Amazon Web Services ブログ
Amazon DataZone によるデータガバナンスのスケール: Covestro の事例
本記事は 2025 年 11 月 3 日 に公開された「Scaling data governance with Amazon DataZone: Covestro success story」を翻訳したものです。
ドイツのレバークーゼンに本社を置く Covestro Deutschland AG は、高性能ポリマー素材とコンポーネントの世界的リーダーです。Covestro は、世界 48 か所の生産拠点、2024 年の売上高 142 億ユーロ、17,500 人の従業員を擁し、化学業界の主要プレイヤーとしての地位を確立しています。Covestro の事業の軸は、日常生活のさまざまな場面で使われる製品向けに、持続可能な新しいソリューションを開発することです。同社は、モビリティ、建築・住宅、電気・電子機器分野に加え、スポーツ・レジャー、ヘルスケア、化学業界向けの素材を提供しています。ポリカーボネート、ポリウレタン、コーティング、接着剤、特殊エラストマーといった同社の製品は、自動車、建築、電子機器、医療機器業界で重要なコンポーネントとして使われています。
グローバル事業と多様な製品ポートフォリオを支えるため、Covestro は堅牢なデータ管理ソリューションを採用しました。本記事では、Covestro が Amazon DataZone と AWS Serverless Data Lake Framework (SDLF) を導入してデータアーキテクチャを変革し、中央集権型のデータレイクからデータメッシュアーキテクチャへ移行した経緯を紹介します。この戦略的な転換により、各チームは統合されたデータマーケットプレイスとビジネスメタデータ用語集を通じて、高い品質基準を保ちながらデータを共有・利用できるようになりました。データアクセスの効率化、データ品質の向上、大規模かつ強固なガバナンスを実現し、さまざまなプロデューサーおよびコンシューマーチームが大規模なデータ / 分析ワークロードを実行できるようになり、1,000 を超えるデータパイプラインを運用し、市場投入までの時間を 70% 短縮しました。
ビジネスとデータの課題
変革以前、Covestro は単一のデータプラットフォームチームがデータエンジニアリング業務を担う、中央集権型のデータレイクで運用していました。中央集権型アプローチでは、いくつかの課題が生じていました。エンジニアリングリソースの制約によるプロジェクト納期のボトルネック、ユースケース優先順位付けの複雑化、非効率なデータ共有プロセスなどです。データの不要な重複が発生しがちで、新しい分析施策の市場投入までの時間が延び、コストが増え、業務部門がインサイトを素早く活用する力が制限されていました。データ資産が見えにくいことから、運用上の課題も大きくなっていました。
