Amazon Web Services ブログ
Amazon SageMaker での AutoGluon-Tabular の活用 AWS Marketplace 編
前回の記事では、Amazon SageMaker で独自コンテナを用いて AutoGluon-Tabular を活用し、数行で高精度な機械学習モデルが構築できることをご紹介致しました。今回は、AWS Marketplace に出品されている AutoGluon-Tabular のソフトウェアを活用し、コードを記述することなく、機械学習モデルを構築する方法をご案内します。
AWS Marketplace は、ソフトウェア、データ、およびサービスを簡単に検索、購入、デプロイ、管理するために使用できる厳選されたデジタルカタログであり、セキュリティ、ネットワーク、ストレージ、データベース、といった様々なカテゴリに属する何千というソフトウェアが出品されています。今回は新しく、AutoGluon-Tabular が出品されたので、こちらを使用して機械学習モデルを構築してみます。
Step1: CSVファイルを用意します
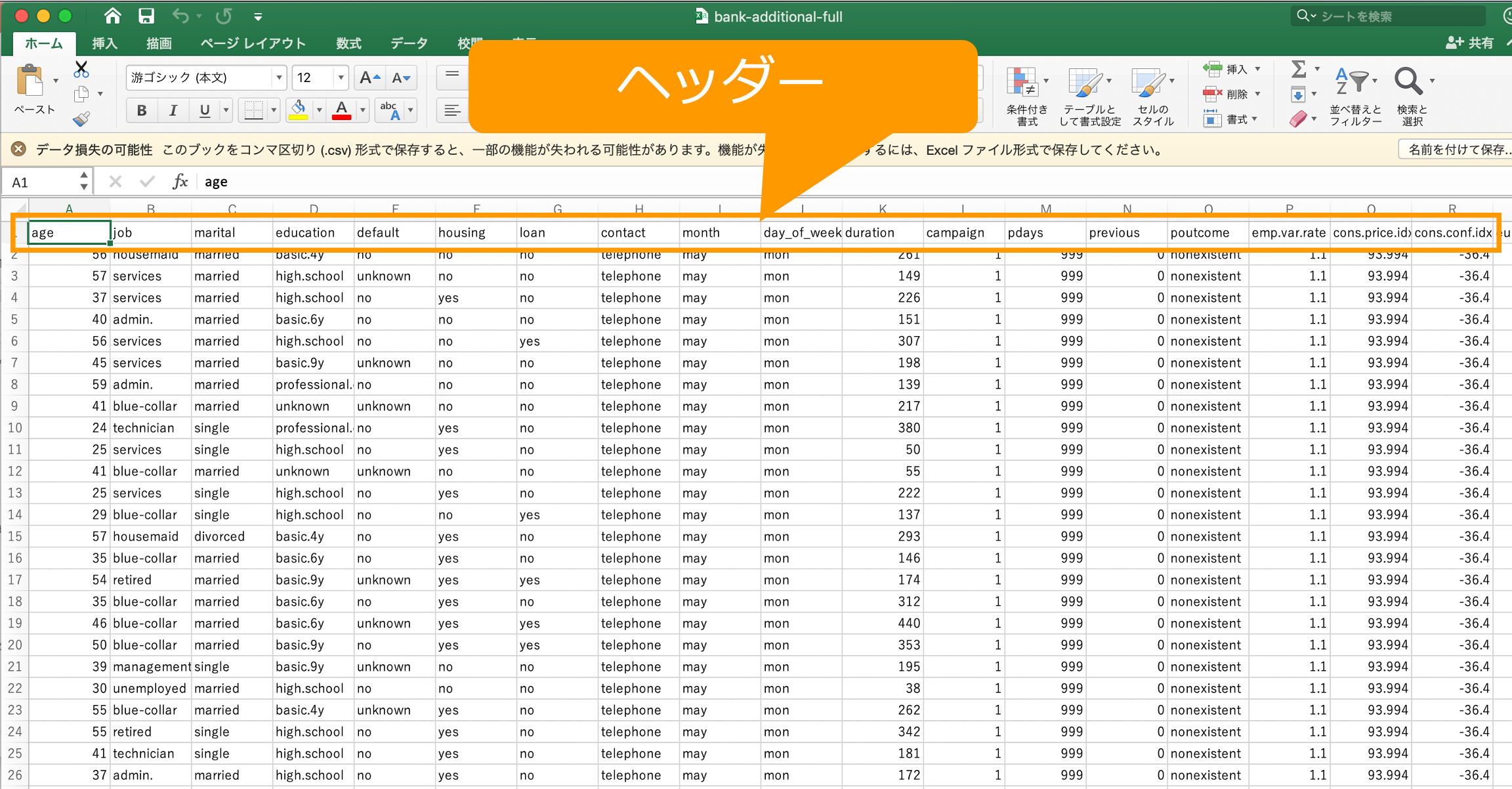
AutoGluon-Tabular ではテーブルデータを対象としています。学習データやテストデータは、pandas などの標準的なライブラリを使用して Python で読み込める有効な CSV ファイルとして格納されていれば良く、手動で前処理を行う必要はありません。各カラム名に該当するヘッダーは付けてください。後のステップで予測対象の目的変数のカラム名を指定します。
今回は、元のデータを7:3の比率で学習データとテストデータにランダムに分割し2つのファイルを作成しました。
Step2: CSVファイルをS3にアップロードします
Step1 の CSV ファイルを Amazon S3 にアップロードしましょう。

