Amazon Web Services ブログ
Oracle から Amazon Aurora PostgreSQL および Amazon S3 への大容量バイナリオブジェクト移行を効率化する Kafka ベースのソリューション
本記事は 2026 年 1 月 21 日 に公開された「Streamline large binary object migrations: A Kafka-based solution for Oracle to Amazon Aurora PostgreSQL and Amazon S3」を翻訳したものです。
オンプレミスの Oracle データベースを AWS に移行するお客様は、データの整合性とパフォーマンスを維持しながら、ラージオブジェクト (LOB) データ型をオブジェクトストレージに効率的に移行するという課題に直面しています。LOB が構造化データと一緒に保存される従来のエンタープライズデータベース設計では、ストレージ容量の制約、バックアップの複雑さ、データ取得・処理時のパフォーマンスボトルネックが発生します。画像、動画、その他の大容量ファイルを含む LOB は、従来のデータ移行において速度低下や LOB の切り捨て問題を引き起こすことがよくあります。数年にわたる長期間の移行では、LOB 移行の問題は特に深刻です。
本記事では、Amazon Managed Streaming for Apache Kafka (Amazon MSK)、Amazon Aurora PostgreSQL-Compatible Edition、Amazon MSK Connect を使用したスケーラブルなソリューションを紹介します。データストリーミングにより、変更が継続的に送受信されるデータレプリケーションが可能になり、ターゲットデータベースはリアルタイムで変更にアクセスして適用できます。このソリューションは、insert、update、delete などのデータベース操作に対してイベントを生成し、AWS Lambda 関数をトリガーして、ソース Oracle データベースから LOB をダウンロードし、Amazon Simple Storage Service (Amazon S3) バケットにアップロードします。同時に、ストリーミングイベントは Oracle データベースからターゲットデータベースに構造化データを移行し、対応する LOB との適切なリンクを維持します。
完全な実装は GitHub で公開されており、AWS Cloud Development Kit (AWS CDK) のデプロイコード、設定ファイル、セットアップ手順が含まれています。
ソリューションの概要
従来の Oracle データベース移行は構造化データを効果的に処理できますが、画像、動画、ドキュメントを含む LOB の処理には苦労します。サイズ制限や切り捨ての問題により移行が失敗することが多く、データ損失、ダウンタイムの延長、プロジェクトの遅延など、クラウド変革の取り組みを遅らせる重大なビジネスリスクが生じます。数年にわたる長期間の移行では、運用の継続性を維持することが重要であり、問題はより深刻になります。このソリューションは LOB 移行の主要な課題に対処し、パフォーマンスや信頼性を損なうことなく、継続的な長期運用を可能にします。
従来の移行技術に関連するサイズ制限を取り除くことで、プロセス全体を通じてデータの整合性を維持しながら LOB をシームレスに移行できます。
このアプローチでは、Oracle LOB 移行の従来の制約を軽減するために、モダンなストリーミングアーキテクチャを使用します。主なコンポーネントは以下のとおりです。