- 既存のデータセットを見つけられず、他の場所に既に存在するデータを再作成してしまうことが多かった
- データリネージや品質指標が明確でなかった
- 特定のデータ資産の所有者や、アクセスを依頼する窓口が特定しづらかった
- 利用可能なデータセットのメタデータやドキュメントがなかった
- 各部門がどのようにデータを使っているかについて、ほとんど情報共有されていなかった
可視性の問題は、統合されたアクセス制御の欠如と相まって、以下の事態を招いていました。
- 部門をまたいだデータ施策のサイロ化
- データ品質への信頼低下
- リソース利用の非効率化
- プロジェクト完了時期の遅延
- 部門横断的な協働やインサイト活用の機会損失
戦略的ソリューション: なぜ Amazon DataZone と SDLF なのか
Covestro が直面した課題は、中央集権型データアーキテクチャの根本的な構造上の制約を映し出しています。規模の拡大に伴い、中央のデータチームがボトルネックになりがちで、ドメインの文脈が欠けることで品質にばらつきが生じ、標準が統一されず、協働がうまくいきませんでした。制御を中央に集める代わりに、データメッシュはデータを生成し理解しているチームに所有権を委ね、組織全体でガバナンスと相互運用性を一貫させます。俊敏性、スケーラビリティ、チーム横断の協働を必要とする Covestro の環境に適したアプローチでした。
AWS Serverless Data Lake Framework (SDLF) は、データメッシュアーキテクチャの堅牢な基盤となるソリューションです。従来のデータレイク実装ではデータの所有権とガバナンスが中央集権化されがちですが、SDLF の柔軟な設計により、現代的なデータメッシュ原則に沿った分散型のデータドメインを構築できます。ドメイン指向のチームがデータプロダクトを独立して所有・管理するために必要なインフラ、セキュリティ制御、運用パターンを提供しながら、組織全体で一貫したガバナンスを保ちます。モジュール式のアーキテクチャと IaC (Infrastructure as Code) テンプレートにより、ドメイン固有のデータプロダクト作成を加速させ、Covestro のチームは標準化されつつもカスタマイズ可能なデータパイプラインをデプロイできます。ドメイン指向の分散化、プロダクトとしてのデータ、セルフサービスインフラ、連邦型ガバナンスというデータメッシュの主要な柱を支え、従来の中央集権型アーキテクチャの制約を乗り越える実践的な道筋を提供します。
