのEV充電器を検索すると、ミュンヘンに50、ベルリンに100といった結果が得られます。
- フィルタリングによる半径検索 – プラグタイプや定格電力などのフィルタリングにより、利用可能または使用中のEV充電器から結果を絞り込むことができます。
OpenSearch Service のドメイン構成は以下の通りでした。
- m4.10xlarge.search x 4 ノード
- Elasticsearch 7.10 バージョン
- 単一インデックスに 30 万件の EV 充電器設置場所が格納されており、シャードは5個、レプリカは1個でした。
- ネストされたドキュメント構造
次のコードは、ドキュメントの例です。
実験の概要
AWS EMEA Prototyping Labs は、パフォーマンス最適化とソリューション全体のコスト削減のために、3 つのハイレベルなアイデアを試す実験的アプローチを提案しました。
プロトタイピング用 AWS アカウントで Amazon Elastic Compute Cloud (EC2) インスタンスを立ち上げ、k6(開発者やQAエンジニアのための負荷テストを簡単にするオープンソースツール)に基づいたベンチマークツールをホストしました。その後、スクリプトを使って本番データを様々なデータベースへダンプ、復元して異なるデータモデルと適合するように変形させました。その後、k6 スクリプトを実行して、ユースケース、データベース、データモデルの組み合わせごとにパフォーマンスメトリクスを実行し、記録しました。また、AWS Pricing Calculator を使って、各実験のコストを見積もりました。
実験1:AWS Gravitonを利用し、OpenSearch Service のドメイン構成を最適化する
プロトタイプ環境において、従来の OpenSearch Service ドメインを複製、ベンチマークし、性能とコストのベースラインを定めました。次に、現在のクラスタ設定を分析し、以下の変更をテストすることを推奨しました。
- AWS Graviton ベースのメモリ最適化 EC2 インスタンス(r6g)× 2ノードをクラスタで使用する。
- データ量(全文書)が 1GB 未満であるため、シャード数を5個から1個に削減する。
- リフレッシュ間隔の設定をデフォルトの1秒から5秒に増やす。
- ドキュメント全体を非正規化し、不可能な場合は、検索クエリの一部であるすべてのフィールドを非正規化する。
