Amazon Web Services ブログ
弊社のデータレイク物語:Woot.comはどのようにしてAWS上でサーバーレスデータレイクを構築したか
この投稿では、当社が受け継いできた関係データベース上に構築されたデータウェアハウスの代替としての、cloud-nativeデータウェアハウスの設計についてお話します。
設計過程のはじめで、最も簡単に見える単純なソリューションは、関係データベースから他のものへのリフト&シフトマイグレーションです。しかし、当社は一歩戻り、まずはデータウェアハウスで何が本当に必要とされているかに焦点を当てることに決めました。当社はどのようにして、正しいツールを適した業務に使用することにより、従来のオラクルデータベースをより小さなマイクロサービスに分離できるかに着目し始めました。当社の方法はAWSツールを使用するだけではありませんでした。さらに、それはcloud-native技術を使用して当社を最終状態に持っていくためにマインドシフトすることでした。
このマイグレーションには既存データもマイグレートさせながら新規のデータを流入させるために、新規の抽出、変換、ロード(ETL)パイプラインが必要でした。このマイグレーションのため、AWS Glueに統合されることにより、当社は多くのサーバーを除去し、完全にサーバーレスのデータウェアハウスに移行することができました。
このブログ投稿で、当社は以下をご覧に入れます:
- 当社がデータウェアハウスのためにサーバーレスデータレイクを選択した理由。
- Woot’sシステムのアーキテクチャー図。
- マイグレーションプロジェクトの概要。
- 当社のマイグレーションの結果。
アーキテクチャーおよび設計の関係
こちらは当社が考慮した設計重点の一部です:
- 顧客体験。当社は常にお客様が必要とすることから始め、そこから戻るように業務を行いました。当社のデータウェアハウスは様々なレベルの技術専門性を持った人々による事業を渡って使用されます。 当社は異なるタイプのユーザーが運用の中に識見を持つ能力に焦点を当て、全体的な顧客体験を向上させるために、より良いフィードバックメカニズムを提供します。
- 最小限のインフラストラクチャーメンテナンス。「Wootデータウェアハウスチーム」は本当にたった一人の人です-Chaya! このため、当社がcloud-native技術を使用することができるAWSサービスに集中することは当社にとって重要です。これらは需要が変化し、技術が進化するにつれ、未分化性のインフラストラクチャーの管理といった困難な仕事を取り除きます。
- データソースの変化に対する応答性。当社のデータウェアハウスは内部サービスの範囲からデータを取得します。弊社の既存のウェアハウスでは、これらのサービスへのいずれの更新でETL業務および諸表で手動による更新が必要でした。これらのデータソースのための応答時間は当社の主要関係者にとって重大なことです。このために当社は高性能アーキテクチャーの選択に向けたデータ主動のアプローチが必要でした。
- 生産システムからの分離。当社の生産システムへのアクセスは固く結びついています。複数のユーザーを許容するため、当社はそれを生産システムから分離し、複数のVPCsでのリソースをナビゲートすることの複雑さを最小化する必要がありました。
これらの要件に基づき、当社は運営面およびアーキテクチャーの面の両方で、データウェアハウスを変更することを決定しました。運営の観点から、当社はデータ摂取の目的で新規の共有応答モデルを設計しました。アーキテクチャーの面で、当社は従来の関係データベースに代わってサーバーレスモデルを選択しました。これら2つの決定は、当社がマイグレーションで行った、すべての設計および実装の決定を動かすこととなりました。
当社が共有応答性モデルに移行するにあたって、複数の重要な点が浮上しました。第一に、当社のデータ摂取の新しい方法はWootの技術組織にとっては主要な文化シフトでした。過去に、データ摂取は専らデータウェアハウスチームの担当で、サービスからデータを引っ張るためにカスタム化されたパイプラインが必要でした。当社は「押し、引かない」にシフトしました:サーバーがデータウェアハウスにデータを送信するべきである。
これが共有責任が行き着いたところでした。初めて、当社の開発チームがデータウェアハウスのサービスデータ全体の所有権を持ちました。しかし、当社は開発者にミニデータエンジニアになってほしくありませんでした。代わりに、当社はデータをプッシュするために、彼らに開発者の既存のスキルセットに適合する簡単な方法を示しました。データは当社のウェブサイトで使用される技術の範囲でアクセス可能である必要がありました。
