表データに対する分類、回帰というタスクは機械学習のタスクの中でもビジネスに最も親密に結びついています。もし、以前にこのようなタスクに取り組まれていたなら、表データに対する推論の利用用途が多岐にわたることをご存知でしょう。ビジネスにおいて、ユーザーの購買活動、保険請求金額、医療レポート、IoT からのセンサーデータなど多種多様なソースから収集したデータに基づいて、機械学習モデルを構築することが重要となります。しかしながら、そのような多様性のあるデータを扱うことは容易ではありません。
このような問題に対し、これまでは専門家による懇切丁寧な特徴量エンジニアリングを通したアプローチがとられていました。しかしながら、近年、機械学習コンペティションでは複数のモデルのアンサンブルによるアプローチが主流となりつつあります。コンセプトとなっているのは複数のモデルを組み合わせてさらに良いモデルを作ることです。これは集合知と呼ばれており、それぞれのモデルがより多様で独立しているときに効果を発揮します。
AutoGluon-Tabular ではこのアイデアを取り入れています。多層スタックアンサンブルという手法も用いることにより AutoGluon-Tabular は AutoML のフレームワークとして様々なタスクに対して優れた精度を記録しています。また、AutoGluon-Tabular はシンプル、堅牢、高効率、高精度、フォールトトレラントを考慮しデザインされており、複雑な処理なしに高精度のモデルが作成可能です。
この AutoGluon-Tabular は Amazon SageMaker の独自コンテナ および AWS Marketplace を活用頂くことで簡単にお使い頂けます。これにより、たった数行のコードで高精度な機械学習モデルを作成することが可能となります。また、フルマネージドサービスである Amazon SageMakerを 利用することで、ラベリングタスクとの統合、セキュアでスケーラブルなモデルの作成、スポットインスタンスを利用したコスト削減が可能となります。
この投稿では、Amazon SageMaker での独自コンテナを活用する、BYOC( Bring Your Own Container ) という方法で AutoGluon-Tabular の活用 し、高精度な学習モデルを作成、デプロイし、すぐさまお客様のビジネスに利用する方法をご紹介します。また、次回の記事では、AWS Marketplace にあるソフトウェアを用いることで、コードを記述することなく活用頂く方法についてもご案内しています。
Amazon SageMaker での独自コンテナを用いた AutoGluon-Tabular の活用
本セクションでは、Amazon SageMaker ノートブックインスタンスを用いて、AutoGluon-Tabular モデルを学習し、推論を行う方法について順を追ってご説明致します。サンプルコードの詳細については、GitHub のリポジトリを参照下さい。
ステップ1: SageMaker ノートブックインスタンスの作成
このチュートリアルの最初のステップは、SageMaker ノートブックインスタンスを作成することです。今回は、コストの低い ml.t2.medium インスタンスを選びます。作成の際には、AmazonSageMakerFullAccess ポリシーを含む IAM ロールを作成するか、選択して下さい。ノートブックインスタンスの作成が完了したら、「JupyterLabを開く」を選択します。Jupyter Lab が立ち上がりましたら、サイドバーの SageMaker アイコンにあります SageMaker Example ノートブックタブ中の、「Advanced Functionality」にある、AutoGluon_Tabular_SageMaker.ipynb を開き、「Create a Copy」ボタンを押して下さい。
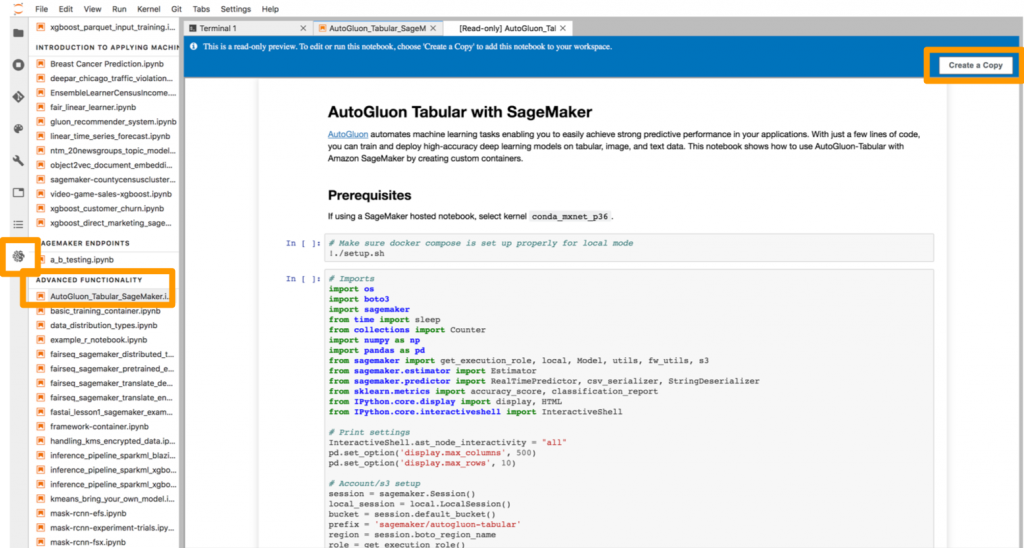
ステップ2: 準備
今回のチュートリアルでは、「conda_mxnet_p36」という conda カーネルが事前に選択されてるかと思います。もし違う場合には、そちらをご選択下さい。下記を実行いただきますと、環境設定を行うなうことができます。
# Make sure docker compose is set up properly for local mode
!./setup.sh
# Imports
import os
import boto3
import sagemaker
from time import sleep
from collections import Counter
import numpy as np
import pandas as pd
from sagemaker import get_execution_role, local, Model, utils, fw_utils, s3
from sagemaker.estimator import Estimator
from sagemaker.predictor import RealTimePredictor, csv_serializer, StringDeserializer