Step3: SageMakerのコンソールでトレーニングジョブを実行します
まず、SageMaker のコンソールの左ペインにある「アルゴリズム」(下記1)のセクションをクリックし、表示された右上の「アルゴリズムを探す」ボタン(下記2)をクリックしてください。

飛んだ先のマーケットプレイスのページの検索ボックスで autogluon を検索して、表示された「 AutoGluon-Tabular 」をクリックしてください。

飛んだ先のマーケットプレイスの AutoGluon-Tabular のページで「 Continue to Subscribe 」ボタンをクリックしてください。

料金やライセンスに関する説明が表示されますので、確認して「 Accept Offer 」ボタンをクリックしてください。AutoGluon-Tabular は OSS であり、アルゴリズムの使用自体には料金は発生しません。SageMaker の使用については SageMaker の課金体系に従って料金が発生します。

下記の緑色のようなメッセージが表示されたら、「 Continue to configuration 」のボタンをクリックしてみましょう。
※ AutoGluon-Tabular のサブスクリプションが完了していれば、SageMaker のコンソールからもトレーニングジョブは実行できます。具体的には、 SageMaker コンソール上の左ペイン「アルゴリズム」を選択後、「 AWS Marketplace のサブスクリプション」タブを選択し表示されるアルゴリズムから「 AutoGluon-Tabular 」をチェックし、「アクション」から「トレーニングジョブの作成」を選択することができます。
ここではこのまま進むことにしましょう。

下記のような設定画面が出てきますので、SageMaker で利用するリージョンを選択して、「 Create a training job 」が選択されていることを確認して「 View in Amazon SageMaker 」ボタンをクリックして下さい。ここでは Ohio リージョンを選択していますが、ご自身で利用したいリージョンを選択して下さい。

下記のようなトレーニングジョブの作成の設定画面が表示されます。ジョブ名を入力して、IAM ロールの逆三角形のマークをクリックして下さい。

今回使用する S3 のバケットにアクセスできるロールを指定するか作成して下さい。今回は新しく作成してみたいと思います。表示された選択肢の中から「新しいロールの作成」をクリックして下さい。

「 IAM ロールを作成する」という画面が表示されますので、「指定する S3 バケット」で「特定の S3 バケット」を選択して、今回使用するバケットを入力し右下の「ロールの作成」ボタンをクリックして下さい。

下記の緑色箇所のように、IAM ロール作成に成功したメッセージが表示されます。

続いて、リソース設定です。インスタンスタイプは、「 ml.m5.2xlarge 」、数は1が推奨です。「インスタンスあたりの追加のストレージボリューム ( GB )」の箇所に30以上の値を入力して下さい。