- Amazon MSK – ストリーミングインフラストラクチャを提供します。
- Amazon MSK Connect – 2 つのコネクタを使用します。
- Debezium Connector for Oracle をソースコネクタとして使用し、Oracle データベースで発生する行レベルの変更をキャプチャします。コネクタは変更イベントを発行し、Kafka ソーストピックにパブリッシュします。
- Debezium Connector for JDBC をシンクコネクタとして使用し、Kafka ソーストピックからイベントを消費し、JDBC ドライバーを使用して Aurora PostgreSQL-Compatible にイベントを書き込みます。
- Lambda 関数 – Amazon MSK へのイベントソースマッピングによってトリガーされます。関数は Kafka ソーストピックからのイベントを処理し、各イベントペイロードから Oracle 行のプライマリキーを抽出します。このキーを使用してソース Oracle データベースから対応する BLOB データをダウンロードし、Amazon S3 にアップロードします。ファイルはプライマリキーフォルダごとに整理され、リレーショナルデータベースレコードとの簡単なリンクを維持します。
- Amazon RDS for Oracle – Amazon Relational Database Service (Amazon RDS) for Oracle をソースデータベースとして使用し、オンプレミスの Oracle データベースをシミュレートします。
- Aurora PostgreSQL-Compatible – 移行データのターゲットデータベースとして使用します。
- Amazon S3 – ソースデータベースからの BLOB データを保存するオブジェクトストレージとして使用します。
次の図は、Oracle LOB データ移行アーキテクチャソリューションを示しています。
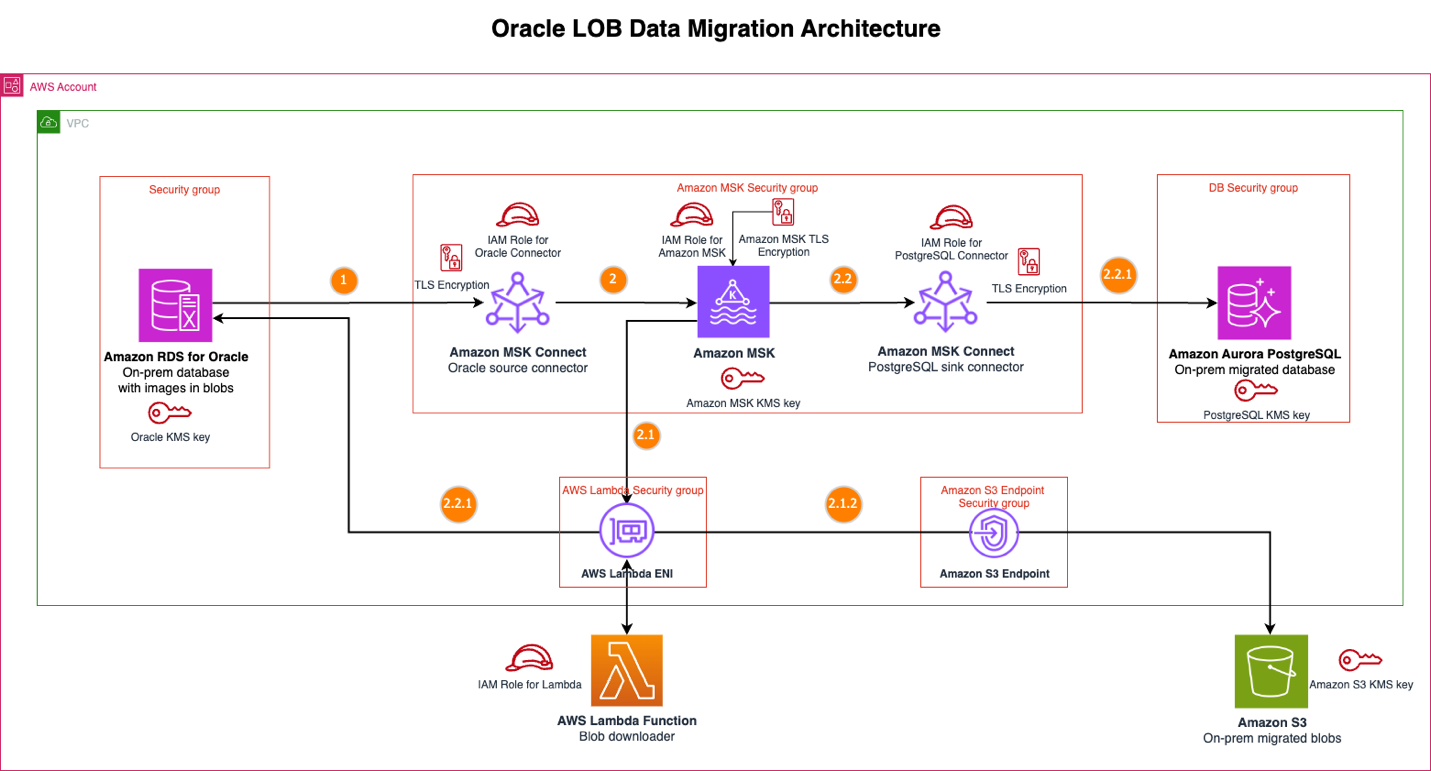
メッセージフロー
ソース Amazon RDS for Oracle データベースでデータ変更が発生すると、ソリューションは以下のシーケンスを実行します。イベントの検出とパブリッシュ、Lambda による BLOB 処理、構造化データ処理の順に進みます。
- Oracle ソースコネクタは、BLOB データ列への変更を含む変更データキャプチャ (CDC) イベントをキャプチャします。このコネクタは、Kafka ペイロードを最適化するために BLOB データ列を Kafka イベントから除外するように設定されています。
- コネクタはこのイベントを MSK トピックにパブリッシュします。
- MSK イベントは CDC イベントに対して BLOB Downloader Lambda 関数をトリガーします。
- Lambda 関数は 2 つの主要な条件を検査します。Debezium イベントコード (特に create (c) または update (u) をチェック) と、設定された Oracle BLOB テーブル名とその列名のリストです。Kafka メッセージが設定されたテーブルリストと有効な Debezium イベントの両方に一致する場合、Lambda 関数はプライマリキーとテーブル名を使用して Oracle ソースから BLOB データのダウンロードを開始します。一致しない場合、関数は BLOB ダウンロードプロセスをバイパスします。この選択的なアプローチにより、Lambda 関数は BLOB データを含むテーブルの Kafka メッセージを処理する場合にのみ SQL クエリを実行し、データベースとのやり取りを最適化します。
