AWS Database Blog
Building enterprise applications using Amazon DynamoDB, AWS Lambda, and Go
Amazon DynamoDB is a fully managed service that delivers single-digit millisecond performance at any scale. It is fully managed, highly available through behind-the-scene Multi-AZ data replication, supports native write-through caching with Amazon DynamoDB Accelerator (DAX) as well as multiple global secondary indexes. Developers can interact with DynamoDB using the AWS SDK in a rich set of programming languages, including Go, which is the focus of this post.
This post addresses use cases specific to CRUD-intensive applications and how to handle them efficiently using DynamoDB, AWS Lambda, and Go. CRUD stands for create, read, update, delete (see Create, read, update, and delete on Wikipedia.). This terminology is common in applications that manage a large number of heterogeneous objects, in industries with complex business models, and high degrees of automation. This post uses an example from the hospitality industry, but the fundamental design principles apply to a wide variety of enterprise applications.
This post is targeted at software engineers looking for good practices and examples to design and build enterprise applications using DynamoDB and Go. For more information, see the GitHub repo. The code in the GitHub repo is written for quick prototyping not recommended for production use.
Prerequisites
To complete this walkthrough, you must have an AWS account with AWS CLI access and have installed the AWS CDK. For more information, see Getting Started With the AWS CDK. For more information about building the API Gateway endpoints and Lambda function, see the GitHub repo.
Use case and application design
Modern hotel central reservation systems enable hotel chains and independent properties to administrate their content (such as pictures, videos, room descriptions, rooms and rates, and distribution rules) to make their products searchable and bookable through a wide variety of distribution channels (such as online travel agencies, chain websites, and internal booking engines). These specialized applications expose hundreds of use cases to a large number of users, from the hotel front desk agent to the final guest, along with the chain corporate employees and more. These use cases commonly fit into the following families:
- Administrative use cases – These typically allow hoteliers or corporate office employees to create, update, and delete objects such as
CHAIN,BRAND,PROPERTY,ROOM,ROOM_TYPE, andPRICING_RULE, each consisting of a large set of interdependent attributes. - Operational use cases – These allow mobile and web applications to search and book hotel products defined as a combination of the previously mentioned attributes, computed prices, and business rules results.
Operational use cases have a limited set of flows and high traffic/low latency requirements, and some flows can withstand eventual consistency. Administrative use cases require consistent reads and a large number of small object CRUDs.
| Operational use cases | Administrative use cases | |
| Use cases |
SearchHotelAvailability SearchRoomAvailability, BookRoom |
listHotels, saveHotel, getHotel, deleteHotel, addPicture, deletePicture, saveRooms, addSellable, addRoomType, addTag, deleteSellable, deleteRoomType, deleteTag, addSellablePicture, addRoomTypePicture, deleteSellablePicture, deleteRoomTypePicture, publishChanges |
| Client | Hotel chain, web site, Mobile booking Application, third party online travel agency…. | Administration portal |
| Persona | Travel Agent, Hotelier, Guest | Hotelier, Hotel Chain Corporate Employee |
| Constraints |
High traffic Low latency Eventual consistency |
Medium to low traffic Strongly consistent Flexible datamodel |
Due to the large number of interdependent objects (easily mappable to classes with foreign keys), classic approaches to application design may identify administrative use cases as more suitable for relational database use. DynamoDB is also particularly useful in this set of use cases. It allows rapid data model evolution and provides independent object CRUD management, while exposing a natively efficient read use case. Additionally, despite object interdependencies, it avoids the use of joins and multiple parallel queries, which usually impede scalability and performance.
To illustrate these use cases, this post presents a serverless application composed of a RESTful API on Amazon API Gateway, with a set of endpoints integrated with a Lambda function written in Go that accesses a DynamoDB table. The following diagram illustrates this architecture.
