AWS Database Blog
Tag: DynamoDB

Data modeling with NoSQL Workbench for Amazon DynamoDB
When using a NoSQL database such as Amazon DynamoDB, I tend to make different optimization choices than what I am accustomed to with relational databases. At the beginning, it was not easy for me, because my relational database experience was telling me to do things differently. To help with that, AWS released NoSQL Workbench for […]

Restore Amazon DynamoDB backups to different AWS Regions with custom table settings
Amazon DynamoDB backup and restore provides simple, fully automated features to create continuous and on-demand backups of your DynamoDB tables and then restore data from those backups. With point-in-time recovery (PITR), you can create continuous backups of your DynamoDB table data. DynamoDB can back up your data with per-second granularity to restore to any given second […]
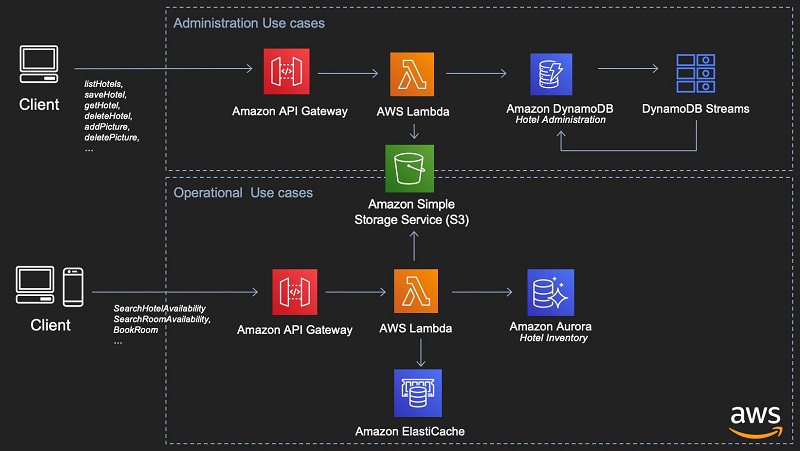
Building enterprise applications using Amazon DynamoDB, AWS Lambda, and Go
Amazon DynamoDB is a fully managed service that delivers single-digit millisecond performance at any scale. It is fully managed, highly available through behind-the-scene Multi-AZ data replication, supports native write-through caching with Amazon DynamoDB Accelerator (DAX) as well as multiple global secondary indexes. Developers can interact with DynamoDB using the AWS SDK in a rich set […]

Make a New Year’s resolution: Follow Amazon DynamoDB best practices
As the new year begins, we encourage you to make a resolution to follow Amazon DynamoDB best practices. Following these best practices can help you maximize performance and minimize throughput costs when working with DynamoDB. Click the following links to learn more about each best practice in the DynamoDB documentation. Design and use partition keys […]

The top 20 most-viewed Amazon DynamoDB documentation pages in 2019
The following 20 pages were the most viewed Amazon DynamoDB documentation pages in 2019. I have included a brief description with each link to explain what each page covers. Use this list to see what other AWS customers have been viewing and perhaps to pique your own interest in a topic you’ve been meaning to explore. […]

Amazon DynamoDB–related videos and slide decks from AWS re:Invent 2019
This blog post includes links to videos and slide decks of the keynotes and Amazon DynamoDB–related sessions from AWS re:Invent 2019. Video recordings were not made of workshops, chalk talks, and builders sessions. As of the publication of this post, not all of the slide decks are available for download, but we will update this […]
2019: The year in review for Amazon DynamoDB
Last updated: December 17, 2019 2019 has been another busy year for Amazon DynamoDB. We have released new and updated features that focus on making your experience with the service better than ever in terms of reliability, encryption, speed, scale, and flexibility. The following 2019 releases are organized alphabetically by category and then by dated […]

Monitoring Amazon DynamoDB for operational awareness
Amazon DynamoDB is a serverless database, and is responsible for the undifferentiated heavy lifting associated with operating and maintaining the infrastructure behind this distributed system. As a customer, you use APIs to capture operational data that you can use to monitor and operate your tables. This post describes a set of metrics to consider when […]
Bring your own encryption keys to Amazon DynamoDB
Today, Amazon DynamoDB introduced support for customer managed customer master keys (CMKs) to encrypt DynamoDB data. Often referred to as bring your own encryption (BYOE) or bring your own key (BYOK), this functionality lets you create, own, and manage encryption keys in DynamoDB, giving you full control over how you encrypt and manage the security […]
A roundup of Amazon DynamoDB launches from November 11–15, 2019
Amazon DynamoDB had six new launches last week, and this post includes a brief summary of each launch to help you keep track of everything that’s new. These launches include region expansions and new and updated features. Ping us @DynamoDB on Twitter if you have questions about any of these launches Monday, November 11 Amazon […]