これらの検討されたことは当社をサーバーレスデータウェアハウス向けの、以下のAWSサービスを選択することに導きました。
- データ摂取用Amazon Kinesis Data Firehose
- データ保存用Amazon S3
- データ処理用AWS Lambda および AWS Glue
- AWS データマイグレーションサービス (AWS DMS) および データマイグレーション用AWS Glue
- 統合およびメタデータ管理用AWS Glue
- クエリおよびデータ視覚化用 Amazon Athena および Amazon QuickSight
以下のデータグラムは当社がどのようにこれらのサービスを使用するかをハイレベルで示します。
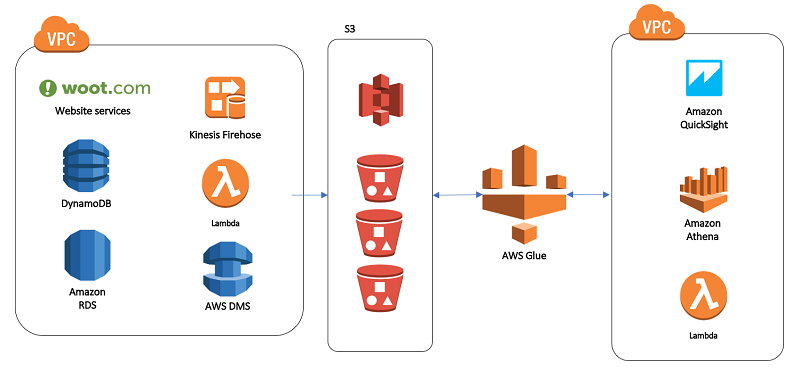
トレードオフ
これらの構成要素は共に当社のすべての要件を満たし、共有責任モデルを実行可能にしました。しかし、当社はリフト&シフトマイグレーションをもう一つの関係データベースと比較し、数回のトレードオフを行いました。
- 最大のトレードオフは先行投資の努力対進行中のメンテナンスでした。当社はすべてのデータパイプラインをもって効果的に白紙の状態から開始し、新しい技術を当社のすべてのウェブサイトサービスに導入しました。これには複数のチームを渡り協力的な努力が必要となりました。最小限の現行メンテナンスは核心要件でした。当社が使用するサーバーレスコンポーネントの管理されたインフラストラクチャーの優位点を利用するために、当社は快くこのトレードオフを行いました。
- もう一つのトレードオフは非技術ユーザー対ビッグデータテクノロジーを利用することの有用性のバランスを取ることでした。顧客体験を核心要件にすることは、当社がこれらのトレードオフを検討するときに、意思決定を導くのを助けました。最終的には、他の関係データベースへの切り替えは、当社のお客様が同じ体験をするだけで、より良い体験をするわけではなかったのです。
Kinesis Data Firehose および Lambdaでデータパイプラインを構築する

当社のウェブサイトはすでにAWS上で実行されているので、AWS SDKを使用してデータをKinesis Data Firehoseに送信することは開発者に容易に売り込めました。以下のようなことが検討されました:
- Kinesis Data Firehose用のDirect PUT摂取は開発者が実装するには自然であり、当社のサーバーを渡って使用されるすべての言語で使用でき、Amazon S3にデータを配信します。
- データ保存のためにS3を使用するということは、当社が自動的に高い利用性、スケーラビリティー、および耐久性を獲得するということです。そしてS3はグローバルリソースであるため、当社は個別のAWSアカウント内のデータウェアハウスを管理でき、複数のVPCsをナビゲートする複雑さを回避できます。
当社はまたAmazon DynamoDB諸表に保存されたデータを消費します。Kinesis Data Firehoseは再びソリューションの核心を提供し、今回はDynamoDB Streams および Lambdaを結合させました。各DynamoDB諸表で、当社はDynamoDB Streamsを利用可能にし、ストリームを使用してLambda関数をトリガーします。
Lambda関数はDynamoDBストリーム出力を浄化し、浄化されたJSONをboto3を使用してKinesis Data Firehoseに書き込みます。これを行った後、それを他の処理とまとめ、データをS3に出力します。詳細については、AWSのデータベースブログのAWS Lambda および Amazon Kinesis Firehoseを使用して、データをAmazon DynamoDBからAmazon Auroraにストリーミングするには をご覧ください。
Lambdaは私たちにさらにきめ細かいコントロールをもたらし、以下のアカウントの間でファイルを移動できるようにします:
- 当社はS3バケット上でS3イベント通知を可能にし、Kinesis Data Firehoseがバケットにオブジェクトを置いたときにはいつでも通知を受信できるようにAmazon SNS トピックを作成しました。