ハイパーパラメータの箇所で、キー「 label 」に対応する値に、アップロードした CSV ファイルにおける目的変数のカラム名を入力して下さい。今回は「 y 」なので「 y 」を入力しています。

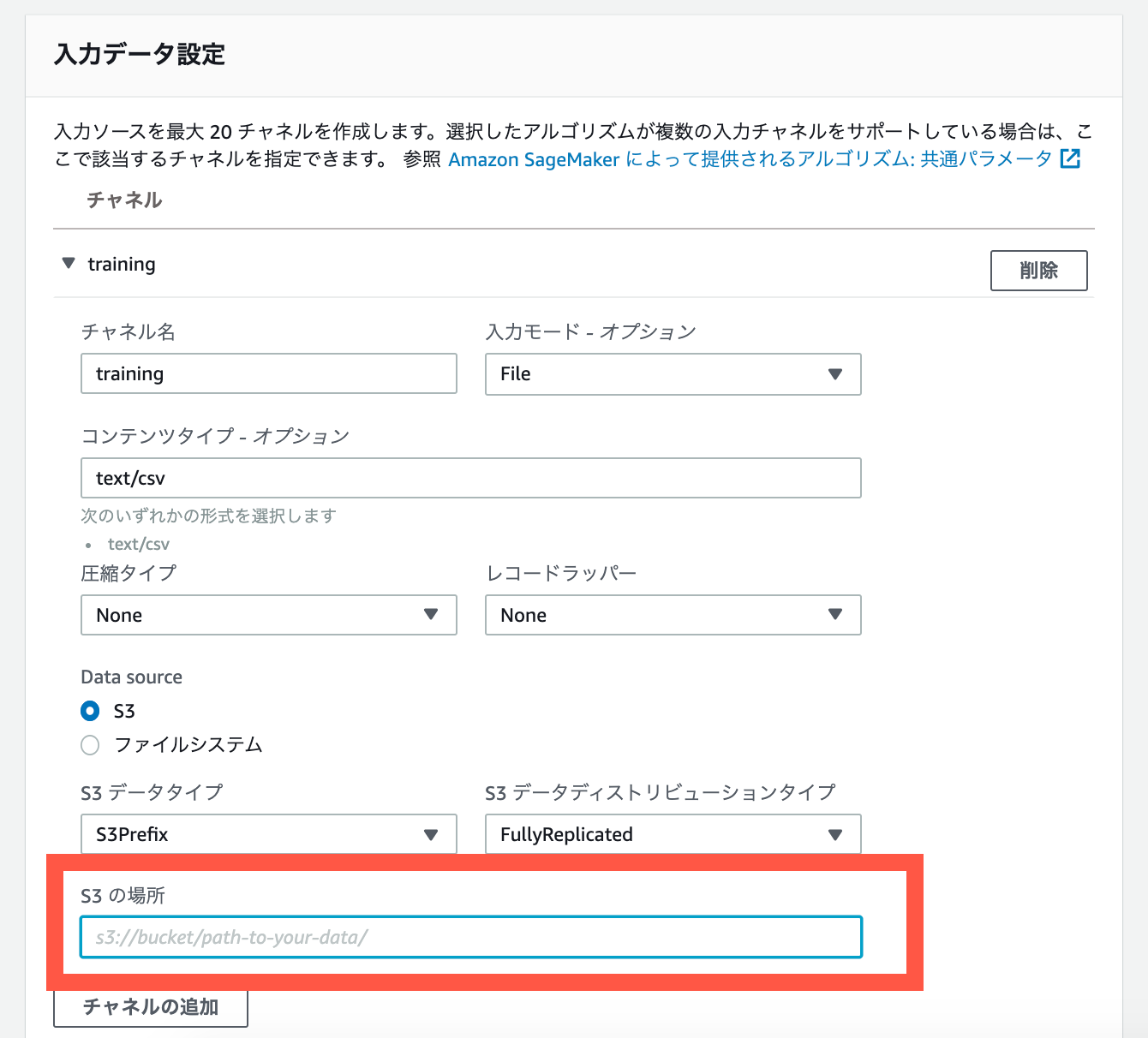
入力データ設定の「 S3 の場所」に、アップロードした入力データの S3 のパスを記入して下さい。コンテンツタイプが「 text/csv 」になっていることを確認して下さい。
※ S3 のパスは、下記のように S3 のコンソールで該当ファイルをチェックして表示される「コピーパス」をクリックするとコピーされます。

