Amazon Web Services ブログ
新機能 – AWS IoT Greengrass にコンテナサポートとエッジでのデータストリームの管理を追加
AWS IoT Greengrass を使用してクラウド機能をエッジデバイスに拡大することによって、接続が断続的になっているときでも、リアルタイムにローカルイベントに応答することができます。
本日、より簡単に IoT ソリューション作成をできる 2 つの新機能を追加します。
- Greengrass Docker のアプリケーションデプロイコネクタを使用して、アプリケーションのデプロイをサポートするコンテナ。
- エッジデバイスからデータストリームを収集、処理、エクスポートし、Stream Manager for AWS IoT Greengrass を使用して、そのデータのライフサイクルを管理します。
それでは、これらの新機能を使ってどんなことができるのか、詳しい使い方を見てみましょう。
Greengrass Core Device にコンテナベースアプリケーションをデプロイ
新しく、AWS IoT Greengrass Core Device で、AWS Lambda 機能とコンテナベースアプリケーションを使用できるようになりました。この方法によって、より簡単に、オンプレミスからアプリケーションを移動させたり、ライブラリ、他のバイナリ、コンフィギュレーションファイルなどの依存関係を含む新しいアプリケーションをコンテナイメージを使用して作成したりすることができます。これによって、ユーザーのアプリケーションに一貫性のあるデプロイ環境がもたらされ、デプロイ環境とエッジロケーション間の移植が可能になります。コンテナイメージの中にコード、あるいは実行ファイルをパッケージ化することによって、ユーザーは簡単にレガシーとサードパーティーのアプリケーションをデプロイできます。
この機能を使うために、Docker Compose ファイルを使用したコンテナベースアプリケーションについて説明します。コンテナイメージは、パブリックな、またはプライベートなリポジトリで参照できます。例えば、Amazon Elastic Container Registry (ECR) や、Docker Hubなどです。 初めに、Python を使用したシンプルなアプリケーションと、アプリが表示された回数をカウントする Flask を作成します。
from flask import Flask
app = Flask(__name__)
counter = 0
@app.route('/')
def hello():
global counter
counter += 1
return ''Hello World! I have been seen {} times.\n'.format(counter)
この requirements.txt ファイルは、flask で単一の依存関係を含んでいます。
この Docker ファイルとプッシュしてECRへを使用して、コンテナイメージを作成します。
FROM python:3.7-alpine
WORKDIR /code
ENV FLASK_APP app.py
ENV FLASK_RUN_HOST 0.0.0.0
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY . .
CMD ["flask", "run"]
docker-compose.yml ファイルで、ECR リポジトリのコンテナイメージを参照できます。 Docker Compose files では、複数のコンテナを使用したアプリケーションを描写できますが、この例では 1 つだけ使用しています。
version: '3'
services:
web:
image: "123412341234.dkr.ecr.us-east-1.amazonaws.com/hello-world-counter:latest"
ports:
- "80:5000"
Amazon Simple Storage Service (S3) バケットを docker-compose.yml ファイルにアップロードします。
次に、Amazon Elastic Compute Cloud (EC2) インスタンスをコアデバイスとして使用して、AWS IoT Greengrass グループを作成します。通常、ユーザーのコアデバイスは AWS クラウドの外側にありますが、エッジでユーザーのデプロイへ dev & test 環境を設定し、自動化するには、EC2 インスタンスを使用すると良いかもしれません。
グループが用意できたら、「空」のデプロイを起動し、適切に作動しているか確認します。数秒後、1 つ目のデプロイが完成するので、次にコネクタを追加します。

AWS IoT Greengrass グループのコネクタセクションでAdd a connectorを選択し、「Docker」を検索します。Docker Application Deploymentを選択し、Nextを押します。

次に、コネクタのパラメータを設定します。S3 の docker-compose.yml ファイルを選択します。AWS IoT Greengrass グループで使用されているAWS Identity and Access Management (IAM) は、S3からファイルを取得し、トークンを認証し、ECRからイメージをダウンロードするために許可が必要です。Docker Hub などのプライベートリポジトリを使用する場合、AWS Secret Managerの統合を利用することができ、コネクタや Lambda 機能で、サービスやアプリケーションと相互作用するローカルなシークレットが使いやすくなります。

前と同様に、変更をデプロイします。そうすると、新しいコンテナベースアプリケーションがインストールされるので、AWS IoT Greengrass コアデバイスを開始します。