- Elasticsearch 7.10 から Amazon OpenSearch Service 1.0 にアップグレードする。
Plugsurfing は、同じデータで複数の新しい OpenSearch Service ドメインを作成し、レガシーベースラインに対してベンチマークを行いました。結果を以下に示します。黄色の行は既存環境におけるパフォーマンスを表し、緑色の行は与えられたユースケースに対して行われたすべての実験のうち、最良の結果を表しています。
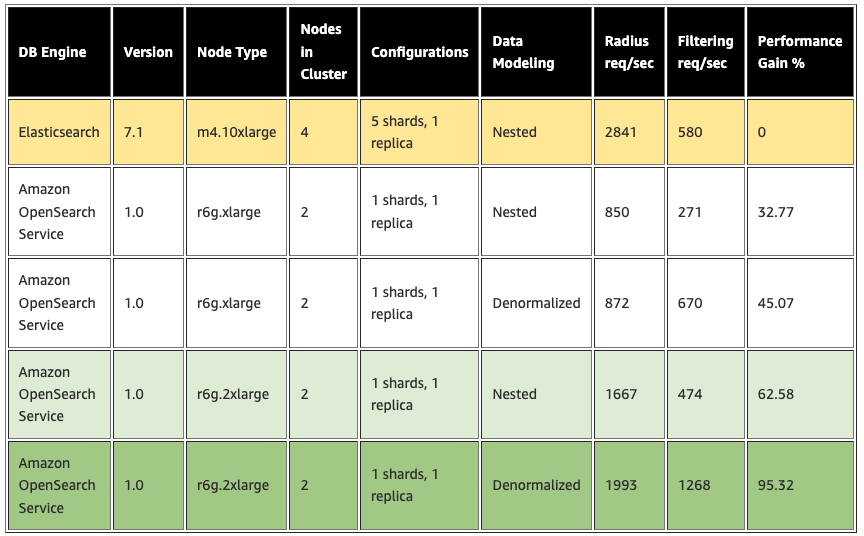 この実験により、Plugsurfing は半径とフィルタリングのユースケースで 95%(2倍)のパフォーマンスを得ることができました。
この実験により、Plugsurfing は半径とフィルタリングのユースケースで 95%(2倍)のパフォーマンスを得ることができました。
実験2: 異なるユースケースに沿った AWS 上の目的別データベースを利用する
クエリによっては Amazon OpenSearch Service ではなく RDB や NoSQL といった他のデータベースの方が性能が出るのではないかというアイデアから、Amazon Aurora PostgreSQL-Compatible Edition および Amazon DynamoDB を、様々なユースケースに対して多くのデータモデルで広範囲にテストしました。
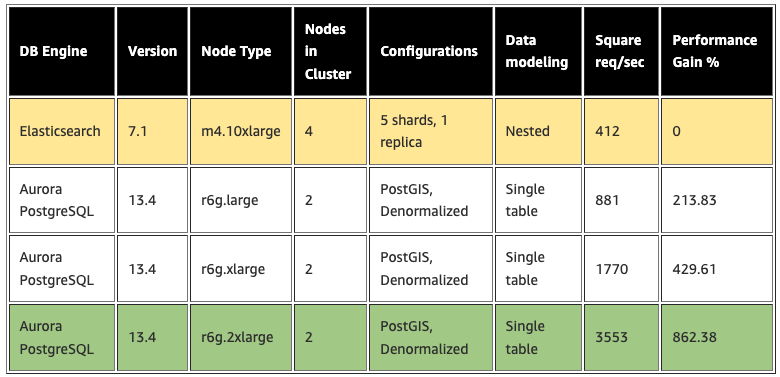
私たちは、Aurora PostgreSQL クラスタで、Reader に db.r6g.2xlarge シングルノードを、Writer に db.r6g.large シングルノードを選択し、矩形検索のユースケースをテストしました。矩形検索では、以下の手順で設定した1つの PostgreSQL のテーブルを使用しました。
- 緯度・経度を格納するデータ型として geo 検索テーブルを作成します。
CREATE TYPE status AS ENUM ('available', 'inuse', 'out-of-order'); CREATE TABLE IF NOT EXISTS square_search ( id serial PRIMARY KEY, geog geography(POINT), status status, data text -- Can be used as json data type, or add extra fields as flat json ); - geog フィールドにインデックスを作成します。