from sklearn.metrics import accuracy_score, classification_report
from IPython.core.display import display, HTML
from IPython.core.interactiveshell import InteractiveShell
# Print settings
InteractiveShell.ast_node_interactivity = "all"
pd.set_option('display.max_columns', 500)
pd.set_option('display.max_rows', 10)
# Account/s3 setup
session = sagemaker.Session()
local_session = local.LocalSession()
bucket = session.default_bucket()
prefix = 'sagemaker/autogluon-tabular'
region = session.boto_region_name
role = get_execution_role()
client = session.boto_session.client(
"sts", region_name=region, endpoint_url=utils.sts_regional_endpoint(region)
)
account = client.get_caller_identity()['Account']
ecr_uri_prefix = utils.get_ecr_image_uri_prefix(account, region)
registry_id = fw_utils._registry_id(region, 'mxnet', 'py3', account, '1.6.0')
registry_uri = utils.get_ecr_image_uri_prefix(registry_id, region)</code></pre></div><p> </p><h2> </h2>
ステップ3: Docker イメージのビルド
このサンプルでは、AutoGluon-Tabular で学習と推論を行うためのコンテナを作成して活用する Bring Your Own Container (BYOC) というアプローチを用います。このステップでは、学習用と推論用のそれぞれのコンテナイメージをビルドし、Amazon Elastic Container Repository (ECR) へアップロードします。
始めに、autogluon パッケージを Docker イメージへコピーできるようにビルドします。
if not os.path.exists('package'):
!pip install PrettyTable -t package
!pip install --upgrade boto3 -t package
!pip install bokeh -t package
!pip install --upgrade matplotlib -t package
!pip install autogluon -t package
学習用と推論用のコンテナイメージを、Amazon Elastic Container Repository (ECR) へアップロードします。
training_algorithm_name = 'autogluon-sagemaker-training'
inference_algorithm_name = 'autogluon-sagemaker-inference'
!./container-training/build_push_training.sh {account} {region} {training_algorithm_name} {ecr_uri_prefix} {registry_id} {registry_uri}
!./container-inference/build_push_inference.sh {account} {region} {inference_algorithm_name} {ecr_uri_prefix} {registry_id} {registry_uri}
Docker イメージの詳細にご興味ある方は Github リポジトリ内にある Dockerfile をご確認下さい。
ステップ4: データの取得
このサンプルでは、ダイレクトマーケティングの提案を受け入れるかどうかを二値分類で予測するモデルを開発します。そのためのデータをダウンロードし、学習用データとテスト用データへ分割します。AutoGluon では K -交差検証を自動で行うため、事前に検証データを分割する必要はありません。
まずは、データをダウンロードし学習用とテスト用へデータを分割します。
# Download and unzip the data
!aws s3 cp --region {region} s3://sagemaker-sample-data-{region}/autopilot/direct_marketing/bank-additional.zip .