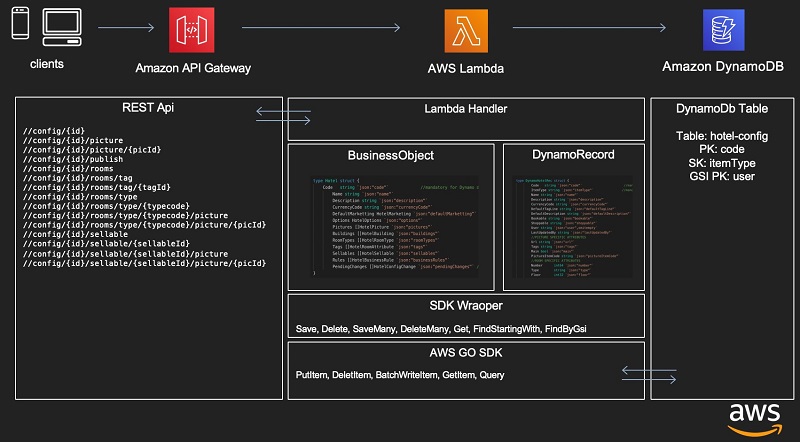
The API Gateway layer manages the RESTful API definition and access control. It also defines the Lambda function called for each Method/REST endpoint combination along with a transformation template that allows the use of one single Lambda function for all the individual object managements. While these may seem against the principles of microservice design, keeping the management of many small interdependent simple objects in one Lambda application (and storage in one DB table) carries excellent benefits in terms of application operability and maintainability.
The Lambda function translates the object model into a DynamoDB-optimized model. It is a good practice to decouple the two models because it helps better manage backward compatibility and provides an abstraction layer on top of the data store. This allows you to make changes more easily in the future. Another good practice is to build a wrapper on top of the DynamoDB SDK functions. This creates abstraction in case the data model changes and allows you to tailor function definitions to the use case, which greatly increases code readability and maintainability.
Data model design
A table in DynamoDB is composed of a partition key (PK) and an optional sort key (SK). The combination PK/SK constitutes the primary key of an item in the table. Also, the choice of partition key directly impacts the way items are distributed to the underlying database nodes, so you should choose a high cardinality set for PKs. There is a trade-off, however, because only SCAN operations can return items with different PKs. Because SCAN operations read the whole table, they are inefficient in comparison to QUERY operations, which only fetch the items for a given PK.
Each hotel is identified by a code and has a master configuration record with the following model.
The master configuration object has a set of simple nested objects (fewer than 10 fields) with interdependencies. Industry use cases can typically have hundreds (in some cases thousands) of nested objects. The following diagram illustrates a partial version of such a data model using the classic UML.
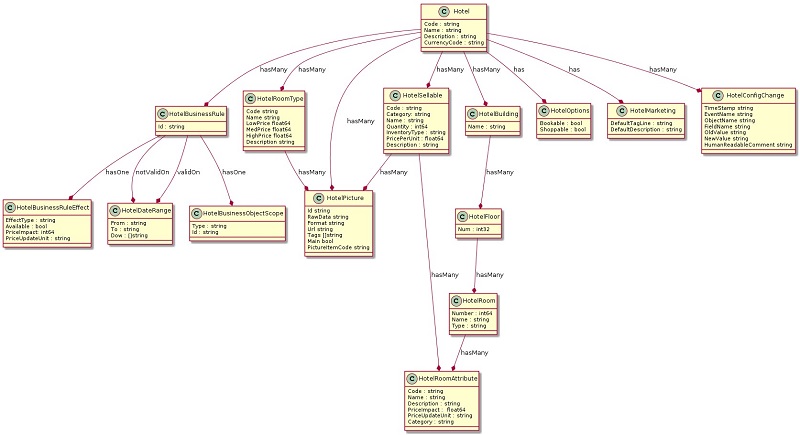
UML representation does not visually describe this post’s DynamoDB model very clearly. We prefer using a tabular representation, which describes the partition key, sort key, and dedicated attributes for each item. This representation is used later on in this post.
Some of the administrative use cases to address with this model are: listHotels, saveHotel, getHotel, deleteHotel, addPicture, deletePicture, saveRooms, addSellable, addRoomType, addTag, deleteSellable, deleteRoomType, deleteTag, addSellablePicture, addRoomTypePicture, deleteSellablePicture, deleteRoomTypePicture, and publishChanges. One or several data access patterns correspond to each.
To define a data model that corresponds to the preceding business model and efficiently performs with DynamoDB, you should review the constraints you must work with.
Write operations
To optimize for cost, performance, and application access patterns, split the objects into multiple items in the same table. When you need to read/write nested objects, you do not need the full object. To support these requirements, it makes sense to store the nested data in its own item. Because the nested objects defined previously are small (fewer than 10 fields), they are good candidates for the granularity of your items.
