Amazon Web Services ブログ
次世代の Amazon OpenSearch Serverless: エージェント向けにゼロから構築
本記事は 2026 年 5 月 28 日 に公開された「The next generation of Amazon OpenSearch Serverless: Built from the ground up for agents」を翻訳したものです。
対象読者向けの注記: 本記事は技術的な詳細を掘り下げたローンチ記事です。変更点とその理由を簡潔にまとめた概要は、関連する AWS News Blog の記事をご覧ください。
本日、Amazon OpenSearch Serverless のアーキテクチャをゼロから刷新したことを発表します。新しいアーキテクチャでは、オートスケーリングが従来比で最大 20 倍に高速化し、コンピューティングをゼロまでスケールできるようになりました。ピーク負荷に合わせてクラスターをプロビジョニングする場合と比べてコストは最大 60% 削減できます。Amazon OpenSearch Service は、ベクトル、レキシカル、ハイブリッド、エージェント検索を統合したフルマネージドのオープンソース検索エンジンで、低レイテンシーかつ正確で関連性の高い結果を提供します。Amazon OpenSearch Serverless は、その自動スケーリング型のデプロイオプションです。
最近のワークロードはますます動的で予測しにくくなっています。E コマースプラットフォームでは、フラッシュセール時にトラフィックが 10 倍に急増します。人工知能 (AI) エージェントは、複数ステップのタスクを推論する過程で数百もの同時ベクトルクエリをトリガーし、その後アイドル状態になります。マルチテナント SaaS アプリケーションでは、活動パターンが大きく異なる数十のテナントを処理します。こうしたワークロードには、需要に合わせてスケールアップし、需要が下がればリソースを解放できるインフラが必要です。
そこで、Amazon OpenSearch Serverless のアーキテクチャをゼロから再構築しました。新しいアーキテクチャでは、コンピューティングとストレージを分離しています。インフラのプロビジョニングは分単位ではなく秒単位で完了し、アプリケーションがアイドル状態のときにはコンピューティングをゼロまでスケールダウンします。本記事では、新しいアーキテクチャの内容、アプリケーションへの影響、ハンズオンチュートリアルでの使い始め方を解説します。
--generation NEXTGEN を指定します。Classic アーキテクチャを引き続き使用する場合は、CLI で --generation CLASSIC を指定するか、オプションの --generation パラメータを省略します。
アプリケーションへの影響
新しいアーキテクチャは、パフォーマンス、コスト、シンプルなユーザー体験という 3 つの柱で改善をもたらします。
パフォーマンス: 秒単位のオートスケーリング
OpenSearch Compute Unit (OCU) は、インデックス作成と検索のワークロードを支えるコンピューティング容量の単位です。Amazon OpenSearch Serverless は、追加の OCU を秒単位でプロビジョニングできるようになりました。トラフィックが到着したときには、ワーカーがすでに高負荷に陥ってから対応するのではなく、需要に合わせて事前にリソースを追加します。同じ仕組みで、トラフィックが下がるとインフラを素早くスケールダウンします。新しいアーキテクチャは、容量のスケール速度が以前のアーキテクチャの 最大 20 倍 に達するため、トラフィックの急増時にも一貫したパフォーマンスをユーザーに提供でき、容量が不要になれば支払いも止まります。
コスト効率: 使った分だけ支払う
インデックス作成、検索、ストレージ、ベクトルインデックスの GPU アクセラレーションは、それぞれ独立して計測・課金されるため、ワークロードの各次元を個別に把握し、最適化できます。
コンピューティングとストレージの分離: OpenSearch Serverless ではコンピューティングとストレージが完全に分離されており、コレクションに保存されているデータ量とは無関係に OCU をスケールアップ・スケールダウンできます。これは、インデックス作成 OCU と検索 OCU の両方からアクセスできる新しいストレージ層によって実現されています。複数のインデックスにデータを格納していても、データのインデックス作成や検索を実際に行っていなければ、コンピューティングコストは発生しません。アイドル時間が長いワークロードでは、ピーク容量に合わせて OpenSearch Service ドメインをプロビジョニングする場合と比べて、新しいアーキテクチャによりインフラコストを最大 60% 削減できます。