出力データ設定の「 S3 出力パス」に、出力されるモデルのアーティファクトを保存する S3 のパスを入力して下さい。

以上の設定が終わったら、画面右下の「トレーニングジョブの作成」ボタンをクリックして下さい。必要に応じて他の設定を追加することもできます。
下記のように SageMaker のトレーニングジョブのページに飛びます。今作成したトレーニングジョブのステータスが「 InProgress 」になっているかと思います。これが「 Completed 」に変わったらトレーニングジョブの完了です。トレーニングジョブが完了すると、上記で設定した S3 出力パスにモデルのアーティファクトが保存されます。今回は6分ほどかかったようです。

ステータスが Completed になったら、作成したトレーニングジョブをチェックして右上のアクションから、「モデルパッケージの作成」を選択してクリックして下さい。

モデルパッケージの作成画面で、モデルパッケージ名を入力し、推論仕様のオプションで「トレーニング用に使用したアルゴリズムとそのモデルアーティファクトを指定します」が選択されていることを確認して、「アルゴリズムとモデルアーティファクト」については変更せず、右下の「次へ」ボタンをクリックして下さい。

検証の仕様については、変更せず下記のようになっていることを確認して、右下の「モデルパッケージの作成」ボタンをクリックして下さい。

ステータスが「 InProgress 」になっている箇所が、「 Completed 」になったら完了です。
作成したモデルパッケージをチェックした状態で右上の「アクション」から「モデルの作成」を選択してクリックして下さい。

モデル名を入力して、今回使用する S3 のバケットにアクセスできるロールを指定してみましょう。トレーニングジョブの作成時に作成したロールを選択してみます。

コンテナの定義は今回は「モデルパッケージリソースを使用する」を選択し、その他の設定はそのままで、右下の「モデルの作成」ボタンをクリックしてみます。

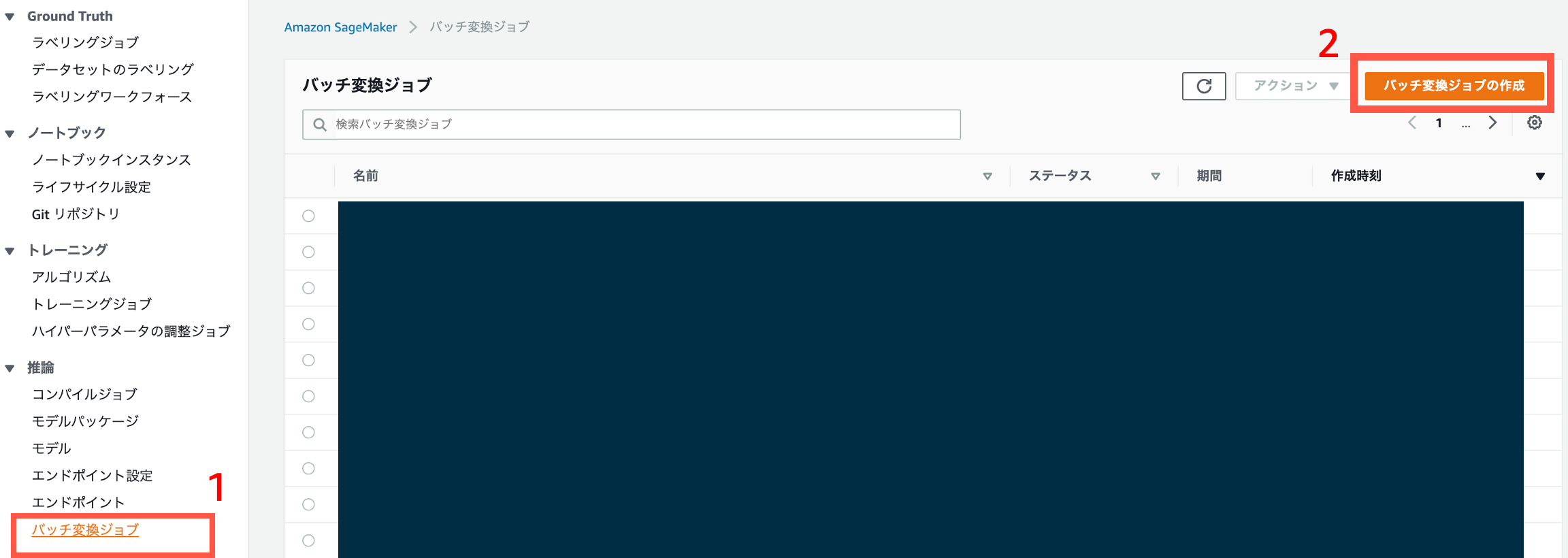
Step4: コンソールでバッチトランスフォームジョブを実行しテストデータに対する推論を行います
モデルの作成ができたら、コンソール左ペインの「バッチ変換ジョブ」をクリックして右上の「バッチ変換ジョブの作成」ボタンをクリックして下さい。
ジョブ名を記入し、モデル名については先ほど作成したモデル名を入力するか、検索モデルというボタンをクリックするとこれまで作成されたモデルが表示されるので、その中から先ほど作成したモデルを選択して下さい。今回のバッチ推論で使用したいインスタンスタイプとインスタンス数を指定して下さい。トレーニングジョブの時と同様に、インスタンスタイプは、「 ml.m5.2xlarge 」、数は1が推奨です。

