AWS Database Blog
How to Stream Data from Amazon DynamoDB to Amazon Aurora using AWS Lambda and Amazon Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
We find that customers running AWS workloads often use both Amazon DynamoDB and Amazon Aurora. Amazon DynamoDB is a fast and flexible NoSQL database service for all applications that need consistent, single-digit millisecond latency at any scale. Its flexible data model and reliable performance make it a great fit for mobile, web, gaming, ad tech, IoT, and many other applications.
Amazon Aurora is a MySQL-compatible relational database engine that combines the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases. Amazon Aurora provides up to five times better performance than MySQL with the security, availability, and reliability of a commercial database at one-tenth the cost.
To put these together, imagine you have built a custom web analytics engine, with millions of web clicks registered within DynamoDB every second. Amazon DynamoDB operates at this scale and can ingest high-velocity data. Now imagine needing to replicate this clickstream data into a relational database management system (RDBMS), such as Amazon Aurora. Suppose that you want to slice and dice this data, project it in various ways, or use it for other transactional purposes using the power of SQL within stored procedures or functions.
To effectively replicate data from DynamoDB to Aurora, a reliable, scalable data replication (ETL) process needs to be built. In this post, I show you how to build such a process using a serverless architecture with AWS Lambda and Amazon Kinesis Firehose.
Solution overview
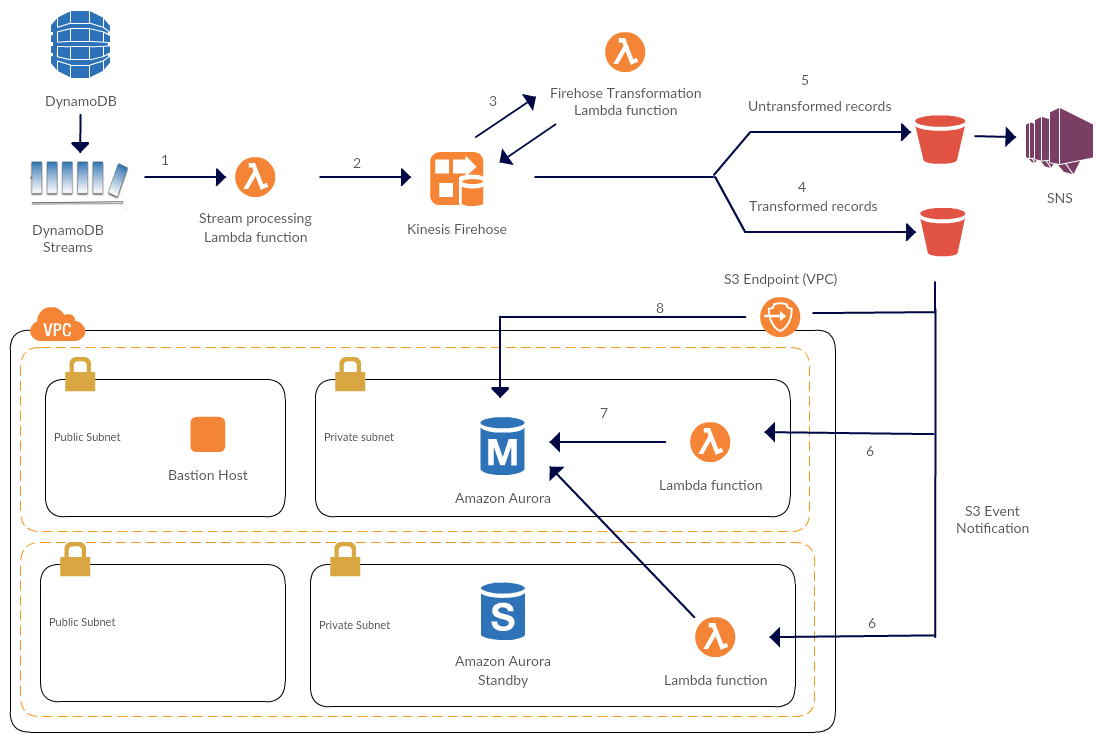
The following diagram shows the solution architecture. The motivations behind this architecture are the following:
- Serverless – By offloading infrastructure management to AWS, you achieve zero-maintenance infrastructure. You also simplify security management for the solution, because there is no need to use keys or passwords, and you optimize cost. In addition, you automate scaling with concurrent Lambda function executions based on shard iterators in DynamoDB Streams.
- Ability to retry failures – Because the data movement process needs to be highly reliable, the process needs to handle failures in each step and provide an ability to retry. This architecture does that.
- Optimization of concurrent database connections – By buffering records based on interval or buffer size, you can reduce the number of concurrent connections to Amazon Aurora. This approach helps avoid connection timeouts.
- Separation of concerns – Using AWS Lambda, you can separate each concern of the data replication process. For example, you can separate the extract phase as processing DynamoDB streams, the transform phase as Firehose-Lambda transformation, and the load phase as bulk insert into Aurora.