ゼロまでのスケール: アイドルタイムアウト期間 (10 分) の間にリクエストが到着しないと、サービスはコンピューティングリソースを解放し、OCU の使用量はゼロまでスケールダウンします。トラフィックが再開すると、約 10 秒で容量が復活します。スケールダウン中も、サービスは到着したリクエストをキューに入れ、容量が利用可能になり次第処理するため、リクエストを破棄することはありません。スケジュールされたバッチジョブやマーケティングキャンペーンの前など、トラフィックの急増が予想される場合は、本番トラフィックを送信する前に軽量なクエリ (例: size=1 の match_all) を送信してコレクションをウォームアップしておけます。これにより、最初の実リクエストでユーザーが体感するレイテンシーを抑えられます。インデックス作成と検索は独立してスケールします。検索リクエストがなければ、検索 OCU はゼロまでスケールしますが、インデックス作成リクエストがあれば OpenSearch Serverless はインデックス作成 OCU を維持します。逆向きでも同じです。
シンプルな体験: 本番環境までのステップ削減
OpenSearch Serverless を日々運用する体験もシンプルになりました。
新しいアーキテクチャでは、コレクションをプロビジョニングして数秒でリクエストを送信し始められます。容量計画もサイジングの判断もインフラのウォームアップ待ちも不要です。これにより、AI エージェントがオンデマンドでベクトル検索や検索ステップを起動し、遅延なくレスポンスを期待できる、エージェントワークロードに Amazon OpenSearch Serverless が自然と適合します。
使い始めをさらに高速化するため、コンソールに Express Create を導入しました。コレクション名とコレクションタイプを指定し、Express Create を選ぶと、ネットワーク、暗号化、アクセスポリシーの事前設定なしで、コレクションが数秒でアクティブになります。ワークロードに必要であれば、後から追加できます。
コレクショングループとコレクションは、AWS Command Line Interface (AWS CLI) や AWS SDK を使ってプログラムから作成することもできます。AWS CloudFormation のサポートも近日提供予定です。
新しいアーキテクチャでは、on.aws ドメイン上に 2 つのエンドポイント形式が導入されました。コレクション単位のエンドポイント (<collectionId>.aoss.<region>.on.aws) は、コレクション 1 つにつきエンドポイント 1 つという、これまでと同じ動作です。アカウント単位のリージョナルエンドポイント (<accountId>.aoss.<region>.on.aws) は新しく、1 つのホスト名で全コレクションを処理し、対象のコレクションは各リクエストで x-amz-aoss-collection-name または x-amz-aoss-collection-id ヘッダーで指定します。コレクション数に関係なく、コネクションプール 1 つ、Transport Layer Security (TLS) セッション 1 つ、管理するエンドポイント 1 つで済みます。テナントごとに独自のコレクションを割り当てるマルチテナントワークロードでは、大きな改善になります。両方のエンドポイントは標準の AWS PrivateLink を使用するため、他の AWS サービスと同様に、VPC コンソールや EC2 API から Virtual Private Cloud (VPC) エンドポイントを作成できます。Private Domain Name System (DNS) は自動で構成されるため、元のアーキテクチャで必要だった Amazon Route 53 プライベートホストゾーン、転送ルール、カスタム DNS インフラが不要になります。クロス VPC、クロスアカウント、オンプレミスからのアクセスは、追加のセットアップなしに標準の vpce-* DNS 名で動作します。
コレクショングループは、コレクションを整理する新しい単位です。コレクショングループ を使うと、複数のコレクション間でコンピューティング容量を共有でき、トラフィックパターンが補完的な小規模コレクションのコストを削減できます。同じグループ内のコレクションに異なる AWS Key Management Service (AWS KMS) キーを割り当てることもでき、コスト効率とコレクション単位の暗号化分離の両方を得られます。新しいアーキテクチャでコレクションを作成する場合、コレクショングループは必須です。