- 矩形検索ユースケースのデータをクエリします。
結果としては次の表に示すように、矩形検索のユースケースにおいて 8 倍の TPS の向上を達成しました。
 次にジオクラスタリング検索のユースケースを DynamoDB モデルでテストしました。パーティションキー (PK) は3つの要素で構成されています。
次にジオクラスタリング検索のユースケースを DynamoDB モデルでテストしました。パーティションキー (PK) は3つの要素で構成されています。<zoom-level>:<geo-hash>:<api-key>, そしてソートキーは EV充電器の現在の状態です。キーの設計は以下のように検討しました。
- ユーザが設定した地図のズームレベル
- ユーザーのビューポート領域内の地図タイルをもとに算出したジオハッシュ (ズームレベルごとに地球地図は複数のタイルに分割され、各タイルはジオハッシュとして表現される)
- API 利用者を特定するための API キー
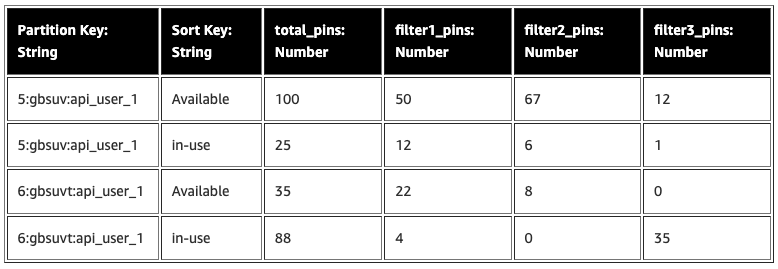
Writer (ライター) は、EV充電器のステータスがすべてのズームレベルで更新されるたびに、各フィルター条件と充電器のステータスに対してカウンターを更新(インクリメントまたはデクリメント)します。このモデルにより、Reader (リーダー) は、与えられたズームレベルでユーザーが表示可能なすべての地図タイルに対して、単一のダイレクトパーティションヒットで事前にクラスタ化されたデータを照会することができます。
この DynamoDB モデルにより、ジオクラスタリングのユースケースで 45 倍の読み込み性能を得ることができました。しかし、ライター 側では、1つのEV充電器のステータスが更新されたときに、事前に数値を計算し、複数の行を更新するという余分な作業が発生しました。その結果を表にまとめると、以下のようになります。
 実験3:AWS Lambda@Edge と AWS Wavelength を使用してネットワークパフォーマンスを向上させる
実験3:AWS Lambda@Edge と AWS Wavelength を使用してネットワークパフォーマンスを向上させる