!unzip -qq -o bank-additional.zip
!rm bank-additional.zip
local_data_path = './bank-additional/bank-additional-full.csv'
data = pd.read_csv(local_data_path)
# Split train/test data
train = data.sample(frac=0.7, random_state=42)
test = data.drop(train.index)
# Split test X/y
label = 'y'
y_test = test[label]
X_test = test.drop(columns=[label])
Amazon S3 へアップロードします。
train_file = 'train.csv'
train.to_csv(train_file,index=False)
train_s3_path = session.upload_data(train_file, key_prefix='{}/data'.format(prefix))
test_file = 'test.csv'
test.to_csv(test_file,index=False)
test_s3_path = session.upload_data(test_file, key_prefix='{}/data'.format(prefix))
X_test_file = 'X_test.csv'
X_test.to_csv(X_test_file,index=False)
X_test_s3_path = session.upload_data(X_test_file, key_prefix='{}/data'.format(prefix))
ステップ 5: ハイパーパラメータの設定
AutoGluon は初心者の方でも馴染みやすい操作性と、専門家向けの高いカスタマイズ性を両立しています。推論対象となるカラム名のみ、必須で指定が必要です。今回の場合はとても単純に “y” という名前のカラムをラベルとして指定しています。
# Define required label and optional additional parameters
fit_args = {
'label': 'y',
# Adding 'best_quality' to presets list will result in better performance (but longer runtime)
'presets': ['optimize_for_deployment'],
}
# Pass fit_args to SageMaker estimator hyperparameters
hyperparameters = {
'fit_args': fit_args,
'feature_importance': True
}
ステップ 6: 学習
データが S3 にアップロードされ、学習のための設定が選択されましたので、次は学習のためのインスタンスタイプの選択です。メモリ消費量の多くなる傾向にある機械学習モデルの学習は M5 タイプの選択が良いです。データチャネルを設定し、学習を開始します。デフォルトでの設定であれば、学習はおよそ10分以下で完了するはずです。一度学習が完了したら、評価用データでの精度が表示されるリーダーボードと特徴量重要度スコアを確認しましょう。
%%time
instance_type = 'ml.m5.2xlarge'
#instance_type = 'local'
ecr_image = f'{ecr_uri_prefix}/{training_algorithm_name}:latest'
estimator = Estimator(image_name=ecr_image,
role=role,
train_instance_count=1,
train_instance_type=instance_type,
hyperparameters=hyperparameters,
train_volume_size=100)
# Set inputs. Test data is optional, but requires a label column.
inputs = {'training': train_s3_path, 'testing': test_s3_path}
estimator.fit(inputs)
ステップ 7: モデルの作成
学習ジョブからデータの入出力の形式を CSV 及び文字列とした推論用モデルを作成します。
# Create predictor object
class AutoGluonTabularPredictor(RealTimePredictor):
def __init__(self, *args, **kwargs):
super().__init__(*args, content_type='text/csv',
serializer=csv_serializer,
deserializer=StringDeserializer(), **kwargs)
ecr_image = f'{ecr_uri_prefix}/{inference_algorithm_name}:latest'
if instance_type == 'local':
model = estimator.create_model(image=ecr_image, role=role)
else:
model_uri = os.path.join(estimator.output_path, estimator._current_job_name, "output", "model.tar.gz")
model = Model(model_uri, ecr_image, role=role, sagemaker_session=session, predictor_cls=AutoGluonTabularPredictor)
ステップ 8: SageMaker でのバッチ推論
推論用のモデルが作成されましたら、推論結果を得る方法は2つあります。