Amazon DataZone は、分散化されたドメイン全体でデータを発見しアクセスできる統一的な体験を通じて、データメッシュの実装を強化します。データ管理サービスとして、組織の境界を越えてデータのカタログ化、発見、共有、ガバナンスを支援します。中央ガバナンスレイヤーにより、データ共有契約の確立、アクセス制御の管理、セルフサービスのデータアクセスを実現でき、セキュリティとコンプライアンスにも対応できます。各チームは SDLF フレームワークでドメイン固有のデータプロダクトを構築・運用でき、Amazon DataZone はメタデータ、ビジネスコンテキスト、利用ポリシーで充実した検索可能なカタログで補完します。データプロダクトの発見・信頼・再利用が容易になります。
Amazon DataZone の共有機能により、ドメインチームはきめ細かなアクセス制御とガバナンスポリシーを保ちながら、他のドメインにデータプロダクトを共有できます。ドメインをまたいだ協働とデータの再利用が可能になります。ドメインチームは SDLF 管理下のデータセットを Amazon DataZone カタログに公開でき、組織全体の認可された利用者がそれを発見・アクセスできます。Amazon DataZone に組み込まれたガバナンス機能により、標準化されたデータ共有ワークフローの実装、データ品質のチェック、分散データシステム全体での一貫したアクセス制御の適用が可能です。堅牢なデータガバナンスと民主化機能でデータメッシュアーキテクチャを強化できます。SDLF と Amazon DataZone の組み合わせにより、Covestro は自律的なデータドメインが一貫したガバナンス、シームレスなデータ共有、企業全体のデータ発見のもとで運用できる、現代的なデータメッシュアーキテクチャを実現しました。
ソリューションアーキテクチャと実装
以下のアーキテクチャ図は、データメッシュソリューションの全体設計を示しています。AWS サービス上に構築し、Covestro 組織内の複数の業務ドメインに対応する堅牢でスケーラブルかつガバナンスの効いたデータメッシュを実現しました。
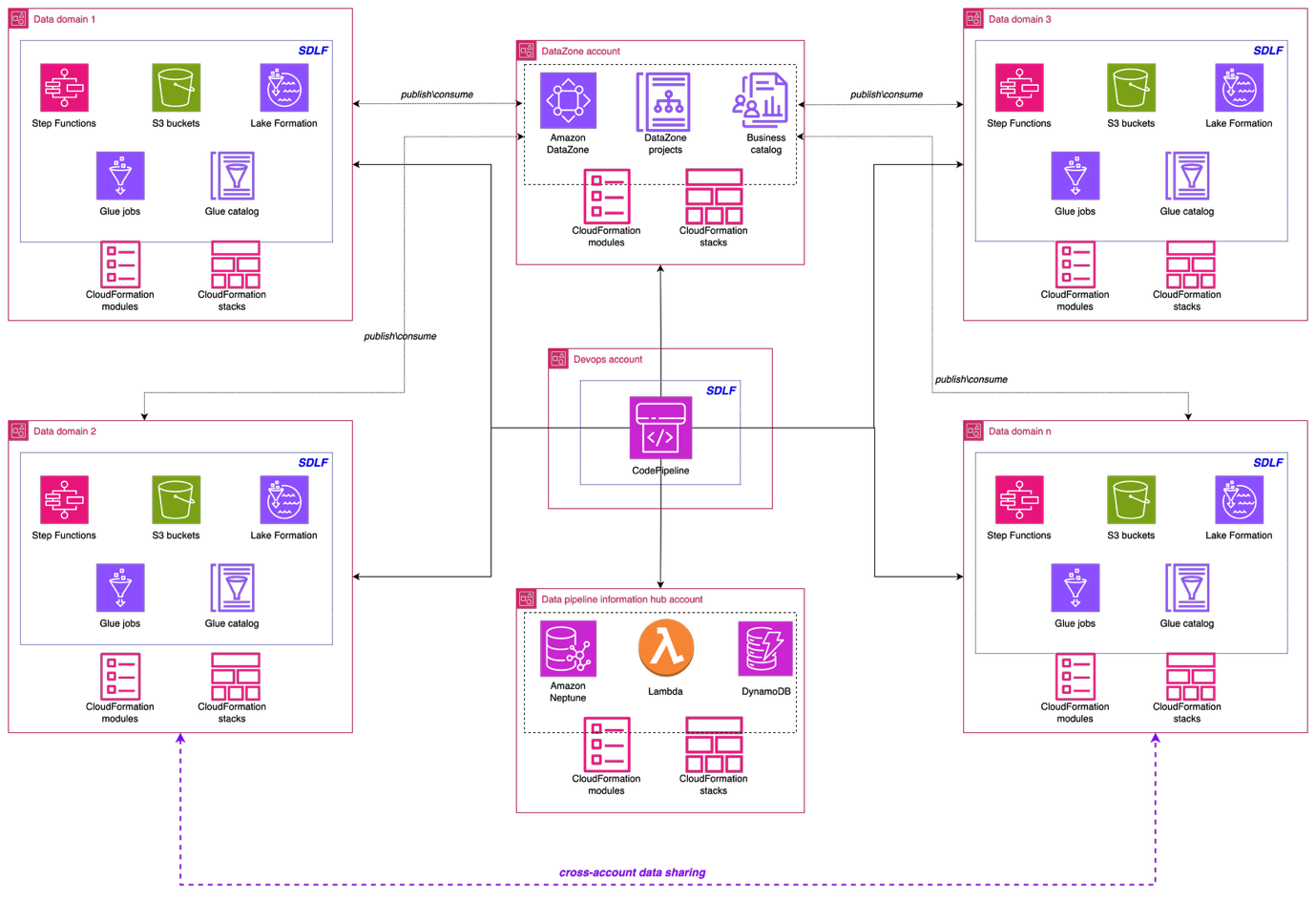
データドメインの基盤: Serverless Data Lake Framework
実装の重要な柱の 1 つが Serverless Data Lake Framework (SDLF) で、データメッシュ戦略を支える基盤インフラとセキュリティを提供します。SDLF は、Amazon S3 ストレージレイヤー、AWS KMS による組み込み暗号化、IAM ベースのアクセス制御、IaC による自動化など、データドメインのコアとなる構成要素を備えています。Covestro は企業全体で一貫したガバナンスを保ちつつ、分散化されたドメイン所有のデータプロダクトを迅速にデプロイできます。