- SNSトピックがLambda関数をトリガーし、Kinesisが出力してそれを当社が選択するパーティション構造内のデータウェアハウスアカウントに移動します。
S3イベント通知はLambda関数をトリガーできますが、S3バケットおよびLambda関数は個別のアカウント内にあったので、当社は仲介としてSNSを選択しました。
AWS DMS および AWS Glueでの既存データのマイグレート

当社は既存のRDSデータベースからS3にデータをマイグレートさせる必要があり、当社はAWS DMSによって遂行しました。DMSはDMS ドキュメンテーションで説明される通り、元々ターゲットとしてS3をサポートします。
これをセットアップすることは比較的簡単です。当社はDMSの接続属性を微調整することにより、生産VPCから直接データを個別のデータウェアハウスアカウントにエクスポートしました。当社が使用した文字列はこれでした:
"cannedAclForObjects=BUCKET_OWNER_FULL_CONTROL;compressionType=GZIP;addColumnName=true;”
このコードはバケットオーナー (送信先データウェアハウスアカウント)に所有権を与え、ファイルを圧縮して保存コストを抑え、すべてのコラム名を含みます。データがS3に入った後、当社はAWS Glueクローラーを使用して、すべてのエクスポートされた諸表のスキマを推測して、その後ソースデータと比較されました。
AWS Glueにより、当社が克服したいくつかの課題はこちらです:
- フォーラムおよびブログ投稿などの体系化されていない文字データ。DMSはこれらをCSVにエクスポートします。このアプローチは文字データ内にあるカンマと衝突を起こしました。当社は、コラムを直接エンコードするため影響のないAWS Glueを使用してRDSからS3にデータをParquet形式でエクスポートする方法に切り替えました。
- アカウント間のエクスポート当社はこのコードを含めることによってこれを解決しました。
"glueContext._jsc.hadoopConfiguration().set("fs.s3.canned.acl", "BucketOwnerFullControl”)”
バケットオーナーにAWS Glueにより作成されたすべてのS3ファイルへのアクセス権を与えるために、各AWS Glueジョブの最上部に書かれました。
全体的に、AWS DMSはセットアップがより速く、ルールベースの変換での大容量データのエクスポートに適しました。AWS Glueはジョブをセットアップするために更なる先行努力を必要としましたが、当社が出力に対して更なるコントロールが必要であった場合にはより良い結果をもたらしました。
既存の生データ (CSV または JSON) をParquetに変換したい場合は、AWS Glueジョブをセットアップしてそれを行えます。この手順は AWS Big Data Blog post AWS Glue および Amazon S3によりデータレイクファンデーションを構築するで説明されています。
AWS Glue、Amazon Athena、および Amazon QuickSightですべてをまとめる

データがS3に到着した後、本当の楽しみが始まります:実際にデータを使用して作業をします! 私がデータエンジニアであることを伝えてくれますか? 私にとって、楽しみの大きな部分はAWS Glueを試して回ることです:
- AWS Glueは当社のETLジョブスケジューリングを扱います。
- AWS Glue クローラーはAWS Glue データカタログのメタデータを管理します。
クローラーは私たちにスキマの変更に反応できるようにする「秘密のソース」です。パイプラインを通して、当社は各手順をできるだきスキマらしくすることを選び、あらゆるスキマ変更がAWS Glueに到達するまで流れるようにしました。
しかし、生データはしばしば複写や不正確なデータタイプがあるため、当社のほとんどのビジネスユーザーにとっては理想的ではありません。最も重要なことに、Firehose外のデータはJSON形式ですが、当社はParquet形式を使用することから迅速に重要なクエリパフォーマンスを獲得することを観測しました。こちらに、当社はBig Data Blog postのAmazon Athena用トップ10 パフォーマンス チューニングのヒントでパフォーマンスのヒントの一つを使用しました.