Read operations
The getHotel use case, which returns the whole hotel configuration, is likely to be the most frequent because this post doesn’t define more granular retrieve use cases (this design decision would benefit from further discussions, but this is beyond the scope of this post). You should therefore optimize it and avoid scan operations and multiple parallel queries. You can achieve this by using the hotel code as a partition key for all records and use the sort key as a way to identify the nested object the record corresponds to. Choosing the hotel code as the partition key works under the hypothesis that the administrative use case supports medium to low traffic. This is sensible because the traffic originates mostly from manual actions on an administration front-end.
There are some critical differences between the way operational and administrative use cases use DynamoDB features. High throughput traffic from operational use cases would use DynamoDB for scalability and elasticity. Administrative use cases take advantage of the flexibility of adding and updating nested objects, the cost-efficiency of small write operations, and the serverless nature of DynamoDB.
To design your DB model, use the following naming convention for your Sort Key:
The following table shows a few mapping examples.
| Business object | DynamoDB record sort key |
| Hotel | cfg-general |
| HotelSellable | cfg-sellable-<id> |
| HotelRoom | cfg-room-<id> |
| HotelRoomAttribute | cfg-tag-<id> |
| HotelRoomType | cfg-roomType-<id> |
| HotelPicture |
cfg-general-picture-<id> cfg-sellable-picture-<id> cfg-roomType-picture-<id> |
| HotelConfigChange | cfg-history-<id> |
As mentioned previously, use the following tabular representation to translate the DynamoDB model visually.
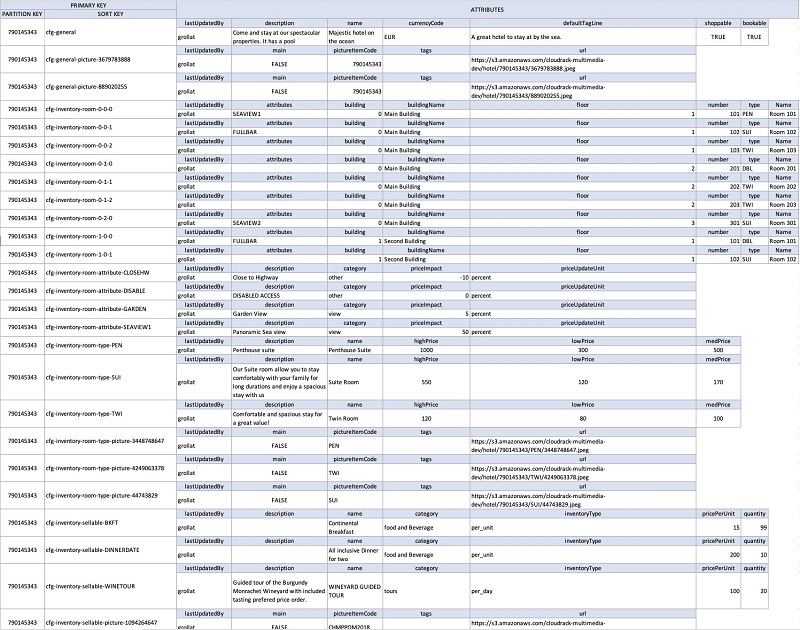
Lambda function architecture
The following diagram illustrates the architecture of the Lambda function.

Requests from API Gateway are passed to the handler, which picks the use case to run. Each use case interacts with the DynamoDB AWS SDK through an adapter layer to translate your business object model into the DynamoDB optimized model.
In a scenario with multiple Lambda functions, you can make the Lambda core folder a shared GO component published in a separate repository. This allows you to jump-start your next Lambda function and reuse the same model and wrapper functions.
Adapters use a set of wrapper functions built on top of the AWS SDK to simplify the code for the most frequent use cases. This post uses the following wrapper functions:
- Init – Create the connection struct
- Save – Upsert an item
- FindStartingWith – Find items for a given PK and an SK starting with a given string
The following functions are also available in the GitHub repo:
- SaveMany – Save multiple items (it handles up to 25 items from the SDK BatchWriteItems)
- DeleteMany – Delete multiple items
- Delete – Delete one item by its PK and SK
- Get – Get an item by its PK and SK
- FindByGsi – Find items by the global secondary index
Lambda function handler
The Lambda function handler routes the requests from the API Gateway endpoint to the appropriate use case using the subFunction parameter in the request body that you mapped in your infrastructure script. See the following code:
It is a best practice to initialize the DynamoDB client outside of the Lambda function handler to allow Lambda to reuse connections. For more information, see Best Practices. See the following code:
To implement it in the Lambda core package, see the following code:
This step creates a client object to interact with a DynamoDB table. This strategy allows a single function to easily interact with multiple tables by maintaining multiple client objects.