- Lambda 関数は BLOB を Amazon S3 にアップロードし、プライマリキーフォルダごとに一意のオブジェクト名で整理します。これにより、構造化データベースレコードと Amazon S3 内の対応する BLOB データ間のリンクが可能になります。
- PostgreSQL シンクコネクタは MSK トピックからイベントを受信します。
- コネクタは、BLOB データ列を除く Oracle データベースの変更を Aurora PostgreSQL データベースに適用します。BLOB データ列は Oracle ソースコネクタによって除外されています。
- MSK イベントは CDC イベントに対して BLOB Downloader Lambda 関数をトリガーします。
主なメリット
このソリューションには以下の主要な利点があります。
- コスト最適化とライセンス – このアプローチは、データベース全体のサイズを削減し、従来のデータベースやレプリケーション技術に関連する高額なライセンスの必要性を軽減することで、大幅なコスト最適化のメリットを提供します。LOB ストレージをデータベースから切り離し、Amazon S3 を使用することで、データベース全体のフットプリントを削減し、従来のライセンスやレプリケーション技術に関連するコストを削減できます。ストリーミングアーキテクチャは、長期間の移行中のインフラストラクチャオーバーヘッドも最小限に抑えます。
- サイズ制約と移行失敗の回避 – 従来の移行ツールは LOB 転送にサイズ制限を課すことが多く、切り捨ての問題や移行の失敗につながります。ストリーミングアーキテクチャはサイズ制限の制約を完全に取り除き、データの整合性を維持しながらさまざまなサイズの LOB を移行できます。イベント駆動型アーキテクチャにより、ほぼリアルタイムのデータレプリケーションが可能になり、移行中もソースシステムを稼働させ続けられます。
- ビジネス継続性と運用効率 – 変更はターゲット環境に継続的に流れ、ビジネス継続性を実現します。Amazon S3 でのプライマリキーベースの整理により、構造化データベースレコードと対応する LOB 間の関係を維持し、参照整合性を確保しながら、大容量ファイルに対するオブジェクトストレージの柔軟性を提供します。
- アーキテクチャ上の利点 – LOB を Amazon S3 に保存し、構造化データを Aurora PostgreSQL-Compatible に維持することで、明確な分離が実現します。バックアップとリカバリ操作が簡素化され、構造化データに対するクエリパフォーマンスが向上し、Amazon S3 を通じてバイナリオブジェクトへの柔軟なアクセスパターンが提供されます。
実装のベストプラクティス
このソリューションを実装する際は、以下のベストプラクティスを考慮してください。
- 小規模から始めて段階的にスケール – このソリューションを実装するには、本番環境以外のデータを使用したパイロットプロジェクトから始めて、本格的な移行にコミットする前にアプローチを検証してください。これにより、本番システムに影響を与えることなく、制御された環境で問題を解決し、設定を調整できます。
- モニタリング – Amazon CloudWatch を通じて十分なモニタリングを設定し、Kafka ラグ、Lambda 関数エラー、レプリケーションレイテンシーなどの主要なメトリクスを追跡します。移行タイムラインに影響を与える前に問題を迅速に検出して解決できるよう、早期にアラートしきい値を設定してください。予想される CDC ボリュームに基づいて MSK クラスターのサイズを設定し、初期データ同期中のピーク負荷を処理するために Lambda の予約済み同時実行数を設定します。