主要なデータストレージレイヤーとして Amazon Simple Storage Service (Amazon S3) を使用し、多様なデータ資産に対して事実上無制限のスケーラビリティと 11 ナインの耐久性を提供します。S3 バケットアーキテクチャは AWS Well-Architected 原則に従い、raw、staging、analytics という明確に分けられたデータゾーンを持つ多層構造です。階層化アプローチにより、各業務ドメインはデータ主権 (各ドメインが自分のデータを所有・制御しつつ、組織全体のアクセスパターンを維持) を保てます。
セキュリティは Covestro のデータメッシュ実装の根幹です。SDLF は、データストレージと処理コンポーネント全体で保存時および転送時の暗号化を自動的に適用します。AWS Key Management Service (AWS KMS) が鍵の中央管理を担い、丁寧に設計された AWS Identity and Access Management (IAM) ロールがリソースの分離を実現します。
AWS Glue によるデータ処理
AWS Glue は、データ処理と変換の中心となるサーバーレス ETL (抽出・変換・ロード) サービスで、ワークロードの需要に応じて自動的にスケールします。
Covestro が以前から運用していた中央集権型データレイクには、さまざまなソースシステムと連携する 1,000 を超える取り込みデータパイプラインからデータが送られていました。既存パイプラインのマイグレーションを支えるため、Covestro はデータメッシュ向けに定義された開発標準とセキュリティ標準を含む再利用可能なブループリントを開発しました。ドメイン固有の要件に対応する柔軟性を保ちつつ、複数ドメインで展開できる標準化されたパターンをリリースしました。ブループリントは、Oracle、SQL Server、MySQL などの従来型データベースから、SAP C4C のような最新の SaaS アプリケーションまで、多様なソースシステムに対応します。
また、取り込んだ生データを処理、標準化、クレンジングするための専用ブループリントも開発しました。処理済みデータを Apache Iceberg 形式で保存し、メタデータを AWS Glue Data Catalog に自動保存し、スキーマ進化をシームレスに扱う組み込み機能を備えています。