バージョンとアップグレードを管理する手間なく、OpenSearch オープンソースリリースの利点も得られます。サービスはアップストリームのリリースを自動的に追跡します。
Amazon OpenSearch Serverless は Vercel Marketplace でも利用可能になっており、開発者は Vercel プロジェクトから検索インフラを直接追加できます。委任アクセスを通じて既存の AWS アカウントをリンクするか、AWS が初めての場合は USD $100 の AWS クレジット付きの Limited Scope Account を通じて使い始められます。
この統合では、適切なデフォルト、ゼロまでのスケール課金、パブリックエンドポイント、AWS マネージド暗号化を備えたコレクションが作成され、接続情報が Vercel プロジェクトの環境変数として自動的に設定されます。フルテキスト検索でも、セマンティックや AI を活用した検索でも、ユースケースに応じて Search または Vector Search のコレクションタイプを選べます。
アーキテクチャの仕組み
新しい Amazon OpenSearch Serverless アーキテクチャは、コンピューティングとストレージを完全に分離します。OCU はステートレスで、インデックス作成 OCU と検索 OCU の両方からアクセス可能な分散共有ストレージ層から読み書きします。ストレージ層は高い耐久性を念頭に設計されており、データを処理するコンピューティングノードとは独立してデータを利用可能に保ちます。
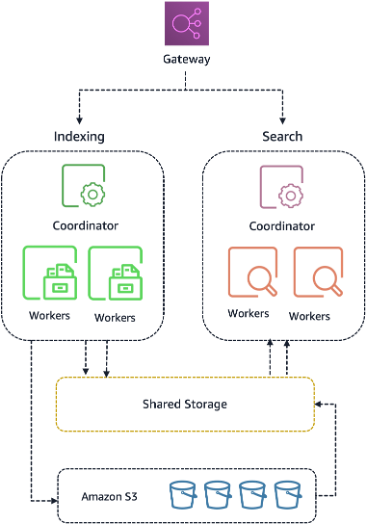
この設計は、実用上 2 つの効果をもたらします。
- 高速なプロビジョニング。 ブートストラップするローカルディスクがないため、新しい OCU は数秒でリクエストの処理を開始します。OCU は共有ストレージ層をマウントし、すぐに処理を開始します。
- 効率的なスケールダウン。 データが OCU 上に存在したことがないため、保存されたデータに影響を与えずにアイドル容量を解放できます。トラフィックが下がるとコンピューティングリソースが解放され、それに応じてコストも下がります。
アーキテクチャの比較
次の表で、元のアーキテクチャと新しいアーキテクチャの主な違いをまとめます。
| 機能 | Classic アーキテクチャ | NextGen アーキテクチャ |
| 最小容量 | 2 OCU (常時稼働) | 0 OCU (ゼロまでのスケール) |
| スケーリング速度 | 分単位 | 秒単位 |
| ストレージ | コンピューティングノードごとのローカルストレージ | 分散共有ストレージ (分離) |
| コレクションの整理 |
個別コレクション (デフォルト) コレクショングループ (オプション) |
コレクショングループ (必須) |
| ゼロからのコールドスタート | 該当なし (常時稼働) | 約 10 秒 |
| エンドポイント | コレクション単位のエンドポイント | リージョナルエンドポイント (アカウントごとに静的) |
| OpenSearch Service ドメインに対するコスト | ベースライン | 最大 60% 低コスト |
| スケーリング速度 (Classic 比) | ベースライン | ベースラインの最大 20 倍 |
ウォークスルー: ベクトルコレクションの作成とゼロまでのスケールの観察
このウォークスルーでは、Express Create でベクトル検索コレクションを作成し、埋め込みを持ついくつかのサンプルドキュメントをインデックスし、k-nearest neighbor (k-NN) クエリを実行し、Amazon CloudWatch でコレクションがゼロまでスケールする様子を観察します。全体で約 10 分かかります。
前提条件
- Amazon OpenSearch Serverless コレクションを作成する権限を持つ AWS アカウント。
- 適切な認証情報で構成された AWS Command Line Interface (AWS CLI)。
- curl 7.75 以降 (組み込みの
--aws-sigv4サポート用)。
ステップ 1: セキュリティポリシーを構成する
暗号化、ネットワーク、データアクセスポリシーを作成します。コレクションを作成する前にこれらが存在している必要があります。
注: AWS コンソールの Express Create ワークフローを使用すると、これらのポリシーは自動的に作成されます。