1つ目は、断続的に推論を行う際に理想的なバッチ変換です。バッチ変換を行う際には、エンドポイントが作成され、テスト用データに対して推論を実行し、その結果が S3 へ保存されます。その後、エンドポイントは削除されますので、必要以上のコストはかかりません。
output_path = f's3://{bucket}/{prefix}/output/'
# output_path = f'file://{os.getcwd()}'
transformer = model.transformer(instance_count=1,
instance_type=instance_type,
strategy='MultiRecord',
max_payload=6,
max_concurrent_transforms=1,
output_path=output_path)
transformer.transform(test_s3_path, content_type='text/csv', split_type='Line')
transformer.wait()
ステップ 9: SageMaker エンドポイントでの推論
リアルタイム推論が必要な場合には、常に起動して、新規のデータに対して推論を行う SageMaker エンドポイントを作成することができます。このステップでは、新しいエンドポイントを作成します。エンドポイント作成が完了しましたら、データを送付して推論結果を得ることができます。
instance_type = 'ml.m5.2xlarge'
#instance_type = 'local'
predictor = model.deploy(initial_instance_count=1,
instance_type=instance_type)
# Select standard or local session based on instance_type
if instance_type == 'local':
sess = local_session
else:
sess = session
# Attach to endpoint
predictor = AutoGluonTabularPredictor(predictor.endpoint, sagemaker_session=sess)
results = predictor.predict(test.to_csv(index=False)).splitlines()
# Check output
print(Counter(results))
では、得られた推論結果の正解率を見てみましょう。
y_results = np.array(results)
print("accuracy: {}".format(accuracy_score(y_true=y_test, y_pred=y_results)))
print(classification_report(y_true=y_test, y_pred=y_results, digits=6))
特徴量エンジニアリングやハイパーパラメーターの調整を行わずに、数分の学習でこの分類タスクについて高い推論精度のモデルを得ることができました。「best_quality」 の設定を用いることで、さらに良い精度を得ることができるかも知れません。
ステップ 10: 使ったリソースの削除
チュートリアルが完了しましたら、必要以上のコストがかからないように、作成したエンドポイントを削除しましょう。
predictor.delete_endpoint()
まとめ
今回の投稿では、Amazon SageMaker で独自コンテナを用いて AutoGluon-Tabular を活用し、数行で高精度な機械学習モデルが構築できることをご紹介致しました。次回は、AWS Marketplace にありますAutoGluon-Tabular のソフトウェアを活用し、コードを記述することなく、機械学習モデルを構築する方法をご案内します。
著者について
 中山洋平は Amazon ML Solutions Lab の Deep Learning Architect です。様々な産業のお客様のビジネス課題を AI 、クラウド技術を用いて解決する支援をしています。また、人工衛星観測データへの機械学習の応用に関心を持っています。
中山洋平は Amazon ML Solutions Lab の Deep Learning Architect です。様々な産業のお客様のビジネス課題を AI 、クラウド技術を用いて解決する支援をしています。また、人工衛星観測データへの機械学習の応用に関心を持っています。
 藤川のぞみは AWS の機械学習ソリューションアーキテクトです。さまざまな業界のお客様の課題を機械学習を活用して解決するご支援をしています。
藤川のぞみは AWS の機械学習ソリューションアーキテクトです。さまざまな業界のお客様の課題を機械学習を活用して解決するご支援をしています。
 上総虎智は AWS の機械学習ソリューションアーキテクトです。お客様が AWS を用いて機械学習基盤構築する際のご支援をしています。
上総虎智は AWS の機械学習ソリューションアーキテクトです。お客様が AWS を用いて機械学習基盤構築する際のご支援をしています。

 中山洋平は Amazon ML Solutions Lab の Deep Learning Architect です。様々な産業のお客様のビジネス課題を AI 、クラウド技術を用いて解決する支援をしています。また、人工衛星観測データへの機械学習の応用に関心を持っています。
中山洋平は Amazon ML Solutions Lab の Deep Learning Architect です。様々な産業のお客様のビジネス課題を AI 、クラウド技術を用いて解決する支援をしています。また、人工衛星観測データへの機械学習の応用に関心を持っています。 藤川のぞみは AWS の機械学習ソリューションアーキテクトです。さまざまな業界のお客様の課題を機械学習を活用して解決するご支援をしています。
藤川のぞみは AWS の機械学習ソリューションアーキテクトです。さまざまな業界のお客様の課題を機械学習を活用して解決するご支援をしています。