Covestro は SDLF を使って、ブループリントを AWS Glue ジョブとしてドメイン内に素早く設定・デプロイします。チームは YAML 設定ファイルでデータパイプラインをデプロイでき、SDLF のオーケストレーションと管理の仕組みが残りを処理します。Amazon DynamoDB に基づく監視機能も含まれており、データパイプラインの健全性とパフォーマンス指標をリアルタイムで把握できます (チームが SDLF 経由でパイプラインをデプロイすると、システムが自動的に監視セットアップと統合します)。
AWS Glue Data Quality によるデータ品質
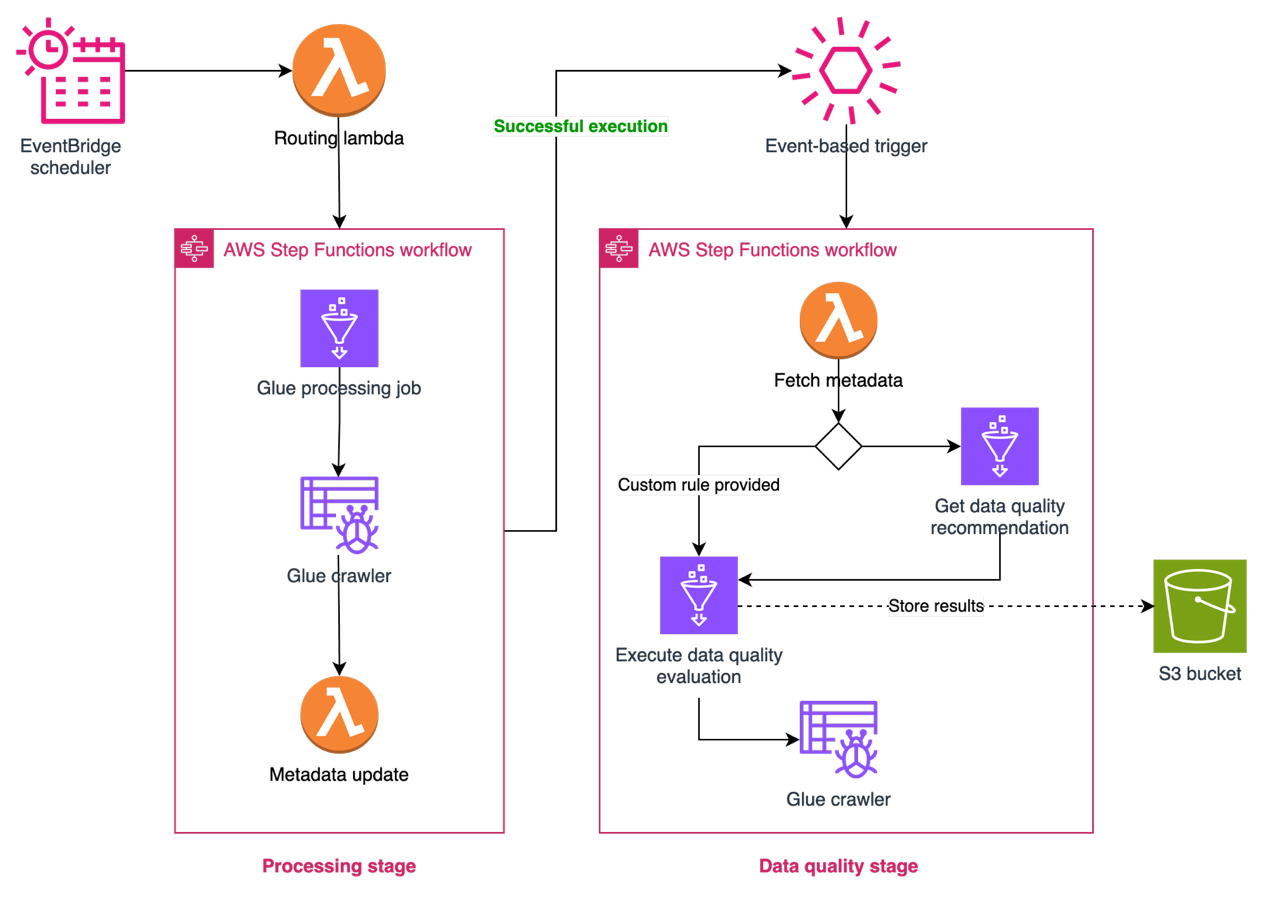
ドメインを越えたデータの信頼性を実現するため、Covestro は AWS Glue Data Quality をデータ処理パイプラインに組み込み、SDLF の機能を拡張しました。標準的なデータ処理ワークフローの一部としてデータ品質の自動チェックが可能になります。SDLF の設定駆動型の設計により、データプロデューサーはデータプロファイリングから自動生成される推奨ルールで品質管理を実装するか、ドメイン固有の独自ルールを適用できます。
データチームは品質基準を定義する柔軟性を持ちながら、パイプラインレベルでの品質チェック実装方法を統一できます。品質評価結果をログとして記録し、各データプロダクトのデータ品質指標を可視化します。以下の図は、品質チェックの統合を示しています。
AWS Lake Formation によるエンタープライズ対応のアクセス制御
Data Catalog と統合された AWS Lake Formation は、データメッシュ実装をエンタープライズレベルに引き上げるセキュリティとアクセス制御レイヤーです。Lake Formation により、Covestro はドメイン境界を尊重しつつ制御されたドメイン間のデータ共有を可能にする、きめ細かなアクセス制御を実装しました。
IAM との統合により、Covestro は組織構造に沿ったロールベースのアクセスパターンを実装できます。ユーザーは必要なデータにアクセスしつつ、適切なセキュリティ境界が維持されます。
Amazon DataZone によるデータの民主化
Amazon DataZone はデータメッシュ実装の中心です。専用の AWS アカウントにデプロイされ、以前の中央集権型アプローチに欠けていたデータガバナンス、発見、共有機能を提供します。ビジネスコンテキストで充実した検索可能な統合カタログ、自動化されたアクセス制御、標準化された共有ワークフローにより、組織全体で真のデータ民主化を実現します。
Amazon DataZone を通じて、Covestro はデータカタログを構築し、さまざまなドメインの業務ユーザーが深い技術的専門知識を必要とせずにデータ資産を発見、理解、アクセス申請できるようにしました。ビジネス用語集機能は、ドメインをまたいで一貫したデータ定義を支え、チームごとに同じ概念に違う用語を使うことから生じる混乱をなくします。