重要: データアクセスポリシーを作成した後、コレクションへの API 呼び出しを行う前に、ポリシーが伝播するまで約 30〜60 秒待ちます。403 Forbidden エラーが発生した場合は、待ってから再試行してください。
ステップ 2: コレクショングループとコレクションを作成する
ゼロまでのスケール容量制限を持つコレクショングループを作成し、その中にベクトル検索コレクションを作成します。
コレクションのステータスは数秒で ACTIVE に遷移します。
ステップ 3: ベクトルインデックスを作成する
コレクションエンドポイントを取得し、3 次元ベクトルを使った k-NN インデックスを作成します。
注: コレクションがゼロまでスケールしている場合、容量がスケールアップする間、最初のリクエストには数秒かかる可能性があります。リクエストがタイムアウトした場合は、10〜15 秒待ってから再試行してください。
ステップ 4: 埋め込みを持つサンプルドキュメントをインデックスする
ステップ 5: k-NN クエリを実行する
クエリベクトルに最も近い 2 つの近傍を検索します。クエリを実行する前に、ベクトルインデックスのビルドのため、インデックス作成後 30 秒待ちます。
レスポンスでは、最も類似する 2 つのアイテム、つまりクエリベクトルに最も近い埋め込みを持つヘッドフォンのドキュメントが返されます。
このクエリは OpenSearch UI でも実行できます。Amazon OpenSearch Service コンソールでコレクションに移動し、OpenSearch UI Application URL を選択します。次に こちらのブログ の手順に従ってワークスペースを作成します。その後、Dev Tools に移動して、次のクエリを貼り付けて実行します。
ステップ 6: ゼロまでのスケールを観察する
一定期間活動がない (インデックス作成や検索のトラフィックがない) と、コレクショングループは 0 OCU までスケールダウンします。次のコマンドで確認します。
レスポンスで、コレクションがスケールダウンした後、currentCapacity.search.capacityInOcu と currentCapacity.indexing.capacityInOcu が 0 と表示されます。
Amazon OpenSearch Service コンソールの コレクショングループ ページに移動することもできます。コレクショングループを選択し、モニタリング セクションまでスクロールします。インデックス作成容量 (OCU) と 検索容量 (OCU) という 2 つのチャートを確認できます。10 分間アイドル状態 (インデックス作成や検索リクエストがない状態) が続くと、両方のメトリクスがゼロまで下がり、サービスがコレクションのコンピューティングリソースをすべて解放したことが確認できます。
クリーンアップ
継続的な課金を避けるため、このウォークスルーで作成したリソースは終わったら削除します。最初にコレクションを削除してコレクショングループを空にし、次にグループを削除し、最後にセキュリティポリシーとアクセスポリシーを削除します。
既存のコレクションのアップグレード
新しいアーキテクチャに移行するには、新しいコレクショングループとコレクションを作成し、データを再インデックスします。再インデックスの手順は Amazon OpenSearch Ingestion を使った Amazon OpenSearch Serverless での再インデックスの実行 に詳しく解説しています。クエリとインデックスマッピングは同じままで、変わるのはコレクションエンドポイントだけです。新しい静的リージョナルエンドポイントなら、これは 1 回限りの更新で済みます。
新しいアーキテクチャは SEARCH と VECTORSEARCH のコレクションタイプをサポートします。TIMESERIES はローンチ時にはサポートされません。
まとめ
新しい Amazon OpenSearch Serverless アーキテクチャは本日から利用可能です。Express Create を使えば最初の OpenSearch Serverless コレクションを数秒で作成し、本番トラフィックに対応するようスケールでき、アイドル状態になれば OpenSearch Serverless のコンピューティングコストはゼロまで下がります。
詳細は次を参照してください。
質問やフィードバックがあれば、サポートケースを開くか、AWS アカウントチームを通じて連絡してください。皆さんが構築するものを楽しみにしています。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Takayuki Enomoto がレビューしました。