Get use case
You can now write the GetHotel use case with the following code:
It uses the FindStartingWith wrapper function written in the core DB package. See the following code:
This wrapper function allows you to search all DynamoDB items for a given partition key and with a sort key starting with a given string. This implementation has the following important points:
- You use the SDK Query function (which is more efficient than Scans)
- This works because when following the preceding sort key convention, all sort keys start with a common prefix
- You can efficiently query any subpart of your nested structure by reflecting the depth of an object in the model hierarchy in the order of the components of the sort key
The following is the DB adapter code:
The code iterates one time on all the records that DynamoDB returns and reconstructs the object piece by piece. You can reconstruct your entire object with one query as opposed to querying multiple tables or multiple times on one table and applying joints on the results. This does not come at the expense of less efficient write use cases because you can still write nested objects individually. This saves you write throughput costs and lowers the probability of concurrent access issues that you would encounter while storing one large configuration object.
Write use case
To directly write nested objects like RoomType, see the following code:
For the Save wrapper function, see the following code:
For the DB adapter function, see the following code:
Running the demo code
If you are not interested in getting the CDK script working or are not planning to update the stack, you can use the AWS CloudFormation template from the GitHub repo.
To build the infrastructure using CDK, complete the following steps:
- Clone the repository and run the
install.shscript.
This script installs all the required components (Node.js, CDK, Go, and packages). - Run the
deploy.shscript.
This builds the Lambda handler code and creates the .zip file using the GO compiler and the AWS-provided packager. Then it creates and deploys the stack using the CDK CLI. See the following code:If all is correct, you should receive the following output:
You can now use this endpoint to perform calls to your newly created REST API using the curl utility software.
- Create a hotel, add a room type, and retrieve the full object. See the following code:
You receive the following output:
- Use the returned ID to perform the second call. See the following code:
You should get a success 200 response.
- Perform a simple GET call. See the following code:
You can also paste the URL in a browser address bar.
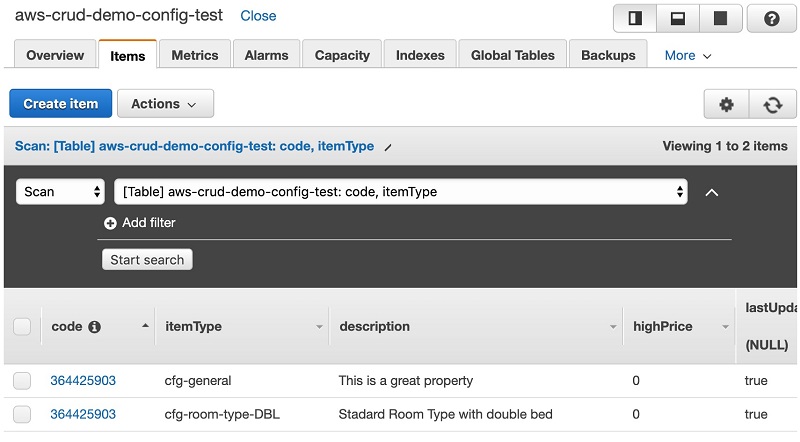
You receive the following code:You can check that two records have been added to your DynamoDB table by logging in to the AWS Management Console for DynamoDB. Click on the Tables link and select the table named
aws-crud-demo-config-$env(where $env is the name of the environment provided to the deploy.sh script.) The Items tab allows you to manage items and perform queries and scans. You should see two items with the sort key (SK) structure we discussed previously.
Summary
This post described an efficient way to build a serverless CRUD application on top of DynamoDB to enable administration use cases on large nested business object data models. The key takeaway is to use the same partition key for all nested objects and to use the sort key components order to reflect the nested object depths. This allows you to retrieve the full object in one query and allows efficient write use-cases for nested objects. This approach has the following benefits:
- It is aligned with DynamoDB pricing because read operations are cheaper than write operations.
- It lowers the probability of concurrent access issues because you write nested objects individually.
- It splits the object into smaller parts. This is an efficient handling of the 400 KB record side limit in DynamoDB.