データプロダクトの所有者は、Amazon DataZone と AWS Lake Formation の統合でドメイン間のデータアクセスを付与・取り消しできます。セキュリティとコンプライアンス要件に対応しながらデータ共有プロセスを効率化できます。
ドメイン間データパイプラインの依存関係管理
Covestro のデータメッシュアーキテクチャを AWS 上に実装するにあたり、最大の課題の 1 つが複数ドメインにまたがるデータパイプラインのオーケストレーションでした。対応すべき核心的な問いは「データドメイン A は、データドメイン B の必要なデータセットがいつリフレッシュされ利用可能になったかを、どのように判断できるか」でした。
データメッシュアーキテクチャでは、ドメインがデータプロダクトの所有権を持ちつつ、他のドメインからの利用を可能にします。分散モデルでは、下流のパイプラインが実行を開始する前に上流のデータプロダクトの処理完了を待つ必要があり、複雑な依存関係の連鎖が生まれます。
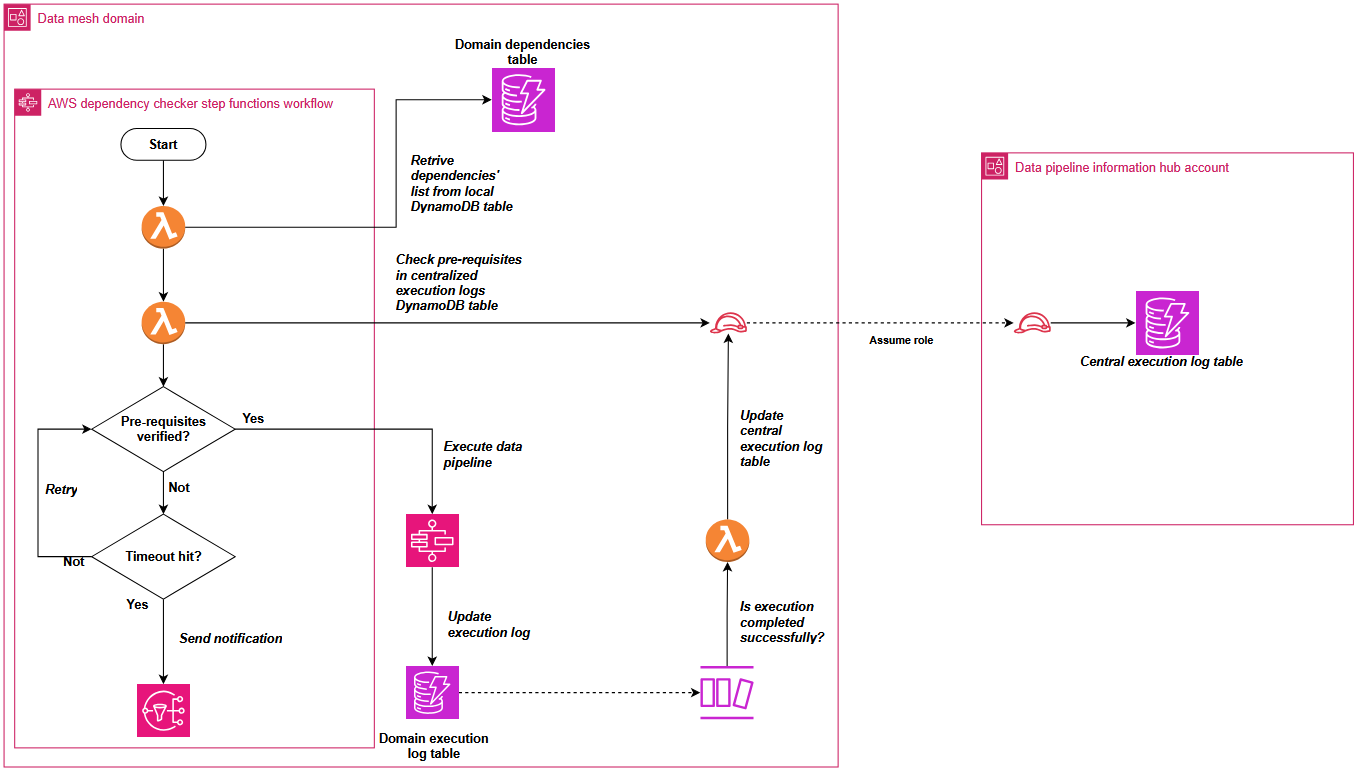
ドメイン間の依存関係調整に対処するため、Covestro は SDLF を拡張し、共有要素とドメイン固有要素を組み合わせて動作するカスタムの依存関係チェッカーコンポーネントを追加しました。
共有コンポーネントは、ハブ AWS アカウント内にある 2 つの中央 Amazon DynamoDB テーブルで構成されます。1 つは各ドメインからのパイプライン成功実行ログを収集し、もう 1 つはデータメッシュ全体のパイプライン依存関係を集約します。
各ドメインは、依存関係追跡用の Amazon DynamoDB テーブルと AWS Step Functions ステートマシンなど、ローカルコンポーネントをデプロイします。ステートマシンは中央の実行ログで前提条件をチェックし、追加設定なしで、SDLF でデプロイされるすべてのパイプラインの最初のステップとしてシームレスに統合されます。以下の図は、依存関係チェックのプロセスを示しています。
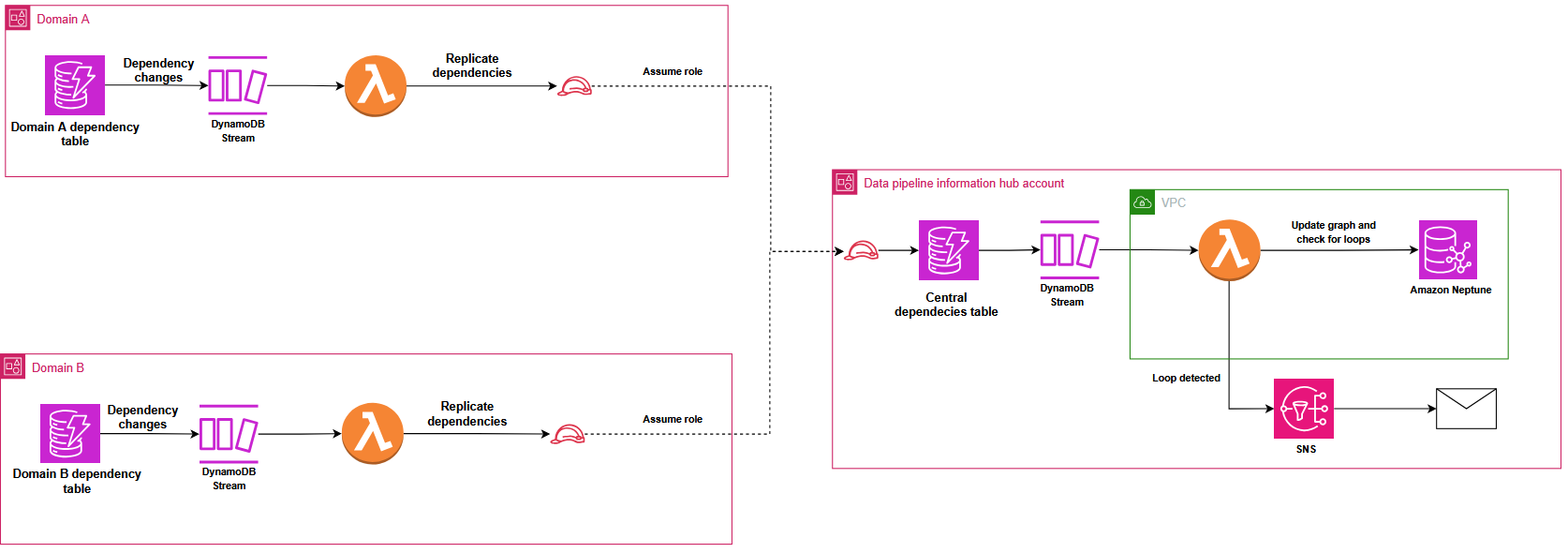
分散オーケストレーションシステムでロックを引き起こしかねない循環依存を防ぐため、Covestro は Amazon Neptune を使った高度な検出メカニズムを実装しました。DynamoDB Streams が各ドメインテーブルの依存関係変更を中央レジストリに自動的にレプリケートし、AWS Lambda 関数をトリガーします。Lambda 関数は Gremlin グラフトラバーサル言語 (pygremlin を使用) でパイプラインの関係を表す有向非巡回グラフ (DAG) を構築、更新、分析し、Gremlin のネイティブ関数で循環依存を検出して自動通知を送ります。以下の図のとおりです。データメッシュ全体のパイプライン依存関係の新規追加や変更を反映するため、グラフを継続的に更新します。