追加設定の箇所で、「最大同時変換」に「 1 」を、「最大ペイロードサイズ ( MB )」に「 6 」を入力し、「バッチ戦略」で「 MultiRecord 」を選択して下さい。

入力データ設定の箇所で、「分割タイプ」に「 Line 」を選択し、「コンテンツタイプ」の箇所に「 text/csv 」を入力して下さい。「 S3 の場所」にはテストデータの CSV ファイルのパスを入力して、出力データ設定の「 S3 出力パス」に、出力されるファイルを保存する S3 のパスを指定して、右下の「ジョブの作成」ボタンをクリックして下さい。

バッチ変換ジョブが完了すると、指定していた S3 の場所に予測結果のファイルが保存されます。今回は3分ほどかかったようです。
以上のように、コーディングなしで AutoML 機能を利用することができました。
まとめ
これまで2回の投稿を通して、AutoGluon-Tabular を Amazon SageMaker でご活用頂く方法について、独自コンテナを活用する場合 ( BYOC ) と、AWS Marketplace に出品されているソフトウェアを活用する場合とをお伝え致しました。AutoGluon-Tabular による機械学習モデル構築の自動化で、より良いサービスが迅速に開発できる一助となれば幸いです。
著者について
 中山洋平は Amazon ML Solutions Lab の Deep Learning Architect です。様々な産業のお客様のビジネス課題を AI 、クラウド技術を用いて解決する支援をしています。また、人工衛星観測データへの機械学習の応用に関心を持っています。
中山洋平は Amazon ML Solutions Lab の Deep Learning Architect です。様々な産業のお客様のビジネス課題を AI 、クラウド技術を用いて解決する支援をしています。また、人工衛星観測データへの機械学習の応用に関心を持っています。
 藤川のぞみは AWS の機械学習ソリューションアーキテクトです。さまざまな業界のお客様の課題を機械学習を活用して解決するご支援をしています。
藤川のぞみは AWS の機械学習ソリューションアーキテクトです。さまざまな業界のお客様の課題を機械学習を活用して解決するご支援をしています。
 上総虎智は AWS の機械学習ソリューションアーキテクトです。お客様がクラウドで機械学習基盤構築する際のご支援をしています。
上総虎智は AWS の機械学習ソリューションアーキテクトです。お客様がクラウドで機械学習基盤構築する際のご支援をしています。