Here’s how the solution works:
- DynamoDB Streams is the data source. A DynamoDB stream allows you to capture changes to items in a DynamoDB table when they occur. AWS Lambda invokes a Lambda function synchronously when it detects new stream records.
- The Lambda function buffers items newly added to the DynamoDB table and sends a batch of these items to Amazon Kinesis Firehose.
- Firehose is configured to deliver data it receives into Amazon S3 by performing data transformation using a Lambda function. When you enable Firehose data transformation, Firehose buffers incoming data and invokes the specified Lambda function with each buffered batch asynchronously. The transformed data is sent back from Lambda to Firehose for buffering.
- Firehose delivers all transformed records into an S3 bucket.
- Firehose also delivers all untransformed records into an S3 bucket, performing steps 4 and 5 at the same time. You can subscribe an Amazon SNS topic to this S3 bucket for further notification, remediation, and reprocessing. (Full discussion of notification is outside the scope of this blog post.)
- Every time Firehose delivers successfully transformed data into S3, S3 publishes an event and invokes a Lambda function. This Lambda function is configured to run within a VPC.
- The Lambda function connects to the Aurora database and executes a SQL expression to import data in text files directly from S3.
- Aurora (running within a VPC private subnet) imports data from S3 by using the S3 VPC endpoint.
Solution implementation and deployment
Next, I walk you through the steps required to get this solution working. The steps outlined following require you to create a VPC environment by launching an AWS CloudFormation stack and run a series of AWS CLI commands.
AWS service charges might apply while using AWS services to walk through these steps.
Step 1: Download the solution source code
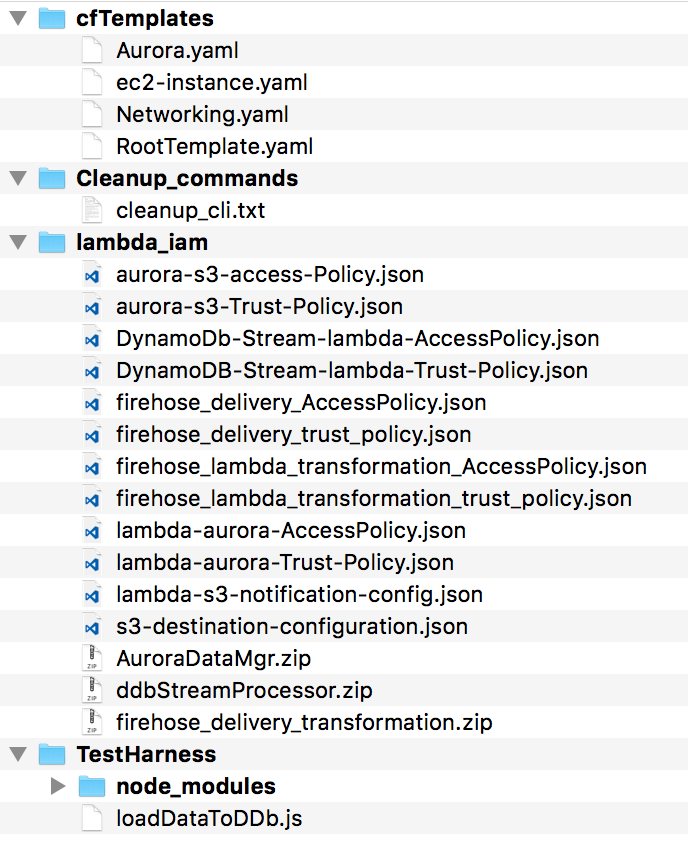
The solution outlined in this blog post relies on many Lambda functions and on creating many AWS Identity and Access Management (IAM) policies and roles. Download the source code for this solution:
git clone https://github.com/awslabs/dynamoDB-data-replication-to-aurora.git
In this repository, you’ll find the folder structure following. Navigate to the lambda_iam folder to execute the subsequent steps in this blog post.
Step 2: Create an S3 bucket for Firehose delivery
Amazon Kinesis Firehose can deliver real-time streaming data into Amazon S3. To do so, you first create an S3 bucket. Then you create folders to contain the final transformed records and a data backup in case of unsuccessful attempt to process records.
Step 3: Modify IAM policies, S3 event notification, and Firehose-S3 delivery configuration files
Next, you modify the following files by replacing the placeholders AWS_REGION,
AWS_ACCOUNT_NUMBER, and BUCKET_NAME with values for your AWS region ID, your AWS account number, and the name of the S3 bucket created in step 2.
aurora-s3-access-Policy.jsonDynamoDb-Stream-lambda-AccessPolicy.jsonfirehose_delivery_AccessPolicy.jsonlambda-s3-notification-config.jsons3-destination-configuration.jsonfirehose_delivery_trust_policy.json
Step 4: Set up an Aurora cluster using CloudFormation
Next, you launch the AWS CloudFormation stack with the Launch Stack button following. The CloudFormation template creates a VPC with public and private subnets. The template also launches an Amazon Aurora database cluster within the private subnet, and in addition a bastion host with a public IP within the public subnet.