IaC による運用効率の向上
AWS CloudFormation と AWS Cloud Development Kit (AWS CDK) を使った IaC (Infrastructure as Code) のプラクティスにより、データメッシュ実装の運用効率が大きく向上します。インフラコードは GitHub リポジトリでバージョン管理されており、データエンジニアリングチームに完全なトレーサビリティと協働機能を提供します。専用のデプロイアカウントが AWS CodePipeline を使って、複数のデータメッシュドメインにわたり一貫したデプロイをオーケストレーションします。
中央集権型のデプロイモデルにより、インフラ変更は標準化された CI/CD (継続的インテグレーションとデプロイ) プロセスに従います。コードのコミットが自動化されたパイプラインをトリガーし、適切なドメインアカウントにインフラコンポーネントを検証、テスト、デプロイします。各データドメインは独自の AWS アカウントセット (dev、qa、prod) に存在し、中央デプロイパイプラインはドメイン境界を尊重しつつ、制御されたインフラプロビジョニングを可能にします。
IaC により、新しいドメインをオンボードする際にデータメッシュを横方向にスケールでき、環境全体で一貫したセキュリティ、ガバナンス、運用標準を維持できます。Covestro は実績のあるテンプレートで新しいドメインを素早くプロビジョニングし、業務チームへの価値提供までの時間を短縮しています。
ビジネスインパクトと技術的成果
Amazon DataZone と SDLF を使ったデータメッシュアーキテクチャの実装により、Covestro 組織全体に明確な効果が生まれました。
データパイプライン開発の加速
- 標準化されたブループリントにより、新しいデータプロダクトの市場投入までの時間を 70% 短縮
- 1,000 を超えるデータパイプラインを新アーキテクチャへ移行
- 手動コーディング不要の自動化されたパイプライン作成
- ドメインをまたいだ標準化されたアプローチと共有
データガバナンスと品質の強化
- 一貫した用語を支えるビジネス用語集の実装
- パイプラインに組み込まれた自動データ品質チェック
- ドメインをまたいだエンドツーエンドのデータリネージ可視化
- Apache Iceberg との統合による標準化されたメタデータ管理