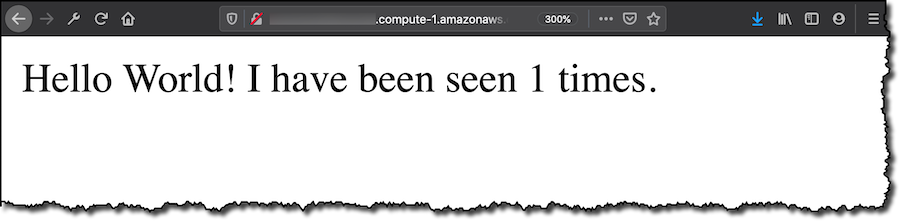
デプロイしたウェブアプリをテストするために、コアデバイスを使用しているEC2 インスタンスのセキュリティグループで、HTTP ポートにオープンアクセスします。ブラウザに接続した際、Flask アプリケーションが訪問数のカウントを開始していることを確認します。 これでコンテナベースアプリケーションが AWS IoT Greengrass コアデバイスで作動しました。
この例よりももっと複雑なアプリケーションをデプロイすることもできます。それでは、今日紹介するもう一つの新機能についても見てみましょう。
Stream Manager for AWS IoT Greengrassの使用
ビデオ処理、イメージ認証、またはエッジのセンサーからの大容量データ収集のような一般的なケースでは、ユーザー自身のデータストリーム管理機能を形成する必要があることがよくあります。新しいストリームマネージャーでは、標準メカニズムを Greengras Core SDK に付け加えられることによってこの手順がシンプルになります。SDK では、IoT デバイスのデータストリームを処理したり、キャッシュサイズやデータの古さに基づいたローカルデータ保持ポリシーを管理したり、Amazon Kinesis や AWS IoT Analyticsなどの AWS クラウドサービスに直接データを自動的に送信したりできます。
このストリームマネージャーは、設定可能な優先順位付け、キャッシングポリシー、処理能力の利用、そしてストリームごとをベースとしたタイムアウトを追加することで、接続されていない、または断続的な接続シナリオを管理します。接続が予測できない、あるいは処理能力が抑制されている場合、接続されていないとき、再接続するとき、または接続されているときに、この新しい機能によって、ユーザーはアプリケーションのデータマネジメントの動作を定義できます。また、重要なデータのクラウドへのパスを優先し、使用可能時に効率的に接続できます。この機能を使うことで、ユーザーはデーター保持の形成や接続管理の機能性ではなく、特定のアプリケーションを使用するケースに集中することができます。
それでは、実際に Stream Manager をどのように使うか見てみましょう。例えば、AWS IoT Greengrass コアデバイスでは複数のデバイスから多くのデータを受信しています。集めたデータを使って以下の 2 つのことをしたいと思います。
- 優先順位の低い全てのローデータを AWS IoT Analytics にアップロードします。ここでは、Amazon QuickSight を使用してデータを表示したり把握したりできます。
- デバイスの時間と場所にローカルに基づいたデータを集め、集めたデータを、予測メンテナンスのビジネスアプリケーションを使用して処理される Kinesis Data Stream に高い優先順位をもって送ります。
Greengras Core SDK のストリームマネージャーを使用し、2 つのローカルデータシステムを作成します。
- 1 つめのローカルデータシステムでは、IoT Analytics への優先順位の低いエクスポートが設定されており、256 MBまでのローカルディスクを使用できます (これは、制限されたデバイスです)。回復スピードを優先したい場合は、メモリを使用してローカルデータを保存することができます。ローカルスペースがいっぱいになったときは、例えば、クラウドへの接続が切れ、キャッシュをローカルにキャッシュを継続するので、新しいデータを拒否するか、最も古いデータに上書きするかを選択できます。
- 2 つめのローカルデータストリームは、データを Kinesis Data Stream へ高い優先順位を持ってエクスポートし、128MB までのローカルディスクを使用できます (集めたデータのため、必要なスペースは同じ時間に対してより少なくなります)。

以下が、この設計の中でのデータの流れです。
- センサーデータは、1 つめのローカルデータストリームに書き込むProducer Lambda 機能によって集められます。
- 2つめのAggregator Lambda 機能は、1 つめのローカルデータストリームから読み取りをして、収集を実施し、2 つめのローカルデータストリームに書き出します。
- Reader コンテナベースアプリ (Docker アプリケーションデプロイコネクターを使ってデプロイされたもの) は、ディスプレイパネルにリアルタイムで集めたデータをレンダリングします。
- Stream Manager によって、設定とローカルデータストリームのポリシーに基づいてクラウドへの摂取が管理されるので、開発者はデバイスのロジックに集中して作業することができます。
Lambda 機能の使用や、以前の構造のコンテナベースアプリは、ほんの1例です。開発に最も使いやすい形へ、混ぜたり、どれか一つに合わせて標準化したりすることもできます。
今すぐ利用可能です
Docker アプリケーションデプロイコネクタと、ストリームマネージャーは、Greengrass version 1.10 で利用可能です。ストリームマネージャーは、Greengrass Core SDK for Java と、Python で利用可能です。カスタマーフィードバックに基づいて、私たちはその他のプラットフォームに関するサポートも追加しています。
これらの新しい機能はそれぞれ独立していますが、今回の例のように、一緒に使うことができます。これらを使うことで、アプリケーションを作成したりエッジデバイスにデプロイしたりする作業が単純化され、ローカルなデータ処理が簡単になり、そして最終段階でストリーミングと分析サービスを統合することができます。皆さんがこの新機能をどのように活用するか、ぜひ教えてください!
— Danilo