私達は Lambda@Edge と AWS Wavelength を使って、エッジにある API の一部をユーザーの近くに移動させ、ネットワークパフォーマンスを最適化することを推奨しました。電気自動車のダッシュボードは、車が接続しているのと同じ 5G ネットワーク接続を利用し、AWS Wavelength で Plugsurfing の API を呼び出すことができます。
プロトタイプ後のアーキテクチャ
プロトタイプ後のアーキテクチャでは、purpose-built databases on AWS を使用し、4つのユースケースすべてにおいてより良いパフォーマンスを達成しました。私たちはその結果を見て、それぞれのユースケースでどのデータベースが最も性能が良いかに基づいて、ワークロードを分割しました。このアプローチは、パフォーマンスとコストを最適化しましたが、リーダとライタに複雑さが加わりました。最終的な実験概要は、与えられたユースケースに適合するデータベースが最高のパフォーマンスを発揮することを表しています(オレンジ色でハイライトされたセル)。
Plugsurfing は、プロトタイプ後すぐに短期プランとして薄緑でハイライトされた設定を実施しており、今後、中期および長期アクション(濃緑)を実施する予定です。
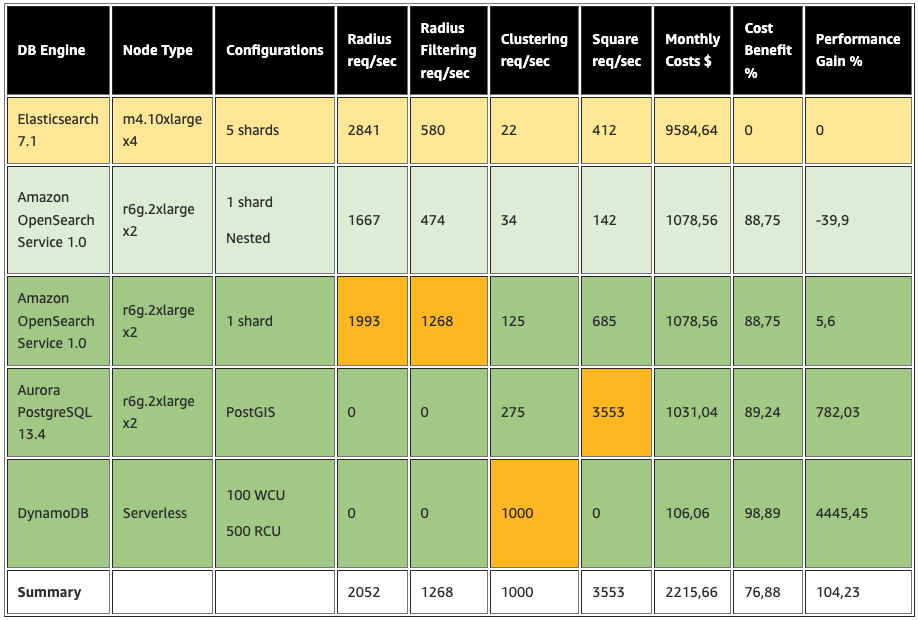
下図は、プロトタイプの結果最適化されたアーキテクチャを示したものです。
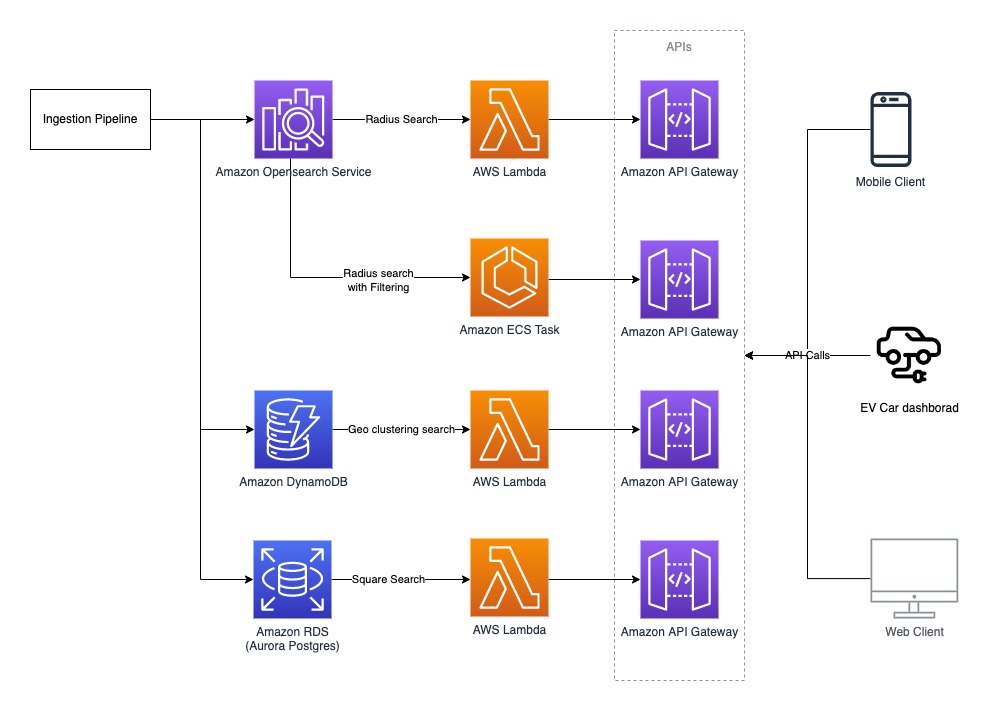
まとめ
Plugsurfing は、DynamoDB、Aurora PostgreSQL などの目的別専用データベースと、Amazon OpenSearch Service 用の AWS Graviton ベースのインスタンスを使用することで、従来の設定よりも2倍のパフォーマンスと70%のコスト削減を達成することが出来ました。その結果、以下のような成果が得られました。
- 半径検索とフィルタリング付き半径検索のユースケースは、AWS Graviton 上の Amazon OpenSearch Service を使用して、非正規化されたドキュメント構造でより良いパフォーマンスを達成しました。
- 矩形検索のユースケースは、Aurora PostgreSQL を使用した方が良い結果を得ました。ここでは、ジオスクエアクエリのために PostGIS 拡張を使用しました。
- ジオクラスタリング検索のユースケースは、DynamoDB を使用した方が良い結果でした。
AWS Graviton インスタンスと AWS 上の目的別データベース を利用したワークロードの最適化についてこの記事がお役に立てば嬉しいです。