データ発見とアクセスの改善
- Amazon DataZone によるセルフサービス型のデータ発見ポータル
- 適切なセキュリティ制御を備えた効率的なドメイン間データ共有
- 既存資産の可視性向上によるデータ重複の削減
- ドメイン間パイプライン依存関係の効率的な管理
運用効率
- ドメイン指向の所有権による中央データチームのボトルネック解消
- 自動化されたデプロイプロセスによる運用負荷の軽減
- 冗長なデータ処理の排除によるリソース利用効率の向上
- 監視とトラブルシューティング機能の強化
新しいインフラは、Covestro のチームがデータと関わる方法を根本から変えました。業務ドメインが自律的に運用できる一方で、品質とガバナンスについては企業全体の基準を守れるようになっています。現在のニーズと将来の成長の両方に対応する、より俊敏で効率的、協働的なデータエコシステムが生まれました。
今後の展望
Covestro のデータプラットフォームが進化を続けるなか、現在の注力点はドメインチームがドメインをまたいだ分析向けデータプロダクトを効果的に構築できるよう支援することです。並行して、Covestro は OpenLineage を活用した Amazon DataZone のデータリネージでデータ透明性を改善し、多様な処理ツールやフォーマットにまたがる、より広範なデータトレーサビリティを実現する取り組みを進めています。
まとめ
本記事では、Covestro が中央集権型のデータレイクからデータメッシュアーキテクチャへデータアーキテクチャを変革した経緯と、データ駆動型組織への変革を支える基盤としての重要性を紹介しました。Covestro の経験は、現代的なデータアーキテクチャを適切なツールとフレームワークで正しく実装すれば、ビジネス運営を変革し、新たなイノベーションの機会を引き出せることを示しています。
本実装は、セキュリティ、ガバナンス、スケーラビリティを保ちつつデータインフラをモダナイズしようとする他の企業にとってのブループリントとなります。慎重な計画と適切な技術選択により、制御性や品質を犠牲にすることなく、中央集権型から分散型のデータアーキテクチャへ移行できます。
Amazon DataZone の詳細は Getting Started ガイドを参照してください。SDLF については Deploy and manage a serverless data lake on the AWS Cloud by using infrastructure as code を参照してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Woosuk Choi がレビューしました。