当社の共有責任モデルにより、データウェアハウスおよび BIチームはデータのレポートの準備が整った精選されたデータセットへの最終処理を担当します。Lambda および AWS Glueを使用することにより、これらのチームがPython および SQL (Amazon データエンジニアリング および BI の役割用のコア言語)で作業できるようになります。それはまたチームに最小限のインフラストラクチャーセットアップまたはメンテナンスでコードを配置できるようにします。
当社のETL手順は以下の通りです:
- スケジュールされたトリガー。
- 連続する手前のジョブに依存するジョブの流れをコントロールする一連の条件付きトリガー。
- 生データを読み込む多数のジョブを渡る類似のパターン、データの重複排除、その後Parquetへの書き込み。当社は関数のPythonライブラリを作成し、S3にアップロードすることにより、このロジックを集中しました。当社はその後追加のPythonライブラリーとしてのAWS Glue内のライブラリーを含めました。この行い方の詳細については、AWS Glueドキュメンテーションの AWS GlueによりPython ライブラリーを使用する をご覧ください。
当社はまたビジネスメトリックでレポート諸表を作成するために使用された複雑なジョブをマイグレートしました。
- AWS GlueのPySparkの使用は、ジョブ内にSparkSQLクエリを直接内蔵できるため、これらクエリのマイグレーションを単純化しました。
- SparkSQLへの変換は試行錯誤を伴いましたが、最終的にSQLクエリをSparkメソッドに翻訳するよりは、必要な作業が少なくなりました。しかし、以前Pandas または Sparkで作業をした当社のBIチームの人員にとっては、Sparkデータフレームで作業をすることは自然の変遷でした。Pythonを学ぶ前にSQLを数年使用した者として、私はPySparkのおかげでSQLおよびオブジェクト指向フレームワークとの間で迅速に切り替えができることに感謝します。
AWS Glueジョブを使用することのもう一つの隠れた利点は、Python (Lambdaのような)AWS Glueバージョンはすでにboto3がインストールされていることです。これにより、ETLジョブは追加設定なしで直接AWS APIオペレーションを使用できます。
例えば、当社の長時間実行のジョブの一部は、AWS GlueがS3にデータを書き込んでいる間、ユーザーがその諸表をクエリした場合は読み込み不一致を起こしました。当社はAWS Glueジョブを調整して、Sparkを使って一時的なダイレクトリーに書き込み、その後boto3を使用してファイルを所定の位置に移動しました。これを行うことで読み込み不一致が最高90%減少しました。当社が独自のSparkクラスターを管理していたらなかったかもしれない、この機能が容易に利用できることは素晴らしいことでした。
以前の状態および現行状態との比較
当社がすべてのデータセットを所定の位置に置いた後は、当社のお客様はクエリを開始できるようになりました。これは弊社が本当に顧客体験をレベルアップさせたところです。
以前は、ユーザーがSQLクライアントをダウンロードして、ユーザー名とパスワードを求め、セットアップし、SQLを学んでデータを取り出さなければなりませんでした。今では、ユーザーは自動的に用意されるIAMロールを通してAWSマネージメントコンソールにサインインして、Athenaの付いたブラウザーでクエリを実行するだけです。またはSQLをすべて省きたい場合は、当社の既存のActive Directoryサーバーを通して管理されるアカウントでAmazon QuickSightアカウントを使用することができます。
Active Directoryとの統合は当社にとって大きな勝利でした。当社はユーザーにアカウントが作成されるのを待たずに、または個別のクレデンシャルを管理せずに起きて走ってほしかったのです。当社はすでに複数のリソースにアクセスするために企業を渡り、Active Directoryを使用しますAmazon QuickSight Enterprise Editionにアップグレードしたことにより、当社は既存のADグループおよびクレデンシャルでアクセスを管理できるようになりました。