- セキュリティ – セキュリティについては、構造化データと LOB の両方で転送中および保存時の暗号化を使用し、MSK クラスター、Lambda 関数、S3 バケット、データベースインスタンスの AWS Identity and Access Management (IAM) ロールとポリシーを設定する際は最小権限の原則に従ってください。Oracle と Aurora PostgreSQL-Compatible 間のスキーママッピングを文書化し、データベースレコードと Amazon S3 内の対応する LOB のリンク方法も含めてください。
- テストと準備 – 本番稼働前に、フェイルオーバーとリカバリ手順を徹底的にテストしてください。Lambda 関数の障害、MSK クラスターの問題、ネットワーク接続の問題などのシナリオを検証し、潜在的な問題に備えてください。最後に、このストリーミングアーキテクチャはソースシステムとターゲットシステム間の結果整合性を維持するため、高ボリューム期間中に短いラグタイムが発生する可能性があることを覚えておいてください。これを念頭に置いてカットオーバー戦略を計画してください。
制限事項と考慮事項
LOB を含む Oracle データベースを AWS に移行するための信頼性の高いアプローチですが、実装前に理解しておくべきいくつかの固有の制約があります。
このソリューションには、ソース Oracle データベースと AWS 環境間のネットワーク接続が必要です。オンプレミスの Oracle データベースの場合、デプロイ前に AWS Direct Connect または VPN 接続を確立する必要があります。ネットワーク帯域幅はレプリケーション速度と全体的な移行パフォーマンスに直接影響するため、接続は予想される CDC イベントと LOB 転送のボリュームを処理できる必要があります。
このソリューションは、ソースコネクタとして Debezium Connector for Oracle を、シンクコネクタとして Debezium Connector for JDBC を使用します。このアーキテクチャは、Oracle から PostgreSQL への移行専用に設計されています。他のデータベースの組み合わせには、異なるコネクタ設定が必要であるか、現在の実装ではサポートされていない可能性があります。移行スループットは、MSK クラスターの容量と Lambda の同時実行制限によっても制約されます。大規模な移行では AWS サービスクォータを超える可能性があり、AWS Enterprise Support を通じてクォータの引き上げをリクエストする必要がある場合があります。
まとめ
本記事では、LOB ストレージを構造化データから分離するストリーミングアーキテクチャを使用して、Oracle から AWS への大容量バイナリオブジェクトの移行という重要な課題に対処するソリューションを紹介しました。このアプローチは、サイズ制約を回避し、Oracle ライセンスコストを削減し、長期間の移行期間を通じてデータの整合性を維持します。
Oracle 移行戦略を変革する準備はできましたか?GitHub リポジトリにアクセスしてください。完全な AWS CDK デプロイコード、設定ファイル、開始するためのステップバイステップの手順が用意されています。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。