![]()
Step 5: Configure an Aurora DB cluster
Once the CloudFormation stack is complete, you must modify the Aurora cluster in order to load data into the DB cluster from text files in an S3 bucket. The steps involved are the following:
- Allow Amazon Aurora to access Amazon S3 by creating an IAM role and attaching the trust and access policy that’s been created.
- Associate that IAM role with your Aurora DB cluster by creating a new DB cluster parameter group and associating this new parameter group with the DB cluster.
- Reboot the primary DB instance.
Step 6: Configure DynamoDB streams and the Lambda function that processes the streams
- Create a new DynamoDB table with a stream enabled. In the subsequent steps, you will create a trigger by associating an AWS Lambda function with the stream.
- Create a Lambda execution role.
- Create a Lambda function to process the DynamoDB stream.
- Create a trigger by associating the Lambda function with the DynamoDB stream.
Step 7: Create and configure the Lambda data-transformation function for Firehose
- Create a Lambda execution role.
- Create the Lambda data-transformation function.
This function validates the records in the incoming stream with a JSON schema. On match, it parses the incoming JSON record and transforms it into comma-separated value (CSV) format.
Step 8: Create and configure the Firehose delivery stream to deliver data to S3
When using an Amazon S3 destination, Firehose delivers data to your S3 bucket. For creation of a delivery stream, you must have an IAM role. Firehose assumes that IAM role and gains access to the specified bucket and key. Firehose also uses that IAM role to gain access to the Amazon CloudWatch log group and to invoke the Data Transformation Lambda function.
- Create an IAM role that provides access to an S3 bucket, key, the CloudWatch log groups and the Data Transformation Lambda function.
- Create the Firehose delivery stream by specifying an S3 destination configuration.
- Sign in to the AWS Management Console, and navigate to the Firehose console. Choose the delivery stream named
webAnalytics. In the Details tab, choose Edit. Select Enabled for Data transformation, and choose thefirehose_delivery_rolefor IAM role. For Lambda function, selectfirehoseDeliveryTransformationFunction. Then choose Save to save this configuration.

Step 8: Create and configure the Lambda function to access VPC resources
To import data from an S3 bucket into Amazon Aurora, you configure a Lambda function to access resources within a VPC.
- Create an IAM execution role for the Lambda function.
- Create the Lambda function specifying a VPC configuration, such as private subnets and a security group. Ensure that the environment variables passed during the CLI execution have the correct values for
AuroraEndpoint, database user (dbUser), and database password (dbPassword). For these values, see the CloudFormation stack output.
The Lambda function makes a connection to the Aurora database. The function then executes the LOAD DATA FROM S3 SQL command to load data from text files within an S3 bucket into the Aurora DB cluster.
Step 9: Configure S3 event notification
Finally, you configure the Lambda function created in the previous step so that S3 can invoke it by publishing events to it. The first step in this process is to provide S3 the permission to invoke the Lambda function.
- Grant S3 the permissions to invoke a Lambda function.
- Configure S3 bucket notification.
Step 10: Testing the solution
The final step is to test the solution.
- In the TestHarness folder of the source code for this blog post, you can find a test harness. This test harness populates the DynamoDB table with data. As a first step, navigate to the TestHarness folder and run the command node
loadDataToDDb.js. - Use Secure Shell (SSH) to connect to the Bastion Host. For more information on connecting using SSH, see the EC2 documentation.
- Because the MySQL client was installed during the bastion host’s bootstrap process, you can connect to the Aurora database using the following command. Ensure that the parameter values are changed appropriately.
- Upon connecting successfully, run the following SQL command at the MySQL prompt.
After this command runs, you should see records in the table.
If you don’t find records in the table, Firehose might be buffering the records before delivering them into S3. To work around this, retry the same SQL code after a minute or so—the time interval is based on the S3 buffer interval value that is currently set. After retrying the code, you should see records inserted into Amazon Aurora.
Conclusion
With DynamoDB Streams and the data-transformation feature of Amazon Kinesis Firehose, you have a powerful and scalable way to replicate data from DynamoDB into data sources such as Amazon Aurora. Although this blog post focused on replicating data from DynamoDB into Aurora, you can use the same general architectural pattern to perform data transformations for other streaming data and ingest that data into Amazon Aurora.
In addition, see these related blog posts:
- Processing DynamoDB Streams Using the Amazon Kinesis Client Library
- Process Large DynamoDB streams Using Multiple Amazon Kinesis Client Library (KCL) Workers.
If you have any questions or suggestions, leave a comment following.
About the Author
Aravind Kodandaramaiah is a partner solutions architect with the AWS Partner Program