マイグレーションの結果。
当社の従来のデータウェアハウスは5年間にわたって開発されました。当社はAWS Glueを使用して、約3か月間でそれをサーバーレスデータレイクとして再創出しました。
最後に、単にもう一つの関係データベースにマイグレートするよりも懸命な努力を要しました。当社はまた自分たちにとって比較的新しい多くの製品を使用したため(特にAWS Glue)、更に多くの不確実性を扱いました。
しかし、マイグレーションが完了してからの数か月間、当社は新しいツールについてデータウェアハウスのユーザー様から素晴らしいフィードバックをいただきました。当社のユーザーはこれらのことに驚かれました:
- Athenaの速さ。
- Amazon QuickSightの直感性および美しさ。お客様はセットアップが不要であることを大変気に入られました-当社のCEOさえも使い始めたほど十分に簡単です!
- Athena並びにAWS Glue データカタログは本当のビッグデータプラットフォームのパフォーマンス獲得をもたらしましたが、エンドユーザーにとっては関係データベースの容貌と感覚を残します。
まとめ
運営の観点から、投資はすでに清算を開始しています。文字通り:当社の運営コストは90%近く下がりました。
個人的に、私は最近3週間のバケーションを取ることができ、サーバーレスインフラストラクチャーのおかげで一度もページをめくらなかったことにスリルを感じました。そして私自身に加え当社のBIエンジニアにとって、S3セントリックアーキテクチャーは、Amazon EMR、Amazon SageMaker、Amazon Redshift Spectrum、および Lambdaのような他のサービスとシームレスに統合した新技術を用いて、私たちに実験させることができます。これらのサービスが、当社が採用してからの時間でどれほど成長したかを目にするのはエキサイティングなことです (例えば、Amazon CloudWatch メトリック および Athenaの発売計画の最近のAWS Glueの発売)。
当社は自分たちと共に成長し続ける技術に投資したことにスリルを感じています。当社はこの志高いマイグレーションを遂行している自分たちのチームに信じられないほど誇りを持っています。当社は自分たちの経験が他のエンジニアたちを奮い立たせ、独自のデータレイクを構築することに飛び込んでゆくことを願います。
追加情報については、これらの類似のAWS Big Dataブログ投稿をご覧ください:
著者について
 Chaya Carey はWoot.comでのiデータエンジニアです 。Wootで、彼女はデータウェアハウスおよび他のスケーラブルなデータソリューションの管理を担当しています。休日、彼女はシアトルのバーおよびレストランシーン、書籍およびビデオゲームについて情熱的です。
Chaya Carey はWoot.comでのiデータエンジニアです 。Wootで、彼女はデータウェアハウスおよび他のスケーラブルなデータソリューションの管理を担当しています。休日、彼女はシアトルのバーおよびレストランシーン、書籍およびビデオゲームについて情熱的です。
 Karthik Odapally は、AWS のシニア ソリューション アーキテクトです。コスト効率とスケーラビリティの高いソリューションをクラウド上に構築するのに、情熱を傾けています。暇があれば、ここパシフィックノースウェストで、家族や友人にクッキーやカップケーキを焼いています。ヴィンテージのレーシングカーを愛しています。
Karthik Odapally は、AWS のシニア ソリューション アーキテクトです。コスト効率とスケーラビリティの高いソリューションをクラウド上に構築するのに、情熱を傾けています。暇があれば、ここパシフィックノースウェストで、家族や友人にクッキーやカップケーキを焼いています。ヴィンテージのレーシングカーを愛しています。