- It allows you to retrieve the full object in one query, which takes advantage of DynamoDB single-digit millisecond response time. You can use a Query operation (and not a Scan) because you keep all nested objects under the same PK.
Takeaways
Some key takeways from building this demo:
- Use infrastructure as code – Use CloudFormation, CDK, or Amplify to script your architecture. Moving a large application infrastructure created manually through the AWS console to an infrastructure as code model is a tedious process.
- Sanitize your user inputs – Do this before using them as parameters to search for partition keys or sort keys. Otherwise, you could end up spending an hour debugging before finding logs with simple typographical errors. (beware the dreaded white space at the start of a PK or SK)
- Separate your storage model from your business model – This greatly increases code reusability.
- Build wrapper functions on top of AWS SDK – The DynamoDB SDK service team is constantly adding new features, so you can expect the SDK to become more complex over time. You do not necessarily need all its features at all times. Design simple wrapper functions of the most frequent use cases. This also allows you to reuse code for similar projects so you can jump-start a new project quicker.
- Beware of permissions settings – AWS provides a granular set of permissions capabilities through IAM. If something does not work out of the box, check first that your Amazon EC2 instance or Lambda function execution role has the appropriate permissions.
- Watch out for CORS settings. Don’t forget to enable CORS for the relevant endpoints in API Gateway. This is a frequent error during API design and often means extra back-and-forth exchanges between the front-end team and the back-end team.
Going further
To go further, you should explore how to use DynamoDB Streams to log the history of changes made on the business object. You can construct an audit log feature, which is a frequent requirement in large administration portals for compliance auditing.
Tracking the list of changes in the business object models also allows you to apply a draft-and-publish model to the changes in the configuration object, whereby a user can make multiple changes to the Hotel configuration object and decide to only publish them together at a chosen (or scheduled) time. You can effectively implement this by publishing the fully constructed object to Amazon S3. You can use the published object as the latest snapshot for operational use cases such as searchHotelAvailability or BookRoom.
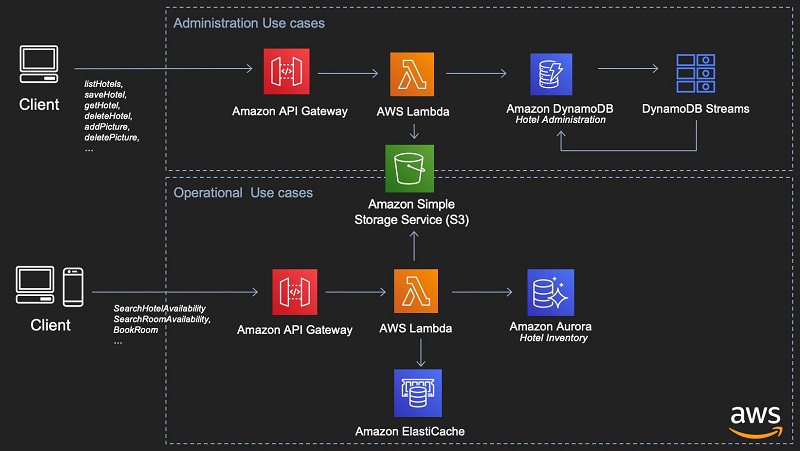
The following diagram illustrates the simplified architecture of a hotel central reservation system. The Administration Use Case architecture matches this post’s demo code. The Operational Use Cases are also exposed as REST endpoints using Amazon API Gateway and AWS Lambda but use Amazon Aurora because using a SQL database in this use case is likely to be more cost-efficient due to the amount of write operations required for inventory updates. Amazon Elasticache can also be used to improve the response time of the SearchHotelAvailability use case.
Finally, you can find advanced design pattern recommendations for DynamoDB (including tips on versioning your model) in an excellent presentation from AWS NoSQL Principal Technologist Rick Houlihan at 2018 AWS re:Invent. See the video of the presentation on YouTube.
When building your Enterprise application on top of DynamoDB, follow DynamoDB best practices for the best performance and lowest costs! If you have questions or feedback about DynamoDB best practices, ping us on @DynamoDB on Twitter.
About the Author

Geoffroy Rollat is a Solutions Architect with Amazon Web Services supporting enterprise customers. Prior to AWS, Geoffroy spent close to ten years in the hospitality technology sector delivering software solutions to Hotel Chains and Travel Companies.